论文阅读Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
Posted 桥本环奈粤港澳分奈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network相关的知识,希望对你有一定的参考价值。
目录

一、简介
研究了使用依赖信息来匹配回复和它的多回合上下文,以两种方式扩展了Transformer的注意机制:
(1)使用堆叠的自注意来获取多粒度的语义表示。
(2)利用交叉注意对依赖信息进行匹配。
二、方法
1. 任务: 多轮对话回复选择
给定对话数据集 D = { ( c , r , y ) Z } Z = 1 N D = \\{(c, r, y)Z\\}_{Z=1}^{N} D={(c,r,y)Z}Z=1N
其中 c = { u 0 , … , u n − 1 } c = \\{u0,…, un−1\\} c={u0,…,un−1}表示会话上下文,其中 { u i } n − 1 i = 0 \\{ui\\}_{n−1}^{i=0} {ui}n−1i=0作为话语,r 作为回复候选。 y ∈ { 0 , 1 } y∈\\{0,1\\} y∈{0,1}是一个二进制标签,表示r是否是c的合适回复。
目标: 学习一个与D匹配的模型g(c, r),它可以度量任何上下文c与候选回复r之间的相关性。
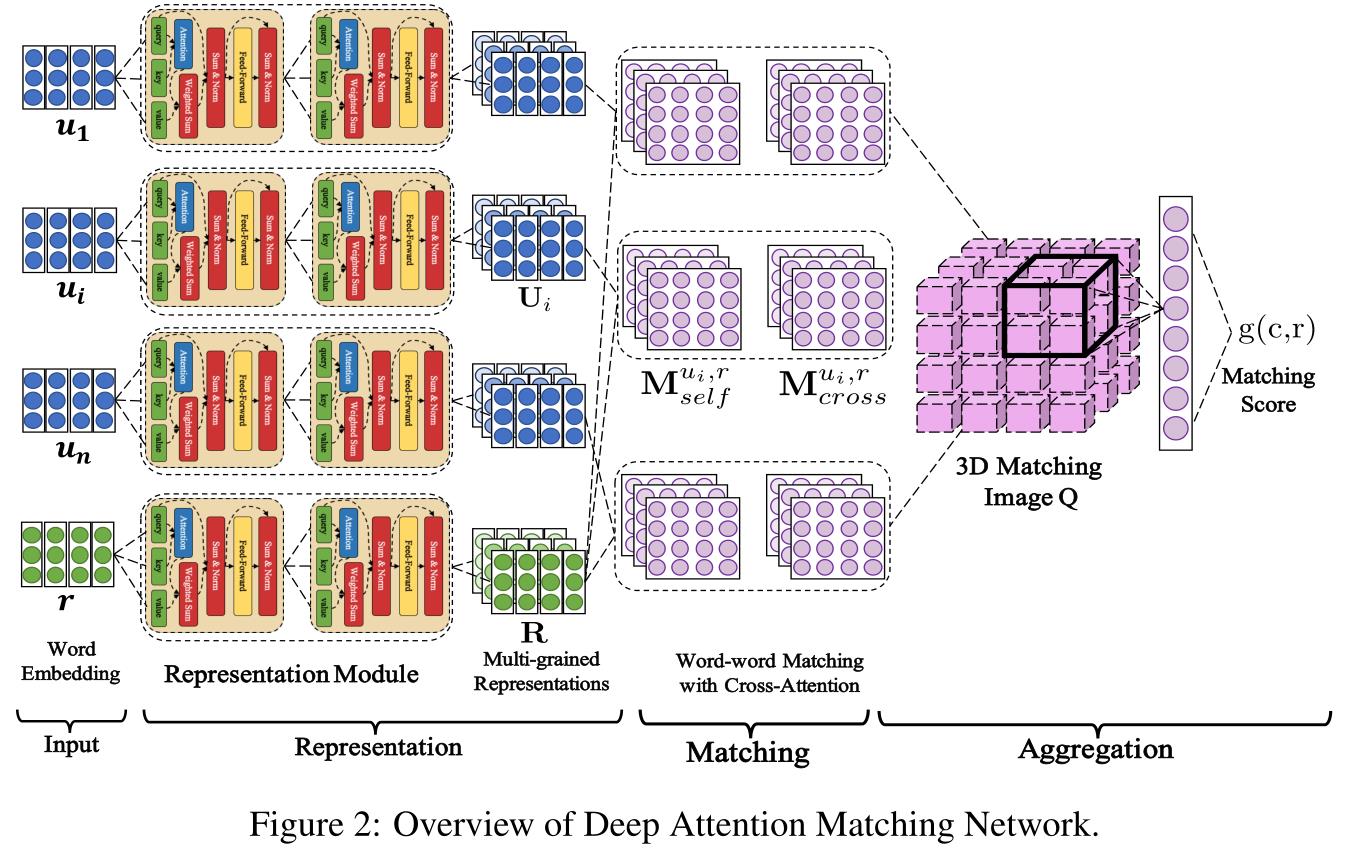
2. 模型架构
DAM,(主要基于Transformer)使用representation-matching-aggregation架构来匹配回复和多轮上下文:
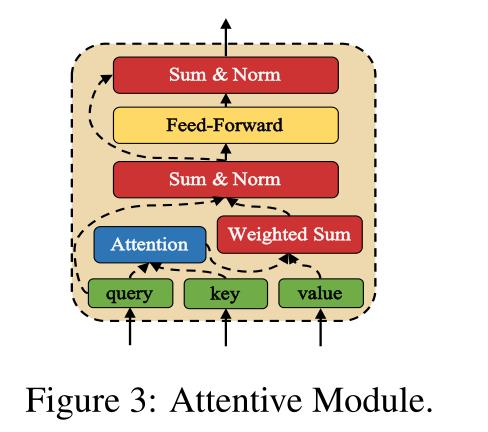
attention 模块
和transformer相似,attention 模块有三个输入句:query sentence,key sentence,value sentence:
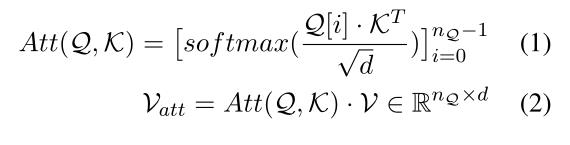
其中Q[i]是query sentence,Q 中的第i个embedding,
V
a
t
t
[
i
]
V_{att_[i]}
Vatt[i]是
a
t
t
[
i
]
att_[i]
att[i]的第i行,存储是value sentence中可能与query sentence中第i个单词有依赖关系的单词的融合语义信息。对于每个i,
V
a
t
t
[
i
]
V_{att_[i]}
Vatt[i]和Q[i]被加在一起,将它们组合成一个包含它们联合意义的新表示。
然后应用图层归一化,防止梯度消失或爆炸。对归一化结果应用具有RELU 激活的前馈网络FFN,进一步处理融合的嵌入:
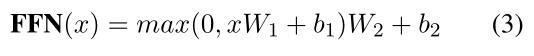
x是query sentence,Q形状相同的一个二维张量,FFN(x)是一个与x形状相同的二维张量,然后将FFN(x)残加到x中,融合结果归一化为最终输出。
整个注意模块可以捕获跨query sentence和key sentence的依赖关系,并进一步使用依赖关系信息将查询句中的元素和值句复合成复合表示。我们利用细心模块的这个属性来构造多粒度语义表示,并与依赖项信息匹配。
Representation:
输入词向量embedding,对话历史以句子为单位, 与response一起通过L个Attentive Module, L个相同的自关注层被分层堆叠,每个第L个自关注层将第L - 1层的输出作为其输入,并将输入的语义向量组合成更复杂的基于自我注意的多粒度表示。通过这种方式,每个utterance和response都逐渐构造出
u
i
u_{i}
ui和r的多粒度表示(L个矩阵 ,
[
U
i
l
]
l
=
0
L
[U_{i}^{l}]_{l=0}^{L}
[Uil]l=0L 和
[
R
l
]
l
=
0
L
[R^{l}]_{l=0}^{L}
[Rl]l=0L )。

l l l的取值范围为0 ~ l − 1 l−1 l−1,表示粒度的不同。通过这种方式,每个话语或反应中的单词重复地作用在一起,合成越来越整体的表征。
Matching:
DAM使用 self-attention 和 cross-attention 来提取 response 和 context 的特征。在每一级粒度 l l l上构造两种段-段匹配矩阵,即自注意力匹配矩阵 M s e l f u i , r , l M_{self}^{u_i, r, l} Mselfui,r,l 、交叉注意力匹配矩阵 M c r o s s u i , r , l M_{cross}^{u_i, r, l} Mcrossui,r,l
自注意矩阵:
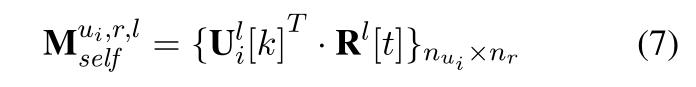
交叉注意矩阵:

Aggregation:
经过深层匹配后,把所有话语和回复的匹配聚合成类似3D图像Q,有三个维度(utterance、utterance中的每个词、response中的每个词)
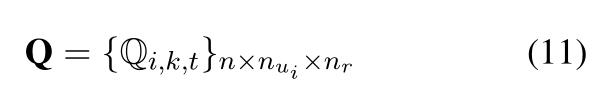
每个像素点
Q
i
,
k
,
t
Q_{i, k, t}
Qi,k,t为:
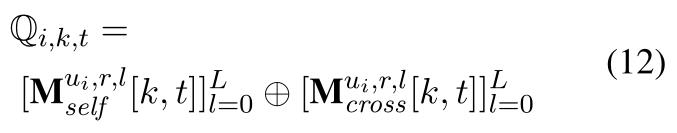
⊕为拼接运算,每个像素有2(L + 1)个通道,存储不同粒度的某一段对之间的匹配度。
通过对最大池化操作进行卷积,提取多回合上下文片段对与候选响应之间的重要匹配信息,并通过单层感知器融合为一个匹配得分,表示候选响应与整个上下文的匹配程度。
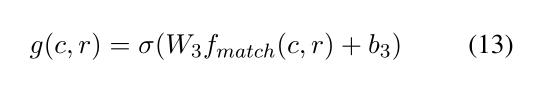
损失函数为:
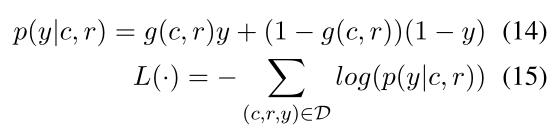
三、实验
1. 数据集
1、Ubuntu对话语料库,是最大的公共多轮对话语料库,包含了特定领域的大约一百万次对话。
2、DouBan对话语料库,中文开放域对话语料库,包含50万个多回合上下文,每个上下文都有一个由人类产生的积极反应和一个随机抽样的消极反应。
2. 评价指标
-
Rn@k,n选k的召回率
-
MAP ,Mean Average Precision,平均准确率。单个对话的平均准确率是检索出目标回复后的准确率的平均值。对话系统的平均准确率是每个对话的平均准确率的平均值。MAP 是反映系统在全部相关回复上性能的单值指标。系统检索出来的相关回复越靠前(rank 越高),MAP就可能越高。如果系统没有返回相关回复,则准确率默认为0。
例如,假设有两个对话,对话1有4个相关回复,对话2有5个相关回复。某系统对于对话1检索出4个相关回复,其rank分别为1, 2, 4, 7;对于对话2检索出3个相关回复,其rank分别为1,3,5。对于对话1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于对话2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。
-
MRR ,Mean Reciprocal Rank,把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。
-
P@1,Precision-at-one
3. 实验设置
-
最多考虑9个回合和每条话语(回复)50个单词,用word2vec 预先训练word embedding
-
使用zero-pad来处理可变大小的输入,FFN中的参数规格设为200,与ord embedding大小相同。
-
我们测试了1-7个自我注意层,展示了在验证集上获得最好结果的情况(5个自注意层)。
-
使用adam优化器调整DAM和其他消融模型,学习率初始化为1e-3,并在训练过程中逐渐降低,batch-size为256
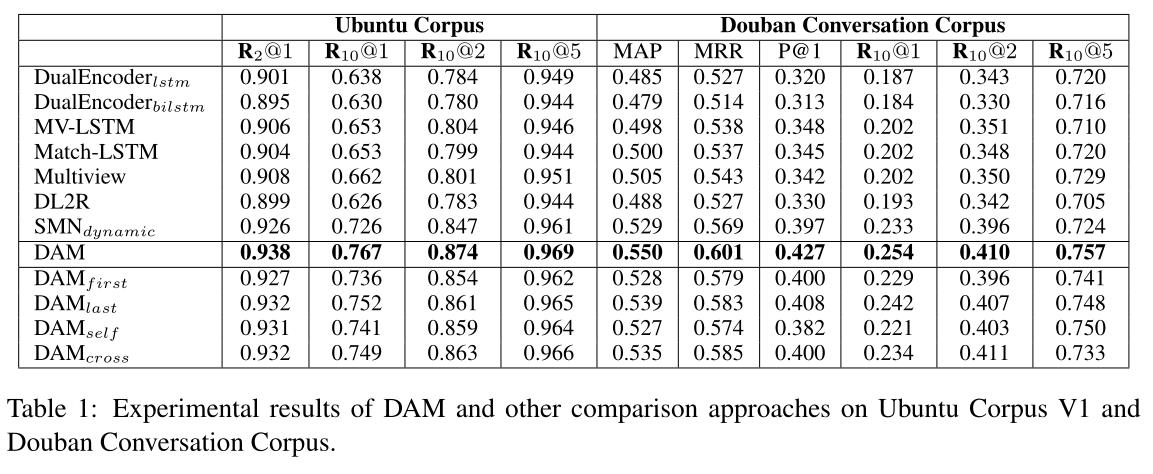
4. 实验结果
四、结果分析
1. 实验结果分析
DAM能够很好地匹配含有4个以上话语的长语境的反应,对于只有2个回合的短语境仍能稳定地匹配反应。
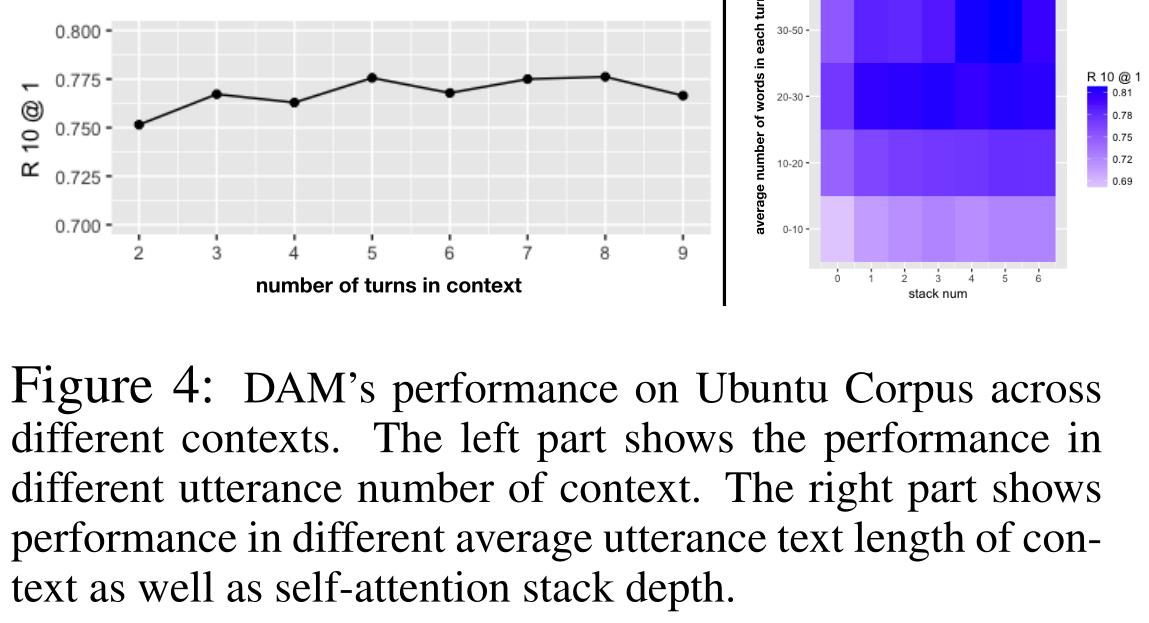
堆叠自注意可以持续提高具有不同平均话语文本长度上下文的匹配性能,这意味着使用多粒度语义表示具有稳定性优势:
- 短话语的匹配性能明显低于长话语。这是因为话语文本越短,包含的信息就越少,选择下一个话语就越困难,而堆叠自我关注在这种情况下仍然有帮助。
- 对于包含30个以上单词的长话语,叠加自我注意可以显著提高匹配性能,即一个话语包含的信息越多,就越需要叠加自我注意来捕获其内部语义结构。
2. 注意力可视化
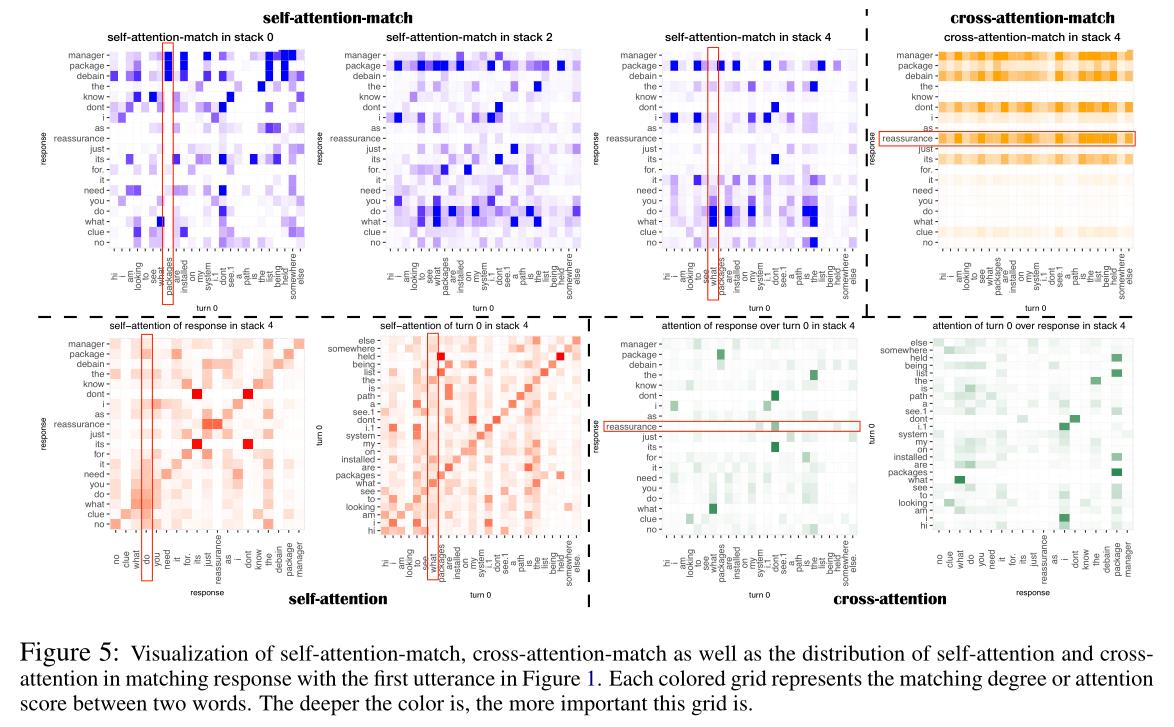
在实际应用中对自注意匹配和交叉注意匹配应用了softmax,以检验在叠加自注意和交叉注意时支配匹配对的方差。
自注意匹配和交叉注意匹配在话语与回复的匹配中捕获互补信息,回复片段在话语和回复中通常会捕捉到结构-语义信息,放大了它们相对于其他片段的匹配分数。
3. 错误分析
主要出现的错误类型:
- fuzzy-candidate,模糊候选,除了一些不恰当的细节外,回复的候选基本上适合会话上下文。
- logical-error,逻辑错误,应试者由于逻辑不匹配而出现错误。
paper地址:https://www.aclweb.org/anthology/P18-1103.pdf
代码地址:https://github.com/baidu/Dialogue
有帮助的话可以点个赞喔~

以上是关于论文阅读Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network的主要内容,如果未能解决你的问题,请参考以下文章