论文阅读Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances
Posted 桥本环奈粤港澳分奈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances相关的知识,希望对你有一定的参考价值。
目录

ACL2021
Conversations Are Not Flat: Modeling the Dynamic Information Flow across Dialogue Utterances
DialoFlow模型: 建模对话动态信息流
paper地址:https://arxiv.org/pdf/2106.02227.pdf
代码地址:https://github.com/ictnlp/DialoFlow
一、简介
1. 背景
现有的建模对话历史的方法主要分为两种。一种是直接拼接对话历史,这种方法在某种程度上忽略了对话历史中跨句子的对话动态。另外一种是多层次建模,首先对每句话做表示,再对整个对话做表示,这种方法在对每句话做表示时忽略了其他句子的作用。(flat)
2. 简介
本文提出了建模对话动态信息流的方法DialoFlow,引入dynamic flow 动态流机制通过处理每个话语带来的语义影响来模拟整个对话历史中的动态信息流。
在Reddit上进行了预训练,实验表明,DialoFlow在对话生成任务(Reddit multi-reference、DailyDialog multi-reference)上明显优于DialoGPT。
此外,本文还提出了Flow score,一种基于预训练的DialoFlow的评价人机交互对话质量的有效自动度量,在DSTC9交互式对话评估数据集上的评估结果与人工评估一致性达到0.9。
二、方法
1. 任务
设
D
=
u
1
,
u
2
,
…
,
u
N
D = {u_1,u_2, …, u_N}
D=u1,u2,…,uN表示整个对话。对于每一条话语
u
k
=
u
k
1
,
u
k
2
,
…
,
u
k
T
u_k= {u^1_k, u^2 _k,…, u^T _k}
uk=uk1,uk2,…,ukT,其中
u
k
t
u^t_k
ukt表示第k条话语中的第t个单词。
u
<
k
=
u
1
,
u
2
,
…
,
u
k
−
1
u_{<k}= {u_1, u_2,…, u _{k-1}}
u<k=u1,u2,…,uk−1为第k条话语的历史对话,也就是上下文
C
k
C_k
Ck,
C
k
+
1
C_{k+1}
Ck+1和
C
k
C_k
Ck间的差异定义为semantic influence
I
k
I_k
Ik:
I
k
=
C
k
+
1
−
C
k
I_k=C_{k+1}-C_k
Ik=Ck+1−Ck
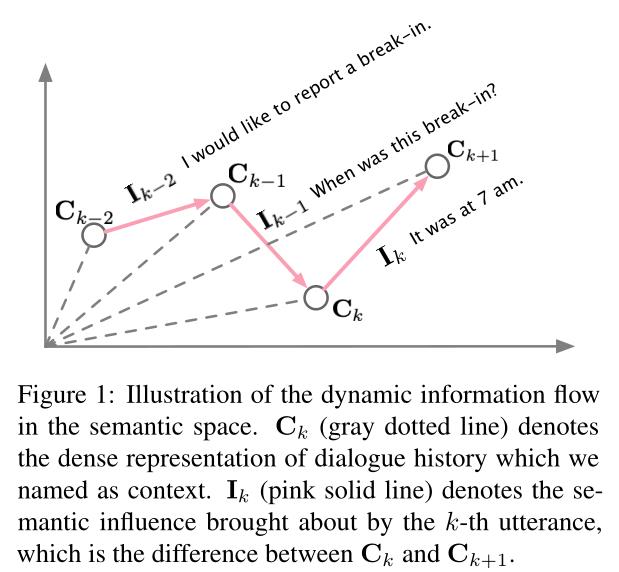
DialoFlow首先对对话历史进行编码,并根据之前所有的历史上下文 C 1 C_1 C1, C 2 C_2 C2,…, C k C_k Ck预测未来的上下文 C k + 1 ′ C^{'}_{k+1} Ck+1′。然后在回复生成阶段,模型获取预测的目标语义影响 I k ′ I^{'}_{k} Ik′,并考虑预测语义影响和历史子句生成目标回复 u k u_k uk。
2. 模型架构
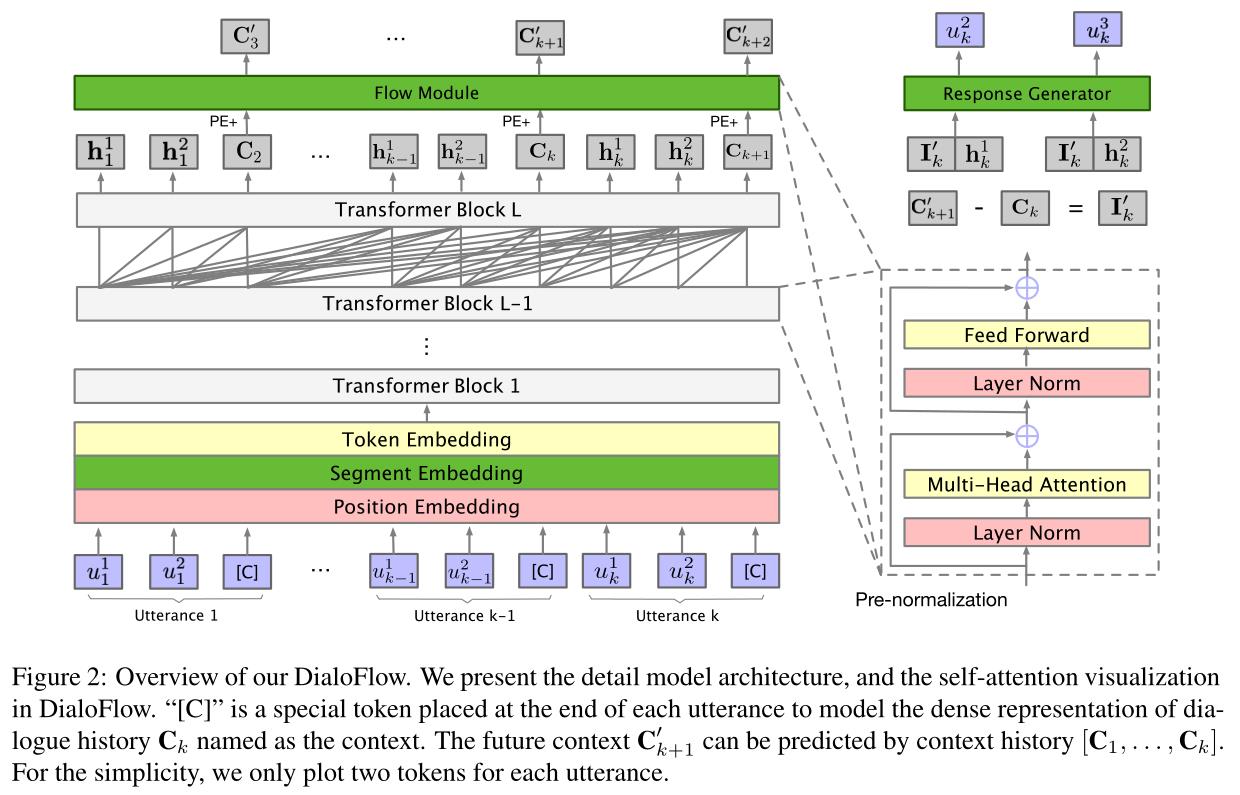
DialoFlow由输入embeddings、transfoemer块、单向Flow模块和回复生成器四部分组成。
Input Embedding
将token embedding、segment embedding和 position embedding的总和作为模型输入,在句末插入token “[C]”作为话语结束标记。segment embedding 包含“[Speaker1]”和“[Speaker2]”两种,来模拟说话人。
Transformer Block
使用了GPT-2里的pre-normalization
DialoFlow保持单向对话编码,在对话级别训练,而不是上下文-回复级别。可以得到由transformer block编码的第k个话语处的历史上下文:
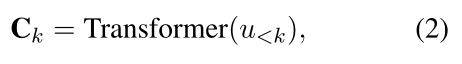
Flow Module
为了捕获对话话语中的动态信息流,本文设计了一个Flow模块来模拟语境变化。Flow模块的结构与一层transformer block相同,接受前面所有的上下文{C1,C2,…,Ck}作为输入,并预测第(k+1)条话语的上下文
C
k
+
1
′
C^{'}_{k+1}
Ck+1′
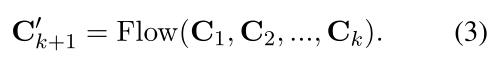
以及预测第k个话语引起的语义影响
I
k
′
I^{'}_{k}
Ik′
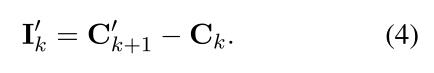
Response Generator
DialoFlow在预测语义影响 I k ′ I^{'}_{k} Ik′的指导下生成话语 u k u_k uk。回复生成器包含一个前馈层和一个softmax层,来将隐藏状态转换为tokens。在生成第t个单词时,回复生成器以预测的语义影响 I k ′ I^{'}_{k} Ik′和隐藏状态 h k t − 1 h^{t-1}_{k} hkt−1为输入,输出第t个单词的概率分布:
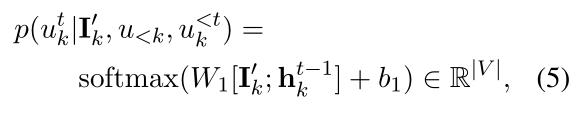
其中|V|为词汇量大小
3. 训练目标
与传统的上下文-回复的训练方法不同,DialoFlow是用包含N个话语的整个对话进行训练,相应地设计了三个训练任务来优化模型:
context flow modeling 目标是最小化预测的上下文
C
k
′
C^{'}_k
Ck′和真实上下文
C
k
C_k
Ck之间的L2距离
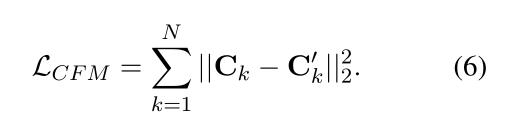
context flow semantic influence
semantic influence modeling 用预测的语义影响 I n ′ I^{'}_{n} In′设计了一个词袋损失来建模第n个话语在上下文 C n − 1 C_{n−1} Cn−1处带来的语义影响
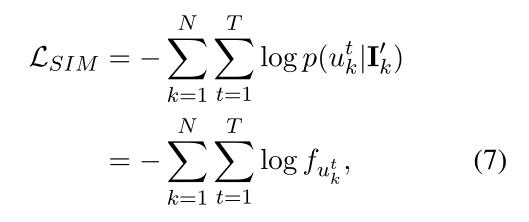
其中
f
u
k
t
f_{u_k^t}
fukt表示话语
u
k
u_k
uk中第t个单词
u
k
t
u_k^t
ukt的概率
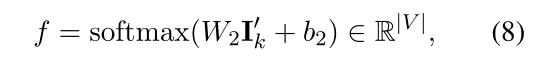
response generation modeling 回复生成的目标为:
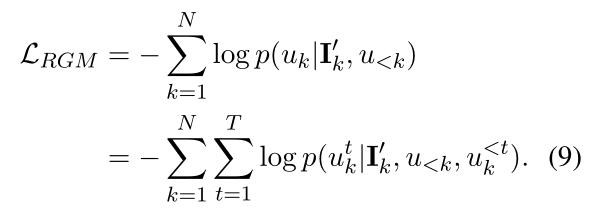
DialoFlow的整体培训目标可计算如下:
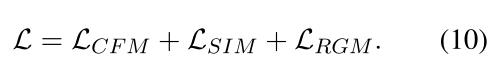
4. Flow Score
聊天机器人的话语所带来的语义影响与期望之间的差距越小,就越像人类。
本文提出了一种基于DialoFlow的交互式对话评价的自动无参考指标Flow score,当机器人生成一个新的话语 u k u_k uk时,测量 u k u_k uk所带来的预测语义影响 I k ′ I^{'}_{k} Ik′与真实语义影响 I k I_{k} Ik之间的相似度作为该话语与人类相似的概率。计算时同时度量余弦相似度和长度相似度:
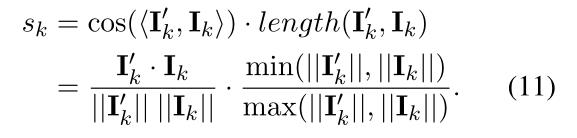
引入长度相似度是为了考虑长度差异对语义相似度的影响。对于聊天机器人在对话中的整体质量,本文设计的Flow score,可以视为对话级困惑度:
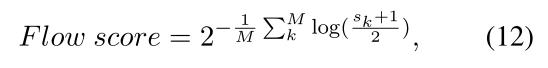
其中M为对话的回合数, ( s k + 1 ) / 2 (s_k+1)/2 (sk+1)/2是为了将相似度值缩放到[0,1]。Flow score越低,对话质量越高。
三、实验
1. 数据集
-
Reddit comments
-
Reddit Test Dataset
-
DailyDialog
-
DSTC9
2. 实验设置
-
DialoFlow基于预训练过的GPT-2进行预训练。
-
使用0.01权值衰减的AdamW优化器和12000热身步骤的linear learning rate scheduler。
-
DialoFlow-base和DialoFlow-medium的学习率是2e-4,DialoFlow-large的学习率是1e-4。
-
所有模型的批处理大小1024,DialoFlow-base和DialoFlow-medium训练4个epochs,DialoFlow-large训练2个epochs。在8个Nvidia V100 gpu上训练DialoFlow-large大约需要两个月的时间。
-
对DialoFlow-medium model 和DialoFlow-large使用 beam search(波束宽度为10),对DialoFlow-base采用贪婪搜索(和DialoGPT保持一致)
-
在DailyDialog数据集上,对预训练的DialoFlow和DialoGPT进行微调,根据validation损失选择checkpoint,然后使用beam search (with beam width 5)进行解码