LLVM Link Time Optimization
Posted 老司机技术周报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LLVM Link Time Optimization相关的知识,希望对你有一定的参考价值。
作者: 靛青,坚持在移动端的 ios 开发,还爱着 Swift 和 RxSwift,目前更多关注在 LLVM 方面的内容。
LLVM[1] 的链接时优化(Link Time Optimization,简称 LTO)已经在 WWDC 2016[2] 中提及到。因为这个选项在 Xcode 中默认关闭的,我也一直没有开启过这个选项,所以之前没有做过什么了解。趁着这次五一放个假,我们可以看看 LTO 是什么,以及它的整个流程是什么样子。
我们知道一个程序从源码到运行,需要有一个静态链接的过程。
在这个过程中,在解决所有的符号引用关系期间,我们可以知道整个程序的全貌。为此我们能以全局的角度做一些优化,这就是链接时优化。
我在这里将 LTO 理解为:借助静态链接可以获取程序全局信息的机会,做一些全局优化,这样可以提高运行时的性能,并进一步减少二进制的大小。
阅读本文前,建议先看完 LLVM Link Time Optimization: Design and Implementation[3] 。
从一个 Xcode 项目了解 LTO
工程地址:GitHub - DianQK/lto-example[4]。
为了了解整个的优化过程,我们从创建一个 Xcode 项目开始探索。
为了尽可能减少无关文件影响,这里创建了一个简单的 macOS 命令行工具 foo。
这是从 LLVM Link Time Optimization: Design and Implementation[5] 复制的例子,这个例子很好地展示的 LTO 优化过程。不同的是我们创建了一个静态库。
同时还有以下改动:
foo3移除了static避免内联优化关闭
DEAD_CODE_STRIPPING避免被其他优化影响我们关注 LTO 关键流程使用
-Os编译参数观察结果
代码:
--- bar.h ---
extern int foo1(void);
extern void foo2(void);
extern void foo4(void);
--- bar.c ---
#include "a.h"
static signed int i = 0;
void foo2(void) {
i = -1;
}
int foo3() {
foo4();
return 10;
}
int foo1(void) {
int data = 0;
if (i < 0)
data = foo3();
data = data + 42;
return data;
}
--- main.c ---
#include <stdio.h>
#include "a.h"
void foo4(void) {
printf("Hi\\n");
}
int main() {
return foo1();
}
工程结构:
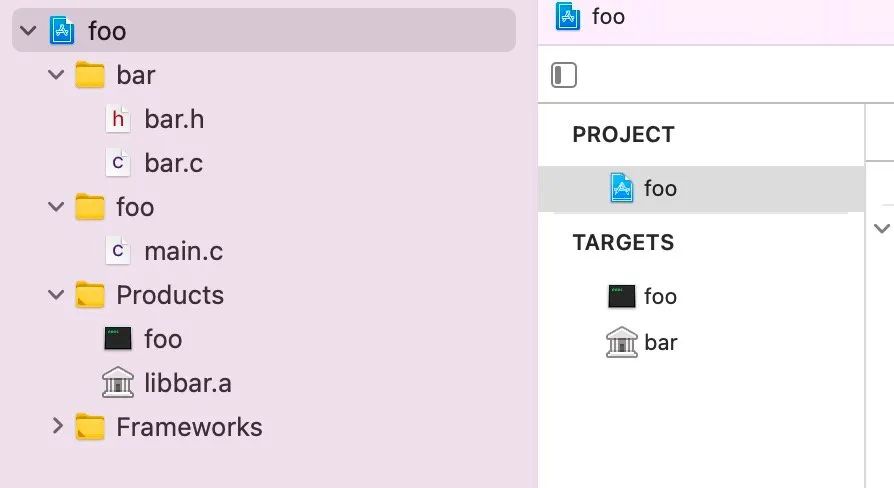
Commad + B 一把梭,得到如下链接命令:

从这个命令的执行中,我们可以看到 -object_path_lto 和 foo_lto.o ,或许我们早就开启了 LTO?但如果你尝试查看这个文件,会发现这个文件不存在。
从 clang 文档[6] 中可以了解到,-Xlinker 会把后面的参数会传递给链接器。而链接时调用 clang 的命令,仅仅是对链接器参数进行一个封装和传递。
Tip:使用
-Wl也可以传递参数,-Xlinker -object_path_lto -Xlinker /path/foo_lto.o等于-Wl,-object_path_lto,/path/foo_lto.o,使用-Wl会更简洁。
将该命令完整复制并添加 -v 参数,可以得到翻译后的真实链接器命令:
Apple clang version 12.0.5 (clang-1205.0.22.9)
Target: arm64-apple-macos11.3
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
"/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ld" -demangle -lto_library /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/libLTO.dylib -dynamic -arch arm64 -platform_version macos 11.3.0 11.3 -syslibroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.3.sdk -o /Users/yahaha/Desktop/foo/build/foo/Build/Products/Release/foo -L/Users/yahaha/Desktop/foo/build/foo/Build/Products/Release -filelist /Users/yahaha/Desktop/foo/build/foo/Build/Intermediates.noindex/foo.build/Release/foo.build/Objects-normal/arm64/foo.LinkFileList -object_path_lto /Users/yahaha/Desktop/foo/build/foo/Build/Intermediates.noindex/foo.build/Release/foo.build/Objects-normal/arm64/foo_lto.o -lbar -no_adhoc_codesign -dependency_info /Users/yahaha/Desktop/foo/build/foo/Build/Intermediates.noindex/foo.build/Release/foo.build/Objects-normal/arm64/foo_dependency_info.dat -lSystem /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/12.0.5/lib/darwin/libclang_rt.osx.a -F/Users/yahaha/Desktop/foo/build/foo/Build/Products/Release
我们可以从该命令中,搜索到两个有 lto 关键字的参数:-lto_library /path/usr/lib/libLTO.dylib 和 -object_path_lto /path/arm64/foo_lto.o。
使用 man ld 可以得到这两个参数的用途:
-object_path_lto filename
When performing Link Time Optimization (LTO) and a temporary mach-o object file is needed, if this option is used, the temporary file will be stored at the specified path and remain after the link is complete. Without the option, the linker picks a path and deletes the object file before the linker tool completes, thus tools such as the debugger or dsymutil will not be able to access the DWARF debug info in the temporary object file.
-lto_library path
When performing Link Time Optimization (LTO), the linker normally loads libLTO.dylib relative to the linker binary (../lib/libLTO.dylib). This option allows the user to specify the path to a specific libLTO.dylib to load instead.
很明显,这就是本文提到的 LTO。
为了可以链接时以全局的范围进行优化,使用 -object_path_lto 指定一个临时的目标文件,LTO 会将所有的目标文件合成一个大的 lto.o 目标文件。借助这个大目标文件进行全局优化。从参数说明中可以看到当指定这个文件路径时,链接完成后,这个文件会保留下来的。
而 -lto_library 用于指定具体使用的 libLTO 动态库,链接器将加载该动态库,借助动态库中提供的函数完成目标文件的合并工作。
现在我们在项目中打开 LTO:
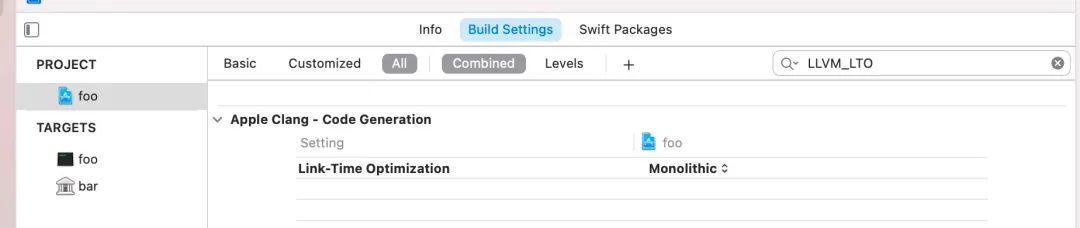
本文只关注
Monolithic参数下的 LTO,不讨论Incremental LTO。
得到的链接命令如下:
Apple clang version 12.0.5 (clang-1205.0.22.9)
Target: arm64-apple-macos11.3
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
"/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ld" -demangle -lto_library /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/libLTO.dylib -dynamic -arch arm64 -platform_version macos 11.3.0 11.3 -syslibroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX11.3.sdk -o /Users/yahaha/Desktop/foo/build/foo/Build/Products/Release/foo -L/Users/yahaha/Desktop/foo/build/foo/Build/Products/Release -filelist /Users/yahaha/Desktop/foo/build/foo/Build/Intermediates.noindex/foo.build/Release/foo.build/Objects-normal/arm64/foo.LinkFileList -object_path_lto /Users/yahaha/Desktop/foo/build/foo/Build/Intermediates.noindex/foo.build/Release/foo.build/Objects-normal/arm64/foo_lto.o -lbar -no_adhoc_codesign -dependency_info /Users/yahaha/Desktop/foo/build/foo/Build/Intermediates.noindex/foo.build/Release/foo.build/Objects-normal/arm64/foo_dependency_info.dat -lSystem /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/12.0.5/lib/darwin/libclang_rt.osx.a -F/Users/yahaha/Desktop/foo/build/foo/Build/Products/Release
这链接参数和关闭 LTO 的参数完全一样,不过这次我们得到了 lto.o 文件:
$ file /path/arm64/foo_lto.o
/path/arm64/foo_lto.o: Mach-O 64-bit object arm64
如果查看这个目标文件,可以看到这个目标文件包含了所有的符号信息,说明 LTO 确实将所有目标文件合并到该临时文件。
符合链接器的参数描述情况,这说明打开工程中 LLVM_LTO 应当生效了,我们成功打开了 LTO。而链接器的参数完全没有变化,说明 LTO 的工作还需要编译的支持。
当开启 LLVM_LTO 的 Target 编译时,clang 参数将多出一个 -flto。此时我们查看编译的目标文件,可以得到如下内容:
$ file /path/arm64/bar.o
/path/arm64/bar.o: LLVM bitcode, wrapper
当关闭 LLVM_LTO,即去掉 -flto 时:
$ file /path/arm64/bar.o
/path/arm64/bar.o: Mach-O 64-bit object arm64
这是我们平时遇到的 Mach-O 目标文件。而 LLVM bitcode 是 LLVM 的中间文件(IR),这个中间文件可以使用 llvm 的一系列工具进行优化,最常见的应当是 opt - LLVM optimizer[7]。
此外如果我们关闭
LLVM_LTO,并在OTHER_CFLAGS中添加-emit-llvm,也能得到 IR 文件。
让我们继续调整配置,可以得到以下结果:
静态库 bar 打开 LTO,主工程 foo 也打开 LTO,产物大小为 35680 Bytes,定义符号有
_mainbar 打开 LTO,foo 关闭 LTO,产物大小为 69216 Bytes,定义符号有
_foo1、_foo4、_mainbar 关闭 LTO,foo 打开 LTO,产物大小为 69424 Bytes,定义符号有
_foo1、_foo2、_foo3、_foo4、_main全部关闭 LTO,产物大小为 69424 Bytes,定义符号有
_foo1、_foo2、_foo3、_foo4、_main
这说明如果想完美展现 LTO 效果,所有静态库必须编译为 LLVM bitcode(添加 -flto 参数)。如果在一个大型项目中,集成的组件都以 Mach-O 的二进制格式集成,那最终 LTO 的效果会变得不明显。一个比较简单的判断优化效果的方式是链接时间越长,可优化内容越多,效果越好。如果你开启 LTO 和没开启 LTO,链接耗时差不多,那说明没有完全开启 LTO。
以上 四种 LTO 开启范围的结果如下:
第一种,全部打开 LTO,bar.o 和 foo.a 均为 LLVM Bitcode,都可以再进行优化。和 LLVM Link Time Optimization: Design and Implementation[8] 文档中一样。
由于链接产物就是最终产物,我们可以判断出没有使用
foo2,于是可以移除foo2这个符号i < 0永远是false,实际运行不会用到foo3,于是可以移除foo3这个符号移除
foo3后,foo4也用不到了,也可以移除在
Os优化下,foo1仅有一处调用,我们可以合并到main中,此时仅剩一个main了
第二种,仅打开 bar LTO:
由于
main.o不是 IR,所以我们只能保留main和foo4由于
main.o中调用了foo1,foo1也得保留下来幸运地是,
foo3和foo2在bar.o这个 Bitcode 中,我们也可以判断到这两个函数运行时不可能调用,将它们移除最终保留
foo1、foo4和main
第三种,仅打开 foo LTO:由于 bar.o 不能优化,foo4 也被 bar.o 使用,所以全部符号都得保留下来。
第四种,由于没有 IR 文件,所以不会进行优化。
从这四种情况中,进一步说明了 LTO 在链接时,如果查找到的对象是个 LLVM Bitcode 文件时,则将 将该文件合并到 lto.o 中进行优化。当然如果都是 Mach-O 文件,链接会跳过 LTO 过程。
从链接过程中了解 LTO
在 LLVM Link Time Optimization: Design and Implementation[9]中已经有了细致的解释,我们结合 ld64 和 llvm 中 libLTO 部分进行一番理解。
ld64[10] 是 Xcode 使用的静态链接器,也就是 /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ld 源码。
这个开源工程不能直接跑起来,我创建了个 patch 解决了编译问题,可以使用 GitHub - DianQK/ld64-build[11] 进行编译调试。
使用 ld 提供的 -print_statistics 参数,可以得到链接过程每个步骤的耗时:
clang 上使用
-Wl,-print_statistics。
ld total time: 36.5 milliseconds ( 100.0%)
option parsing time: 0.7 milliseconds ( 2.0%)
object file processing: 0.0 milliseconds ( 0.1%)
resolve symbols: 33.8 milliseconds ( 92.4%)
build atom list: 0.0 milliseconds ( 0.0%)
passess: 1.2 milliseconds ( 3.2%)
write output: 0.7 milliseconds ( 2.0%)
pageins=83, pageouts=0, faults=1781
processed 1 object files, totaling 4,240 bytes
processed 2 archive files, totaling 143,016 bytes
processed 38 dylib files
wrote output file totaling 16,816 bytes
以上为打开 LTO 的数据,关闭 LTO 得到:
ld total time: 19.2 milliseconds ( 100.0%)
option parsing time: 0.2 milliseconds ( 1.2%)
object file processing: 0.0 milliseconds ( 0.1%)
resolve symbols: 17.8 milliseconds ( 92.3%)
build atom list: 0.0 milliseconds ( 0.0%)
passess: 0.8 milliseconds ( 4.6%)
write output: 0.3 milliseconds ( 1.6%)
pageins=1, pageouts=0, faults=677
processed 1 object files, totaling 2,708 bytes
processed 2 archive files, totaling 140,960 bytes
processed 38 dylib files
wrote output file totaling 50,312 bytes
通过可以对比得到 resolve symbols 环节是静态链接最耗时的地方,并且在打开 LTO 后,这个环节时间增加了近一倍。
用伪代码标识 ld main 函数如下:
int main(int argc, const char* argv[]) {
// option parsing 解析输入参数
Options options(argc, argv);
// object file processing 获取所有的输入文件,包括 .o .a 等
InputFiles inputFiles(options);
// resolve symbols 解决符号引用关系
Resolver resolver(options, inputFiles);
resolver.resolve();
// passess 执行一些生成地址的 pass,比如 GOT
Passes.doPass();
// write output 写入产物信息
OutputFile out(options, state);
out.write(state);
}
而在 Resolver::resolve() 关键过程如下:
void Resolver::resolve() {
// 构建 Atom 列表,Atom 是 ld64 中链接最小单元,比如函数、全局变量
this->buildAtomList();
// 解决符号引用关系
this->resolveUndefines();
// 执行 LTO
this->linkTimeOptimize();
}
从这里我们知道,LTO 是在解决完一次符号引用关系查找后进行的。
在 LTO 文档中,我们知道 LTO 的处理有 4 个阶段:
Read LLVM Bitcode Files
Symbol Resolution
Optimize Bitcode Files
Symbol Resolution after optimization
这里我们重点关注第 1 阶段和第 3 阶段。
第 1 阶段,获取 LLVM Bitcode,和获取其他文件一样,都在静态链接的 object file processing 中。
InputFiles 类提供了 makeFile 工厂方法,可以通过读取文件头部信息判断文件类型,生成对应的 File 实例。当发现输入文件为 LLVM Bitcode 时,调用 lto_module_create() 等 libLTO 提供的函数完成对 LLVM bitcode 的解析及符号信息获取。
判断是不是 LLVM Bitcode 的方式很简单,确定文件头部信息为 0xdec017ob 即可:
$ file /path/bar.o
/path/bar.o: LLVM bitcode, wrapper
$ hexdump -n 4 /path/bar.o
0000000 de c0 17 0b
第 3 阶段,优化合并的 Bitcode,这部分在 Resolver::linkTimeOptimize() 中,这里有一个比较长的调用链,顺着调用链 Parser::optimize() -> Parser::optimizeLTO() -> Parser::codegen() 找到 Parser::codegen()。
与文档描述略有不同,在 Parser::codegen() 中,ld 使用新版的 libLTO 时,将 lto_codegen_compile() 分为两个函数 lto_codegen_optimize() 和 lto_codegen_compile_optimized() 依次调用,这两个函数分别表示对 Bitcode 进行优化、汇编生成机器码。
由于 lto_* 属于 libLTO 部分,想了解更多细节可以在 llvm 工程的 llvm/tools/lto 和 llvm/lib/LTO 中找到。lto_codegen_optimize() 最终会调用 LTOCodeGenerator::optimize(),这是 Bitcode 优化关键逻辑。
这个优化方法将调用内部的一个 lto::opt,这个 opt 和 opt - LLVM optimizer[12] 几乎一样,执行 LLVM 的各种 Pass 优化。
所以我们甚至在链接期间传递 opt 相关参数,这个参数将被应用到 LTO 优化阶段。比如使用 -Wl,-mllvm,-time-passes 传递一个优化耗时记录:
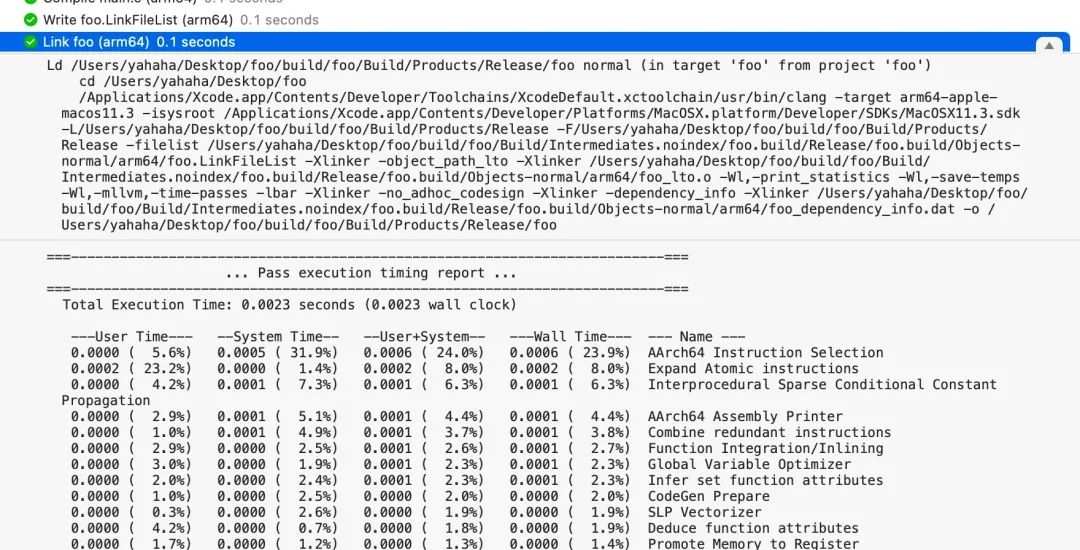
到这里我们可以了解到,LTO 的核心功能在 libLTO 动态库中,它主要提供了 LLVM Bitcode 解析和优化能力。ld 通过在不同时机调用 libLTO 提供的 API 完成全部的优化功能。
从以上内容中,我们可以得到值得关注的几点:
ld 的静态链接中,是否执行 LTO 由输入文件中是否有 LLVM Bitcode 判断
开启 LTO 时,编译的 .o 文件由 Mach-O 变为 LLVM Bitcode 中间文件
ld 使用 libLTO 将所有的 Bitcode 文件合并为一个模块进行优化,
静态链接中添加
-mllvm,-opt-argument可以传递参数给 LTO 的优化过程
额外的一些问题
全二进制集成下,LTO 能不能有些效果
会有,这部分主要在 Section __objc_const 上。当开启 -dead_strip 时,Resolver::linkTimeOptimize() 会有一次额外的 dead code 优化。
示例的 iOS 工程中,两个二进制大小如下:
$ llvm-size --format=darwin link_only_main_lto
Segment __TEXT: 32768
total 7459
Segment __DATA_CONST: 16384
total 104
Segment __DATA: 16384
Section __objc_const: 3840
total 4724
Segment __LINKEDIT: 32768
$ llvm-size --format=darwin link_nolto
Segment __TEXT: 32768
total 7459
Segment __DATA_CONST: 16384
total 104
Segment __DATA: 16384
Section __objc_const: 4568
total 5452
Segment __LINKEDIT: 32768
可以清晰看到仅在主工程(只有 main 函数情况下),开启 LTO,__objc_const 减少了 728。这个效果在更大的工程中将表现的更明显。
从 LinkMap 中可以看到移除的符号都属于 AppDelegate.o。
# Path: /path/link.app/link
# Arch: arm64
# Object files:
[ 0] linker synthesized
[ 1] /path/arm64/main.o
[ 2] /path/Release-iphoneos/libcode.a(ViewController.o)
[ 3] /path/libcode.a(AppDelegate.o)
[ 4] /path/libcode.a(SceneDelegate.o)
...
# Dead Stripped Symbols:
# Size File Name
<<dead>> 0x000001D0 [ 3] __OBJC_$_PROTOCOL_INSTANCE_METHODS_NSObject
<<dead>> 0x00000020 [ 3] __OBJC_$_PROTOCOL_INSTANCE_METHODS_OPT_NSObject
<<dead>> 0x00000048 [ 3] __OBJC_$_PROP_LIST_NSObject
<<dead>> 0x000000A0 [ 3] __OBJC_$_PROTOCOL_METHOD_TYPES_NSObject
如果你打算了解更多细节,搜索 ld64 中 this->deadStripOptimize(true) 进行调试即可。
如果你在 main 函数中引用更多的符号,这部分优化效果将更明显,这将移除双份的
__OBJC_$_PROTOCOL_INSTANCE_METHODS_NSObject等符号记录。
关注我们
我们是「老司机技术周报」,每周会发布一份关于 iOS 的周报,也会定期分享一些和 iOS 相关的技术。欢迎关注。
关注有礼,关注【老司机技术周报】,回复「2020」,领取学习大礼包。
参考资料
[1]
LLVM: https://github.com/llvm/llvm-project
[2]WWDC 2016: https://developer.apple.com/videos/play/wwdc2016/405
[3]LLVM Link Time Optimization: Design and Implementation: https://llvm.org/docs/LinkTimeOptimization.html
[4]GitHub - DianQK/lto-example: https://github.com/DianQK/lto-example
[5]LLVM Link Time Optimization: Design and Implementation: https://llvm.org/docs/LinkTimeOptimization.html
[6]clang 文档: https://clang.llvm.org/docs/CommandGuide/clang.html#cmdoption-xlinker
[7]opt - LLVM optimizer: https://llvm.org/docs/CommandGuide/opt.html
[8]LLVM Link Time Optimization: Design and Implementation: https://llvm.org/docs/LinkTimeOptimization.html
[9]LLVM Link Time Optimization: Design and Implementation: https://llvm.org/docs/LinkTimeOptimization.html
[10]ld64: https://opensource.apple.com/source/ld64/ld64-609/
[11]GitHub - DianQK/ld64-build: https://github.com/DianQK/ld64-build
[12]opt - LLVM optimizer: https://llvm.org/docs/CommandGuide/opt.html
[13]程序员的自我修养:链接、装载与库: https://www.duokan.com/book/115161
以上是关于LLVM Link Time Optimization的主要内容,如果未能解决你的问题,请参考以下文章