python pdf二进制读取问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python pdf二进制读取问题相关的知识,希望对你有一定的参考价值。
现在直接open用rb方式打开一个.pdf文件,然后再wb到另外一个新pdf里面可以。但是我现在把rb打开的二进制写入到文本中再 wb到新pdf里面就不可以。这是为什么呢怎么才能还原这个pdf
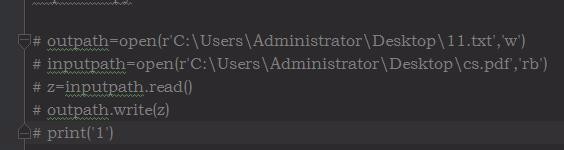
第一种方法是一次性读入文件(或文件的前多少个连续字节)到一个数组中,因此,灵活性差。
第二种方法灵活性很高,可以读取任意位置(使用文件的seek()方法跳跃位置)的二进制数据,再使用struct.unpack()方法来进行各种二进制解析。
提示:二进制文件是不保留存储方式的数据格式,因此,读二进制文件时应该知道二进制文件的存储格式。追问
你好,我去看了下struct库的用法。但是还是没太看懂。初学请见谅~
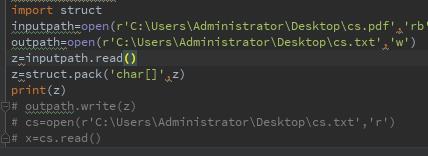
我现在理解的是我‘rb’方式打开了.pdf过后,要用struct库先转成留二进制流再写进文本里?
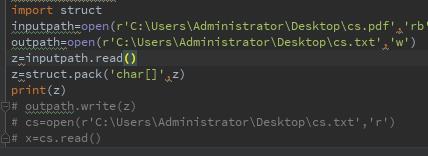
在从文本打开么?还是没太弄明白。我想的是我把pdf转成二进制的txt文件,随时想看了再还原出来。
如何使用Python脚本从PDF中读取阿拉伯语文本
我有一个用Python编写的代码,可以从PDF文件中读取并将其转换为文本文件。
当我尝试从PDF文件中读取阿拉伯文本时出现问题。我知道错误是在编码和编码过程中,但我不知道如何解决它。
系统转换阿拉伯语PDF文件,但文本文件为空。并显示此错误:
回溯(最近一次调用最后一次):文件“C: Users test Downloads pdf-txt text maker.py”,第68行,在f.write(内容)中UnicodeEncodeError:'ascii'编解码器无法编码字符u' xa9'位置50:序数不在范围内(128)
码:
import os
from os import chdir, getcwd, listdir, path
import codecs
import pyPdf
from time import strftime
def check_path(prompt):
''' (str) -> str
Verifies if the provided absolute path does exist.
'''
abs_path = raw_input(prompt)
while path.exists(abs_path) != True:
print "
The specified path does not exist.
"
abs_path = raw_input(prompt)
return abs_path
print "
"
folder = check_path("Provide absolute path for the folder: ")
list=[]
directory=folder
for root,dirs,files in os.walk(directory):
for filename in files:
if filename.endswith('.pdf'):
t=os.path.join(directory,filename)
list.append(t)
m=len(list)
print (m)
i=0
while i<=m-1:
path=list[i]
print(path)
head,tail=os.path.split(path)
var="\"
tail=tail.replace(".pdf",".txt")
name=head+var+tail
content = ""
# Load PDF into pyPDF
pdf = pyPdf.PdfFileReader(file(path, "rb"))
# Iterate pages
for j in range(0, pdf.getNumPages()):
# Extract text from page and add to content
content += pdf.getPage(j).extractText() + "
"
print strftime("%H:%M:%S"), " pdf -> txt "
f=open(name,'w')
content.encode('utf-8')
f.write(content)
f.close
i=i+1
答案
你有几个问题:
content.encode('utf-8')什么都不做。返回值是编码内容,但您必须将其分配给变量。更好的是,使用编码打开文件,并将Unicode字符串写入该文件。content似乎是Unicode数据。
示例(适用于Python 2和3):
import io
f = io.open(name,'w',encoding='utf8')
f.write(content)
- 如果未正确关闭文件,则可能看不到任何内容,因为该文件未刷新到磁盘。你有
f.close而不是f.close()。最好使用with,它确保在块退出时关闭文件。
例:
import io
with io.open(name,'w',encoding='utf8') as f:
f.write(content)
在Python 3中,您不需要导入和使用io.open,但它仍然有效。 open是等价的。 Python 2需要io.open表单。
以上是关于python pdf二进制读取问题的主要内容,如果未能解决你的问题,请参考以下文章