Zookeeper集群
Posted 永旗狍子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper集群相关的知识,希望对你有一定的参考价值。
目录
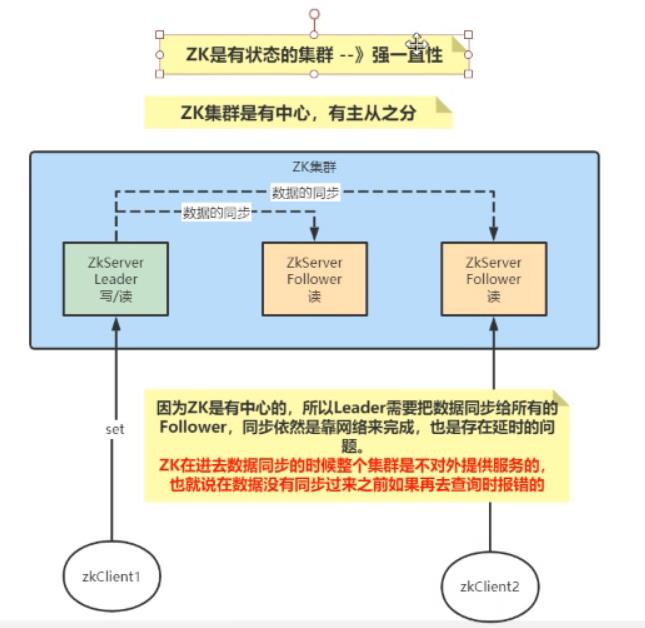
Zookeeper集群架构图
Zookeeper集群中节点的角色
Leader(Master):事务请求的唯一处理者,也可以处理读请求。
Follower(Slave):可以直接处理客户端的读请求,并向客户端响应;但其不会处理事务请求,其只会将客户端事务请求转发给Leader来处理,同步 Leader 中的事务处理结果;Leader 选举过程的参与者,具有选举权与被选举权。(就好像正式工)
Observer(Slave):可以理解为不参与 Leader 选举的 Follower,在 Leader 选举过程中没有选举权与被选举权;同时,对于 Leader 的提案没有表决权。用于协助 Follower 处理更多的客户端读请求。Observer 的增加,会提高集群读请求处理的吞吐量,但不会增加事务请求的通过压力,不会增加 Leader 选举的压力。(就好像临时工)
Zookeeper数据同步
ZooKeeper 集群的所有机器通过一个 Leader来完成写服务(也可以完成读)。Follower只提供读服务,不能提供写服务。
如果有机器要对节点做更新,这个机器先告诉Leader。
Leader收到后请求后广播给所有的节点进行写操作,每个角色都在自己的机器中写。
每个机器写完后都给Leader汇报是否写入成功
如果有一半的机器写成功了Leader就下发第二个指令
提交事务,以广播的形式发出。
Zookeeper选举
每一个Zookeeper服务都会被分配一个全局唯一的myid,··是一个数字。
Zookeeper在执行写数据时,每一个节点都有一个自己的FIFO的队列。保证写每一个数据的时候,顺序是不会乱的,Zookeeper还会给每一个数据分配一个全局唯一的zxid,数据越新zxid就越大。
选举Leader:
选举出zxid最大的节点作为Leader。
在zxid相同的节点中,选举出一个myid最大的节点,作为Leader。
搭建Zookeeper集群
1、2181:对cline端提供服务
2、3888:选举leader使用
3、2888:集群内机器通讯使用(Leader监听此端口)
version: "3.1"
services:
zk1:
image: zookeeper
restart: always
container_name: zk1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk2:
image: zookeeper
restart: always
container_name: zk2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk3:
image: zookeeper
restart: always
container_name: zk3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
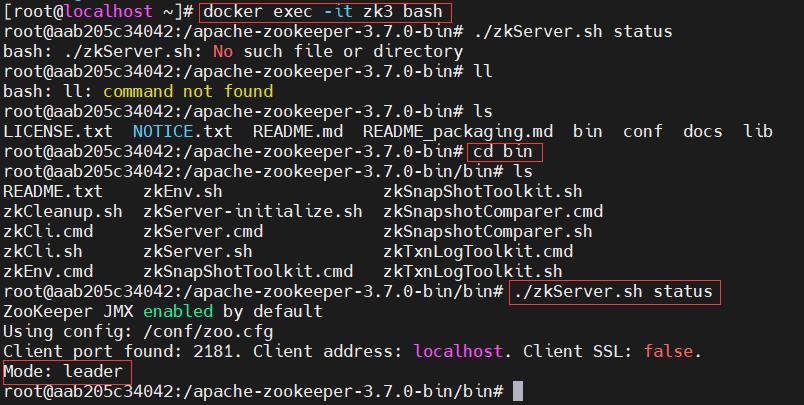
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181查看节点状态 zkServer.sh status
Java连接Zookeeper集群
@Configuration
public class ZookeeperConfig {
@Bean
public CuratorFramework curatorFramework() {
CuratorFrameworkFactory.Builder builder = CuratorFrameworkFactory.builder();
builder.connectString(1111.com:2181,1111.com:2182,1111.com:2183);// 连接zk的ip和端口
// 超时时间是3s,重试的次数是2次
builder.retryPolicy(new ExponentialBackoffRetry(3000,2));
// 构建操作ZK的客户但
CuratorFramework curatorFramework = builder.build();
// 必须要调用启动方法才能使用
curatorFramework.start();
return curatorFramework;
}
} @Autowired
private CuratorFramework zkClient;
@Test
void testCreateNode() throws Exception {
zkClient.create().forPath("/java-node-2","java连接zk集群".getBytes("utf-8"));
byte[] bytes = zkClient.getData().forPath("/java-node-2");
System.out.println("data:"+new String(bytes,0,bytes.length,"utf-8"));
System.out.println("节点创建成功。。。");
}leader是随机生成的
以上是关于Zookeeper集群的主要内容,如果未能解决你的问题,请参考以下文章