Kafka 学习Kafka 简介
Posted 思想累积
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka 学习Kafka 简介相关的知识,希望对你有一定的参考价值。
1、kafka概述
1.1 定义
- kafka是一个高吞吐量的
分布式发布订阅消息系统,分布式的基于发布订阅模式的消息队列` (Message Queue)MQ,主要应用于大数据实时处理方面 - Kafka 对于消息保存时根据
Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外,kafka 集群有多个 kafka 实例组成,每个实例 (server被称为)broker - 无论是 kafka 集群还是 comsumer 都依赖于 zookeeper 集群保存一些 meta 信息,来保存系统可用性
1.2 基础架构
生产者生产消息
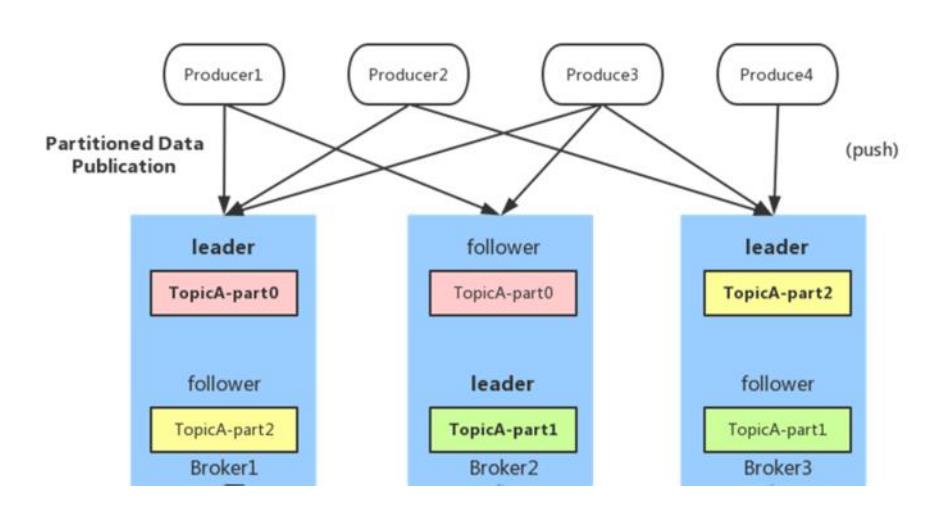
- producer:消息生产者,生产消息
- 生产者负责将数据推送给 broker 的 topic
- 批量发送:Producer 端可以在内存中合并多条消息后,
以一次请求的方式发送了批量的消息给 broker, 从而减少 broker 存储消息的 IO 操作次数。但也一定程度影响了消息的实时性. 以时延为代价, 换取更好的吞吐量 - 压缩:Producer 端可以通过 GZIP 或者 Snappy 格式对消息集合进行压缩, Producer 端进行压缩之后, 在 Consumer 端进行解压. 解压的好处就是减少传输的数据量, 减轻对网络传输的压力, 在对大数据的处理上, 瓶颈往往体现在网络上而不是 CPU (压缩和解压会消耗部分 CPU 资源)
kafka 管理消息
-
Broker:一台 kafka 服务器就是一个 Broker
- 一个集群有多个 broker 组成,一个 broker 可以容纳多个 topic
- broker 是无状态的,通过 Zookeeper 来维护集群状态
-
Topic:主题
- 主题是个逻辑概念,用于生产者发布数据,消费者拉取数据
- kafka 中的主题必须有标识符,而且是唯一的,kafka 中可以有任意数量的主题,没有数量限制
- 主题中的消息是有结构的,一般一个主题包含某一类消息
- 生产者发送消息到主题中,消息就不能被更改
-
Partition:
一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列, partition 中的每条消息都会被分配一个有序的id(offset).kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的topic的整体(多个partition间)的顺序- partition中的每条Message包含了以下三个属性
- offset : 表示在这个 partition 中的
偏移量,不是该 Message 在这个 partition 数据文件中的实际存储位置,而是逻辑上的一个值,可以认为 offset 是 partition 中 Message 的 id ; - MessageSie : 表示消息内容 data 的大小;
- data : Message的具体内容
- offset : 表示在这个 partition 中的
- partition 物理上由多个 segment 文件组成,每个 segment 大小相等,顺序读写.每个 segment 数据文件以该段中最小的 offset 命名,文件扩展名为
. log. 这样在查找指定offset的Message 的时候, 用二分查找就可以定位到该 Message 在哪个 segment数据文件中 - kafka 为每个分段后的数据文件建立了索引文件, 文件名与数据文件的名字是一样的, 只是文件扩展名为
.index. index 文件中并没有为数据文件中的每条 Message 建立索引, 而是采用了稀疏存储的方式, 每隔一定字节的数据建立一条索引, 这样就避免了索引文件占用过多的空间, 从而可以将索引文件保留在内存中
- partition中的每条Message包含了以下三个属性
-
replica:副本
- 实现 kafka 集群的容错,实现 partition 的容错。一个 topic 至少包含一个以上的 副本
-
offset:偏移量
- offset 记录着下一条要发送给 consumer 的消息的序号
- 默认 kafka 将offset 存储在 Zookeeper 中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都有个递增的 id,这个就是偏移量 offset
- 偏移量在分区中才有意义。在分区之间没有意义
消费者消费消息
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I0WhoxQz-1614432936739)(C:\\Users\\孙青达\\AppData\\Roaming\\Typora\\typora-user-images\\image-20210222221406163.png)]](https://image.cha138.com/20210719/323437b6d1c94c4fa8824004784aed89.jpg)
- Consumer:消息消费者,从 kafka broker 的 topic 中拉取消息,自己进行处理
- Consumer Group(CG):消费者组
- kafka 提供的可扩展且具有容错性的消费者机制,一个消费者组可以包含多个消费者,一个消费者组有唯一的 ID,配置 group.id 一样的消费者是属于同一个组。组内消费者一起消费主题的所有分区数据
- 同一个 Consumer Group 组中的多个 Consumer 实例, 不同时消费一个 partition, 等效于队列模式. partition内消息是有序的, Consumer 通过 pull 的方式消费消息. kafka 不删除已消费的消息, 对于 partition, 顺序读写磁盘数据, 以时间复杂度 0(1) 方式提供消息持久化能力
Zookeeper 注册消息
- Zookeeper:保存着集群 broker,topic,partition 等 meta 数据;另外,还负责 broker 故障发现,partition leader 选举,负载均衡等功能
- Zookeeper 服务主要用于通知 生产者和消费者 kafka 集群中有新的 broker 加入、或者 kafka 集群中出现故障的 broker。
2、异步通信原理
2.1 观察者模式
- 观察者模式(Observer),又叫发布订阅模式(Public/Subscribe)
- 定义对象间一种一对多的依赖关系,当每个对象改变状态,所有依赖于它的对象都会得到通知并自动更新
- 一个对象的目标状态发生变化,所有依赖对象(观察者)都将得到通知
2.2 生产者消费者模式
- 传统模式
- 生产者直接将消息传递给指定的消费者
- 耦合性高,生产者或者消费者发生变化,都需要重写业务逻辑
- 生产者消费者模式
- 通过一个容器来解决生产者和消费者的强耦合问题,生产者和消费者之间不直接通讯,通过阻塞队列来进行通讯
- 数据传递流程
- 生产者消费者模式,多个线程进行生产,多个线程进行消费,两种角色通过内存缓冲区进行通信
- 生产者负责向缓冲区里面添加数据单元
- 消费者负责从缓冲区里面取出数据单元
- 一般遵循先进先出的原则
2.3 缓冲区
- 解耦
- 假设生产者和消费者是两个类,如果让生产者直接调用消费者的某个方法,生产者对于消费者就会产生依赖
- 支持并发
- 生产者直接调用消费者的某个方法过程中函数调用是同步的
- 数据生产的快,消费者来不及处理,未处理的数据可以暂存在缓冲区中。
2.4 数据单元
- 关联到业务对象
- 传输过程中,要保证该数据单元的完整性
- 各个数据单元之间没有互相依赖
- 颗粒度,数据单元需要关联到某种业务对象。
以上是关于Kafka 学习Kafka 简介的主要内容,如果未能解决你的问题,请参考以下文章