系统设计基础 负载均衡
Posted Java大厂面试官
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统设计基础 负载均衡相关的知识,希望对你有一定的参考价值。
一、什么是负载均衡?
负载均衡是一种确保服务器不会过载的技术。采取适当的负载均衡措施后,工作负载和流量请求将在服务器资源之间分配,以提供更高的弹性和可用性。
在Internet的早期,单个服务器上的单个应用程序无法处理高流量的情况。无论底层基础架构多么强大,来自大量流量的并发服务器请求都会使单个服务器不堪重负。在没有实现负载平衡的情况下,应用程序可用性的一个单独实例是单点故障。这对系统的可靠性构成了巨大的威胁。
负载均衡的主要目的是将应用程序的工作负载分配到多台计算机上,以便该应用程序可以处理更高的工作负载。负载平衡是一种扩展应用程序的方式。
负载均衡的第二个目的通常是在您的应用程序中提供冗余。也就是说,如果服务器群集中的一台服务器发生故障,则负载平衡器可以暂时从群集中删除该服务器,并将负载分配到正常运行的服务器上。
-
多个服务器以这种方式互相帮助通常称为“冗余”。
-
当发生错误并将任务从发生故障的服务器移至正常运行的服务器时,通常称为“故障转移”。
-
协作运行同一应用程序的一组服务器通常称为服务器的“集群”。集群的目的通常是上述两个目标:将负载分配到不同的服务器上,并为彼此提供冗余/故障转移。
负载均衡作用或者功能
-
流量分发
负载均衡能对多台主机流量进行分发,提高用户系统的业务处理能力,提升服务可用性
-
会话保持
在会话周期内,会话保持可使来自同一IP或网段的请求被分发到同一台后端服务器上。
-
健康检查
支持自定义健康检查方式和频率,可定时检查后端主机运行状态,提供故障转移,实现高可用;
-
负载均衡
解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力);
-
提高扩展性通过添加或减少服务器数量,提供网站伸缩性(扩展性);
-
提高安全性安全防护,在负载均衡器上做一些过滤,黑白名单、防盗链等处理;
负载均衡如何工作?
典型的负载均衡顺序如下:
-
流量进入您的网站。您网站的访问者会通过Internet向您的服务器发送大量并发请求。 -
流量分布在服务器资源之间。负载均衡硬件或软件拦截每个请求,并将其定向到适当的服务器节点。 -
每个服务器运行合理的工作量。节点接收请求,并且能够接受请求并响应平衡器,因为它不会因太多请求而过载。 -
服务器返回请求。该过程以相反的顺序完成,以将服务器的响应传递回用户。
值得注意的是,只有在已经建立了多个资源(服务器,网络或虚拟资源)的情况下,上述步骤才能完成。否则,如果只有一个服务器或计算实例,则所有工作负载都将分配到同一位置,并且不再需要负载均衡。
二、负载均衡分类
为了充分利用负载均衡的可伸缩性和冗余性,我们可以尝试在系统每一层添加负载均衡器。我们可以在三个位置添加LB:
-
在用户和Web服务器之间 -
在Web服务器和内部平台层之间,例如应用程序服务器或缓存服务器 -
在内部平台层和数据库之间。
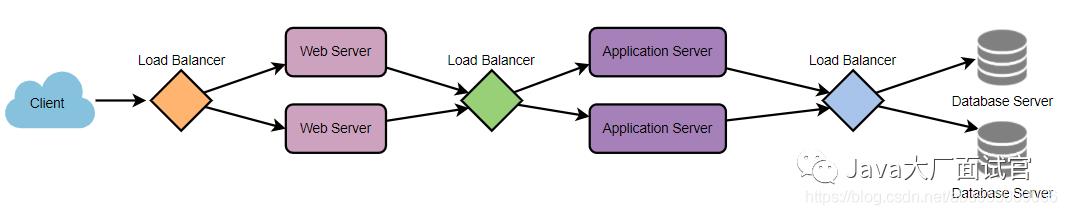
负载均衡器主要处理四种流量类型,包括:
-
HTTPS -负载均衡处理HTTPS流量通过设置 X-Forwarded-For,X-Forwarded-Proto和X-Forwarded-Port头部给予后端对原请求的其他信息。 -
HTTP-类似HTTPS。 -
UDP-某些负载衡器支持使用UDP的DNS和syslogd等协议的平衡。 -
TCP -TCP流量也可以分布在负载平衡器之间。到数据库集群的流量将是一个很好的例子。
按照常规开发角度可分为 中间件负载均衡和 客户端负载均衡
中间件负载均衡
使用独立的负载均衡器,对与客户端和服务端开发来说是无感知的,例如:硬件的F5,软件的nginx。
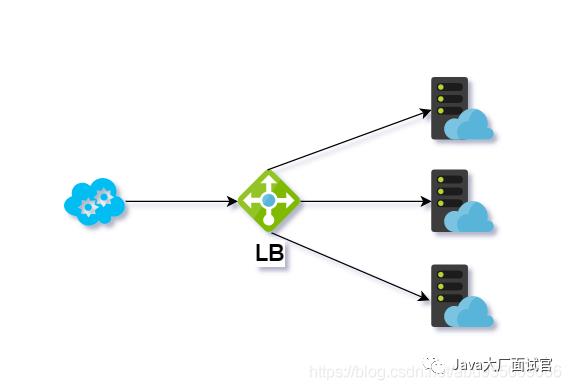
客户端负载均衡
再按照实现大类来分,负载均衡常见的种类有:软件负载均衡、硬件负载均衡、DNS负载均衡。
软件负载均衡
软件负载均衡是通过负载均衡软件来实现负载均衡功能的。常见的负载均衡软件有LVS和Nginx。其中LVS是Linux内核的四层负载均衡,四层和七层的区别在于他们协议和灵活性的不同。
-
四层负载均衡器在网络层和传输层协议( IP, TCP, FTP, UDP)的数据起作用。 -
七层负载均衡器在应用层协议(例如 HTTP)的数据分配请求。可以进一步基于应用程序特定的数据(例如HTTP标头,cookie或应用程序消息本身内的数据,例如特定参数的值)分发请求。【 重点】 -
LVS为四层负载均衡、Nginx、HAProxy既可以是四层负载均衡,也可以是七层负载均衡。 -
Nginx是万级别的,通常只用它来做七层负载,LVS来做四层负载。LVS是十万级别的。
硬件负载均衡
硬件负载均衡是通过单独的设备来实现负载均衡的功能,这类设备和路由器交换机有那么一些类似,更或者可以理解为一个用于负载均衡的基础网络设备。
目前业界主要有两款硬件负载均衡:F5和A10。这类设备性能好,功能强大,但是价格可以用昂贵来形容,一般只有银行,国企等大型有钱的企业开会考虑使用此类设备,
软件负载均衡和硬件负载均衡对比
| 硬件负载平衡器 | 软件负载平衡器 | |
|---|---|---|
| 价格 | 较昂贵,一般15w以上 | 一般免费 |
| 功能 | 功能较齐全,全面支持各层级的负载均衡,支持各种负载均衡算法,支持全局负载均衡 | 相对较少 |
| 性能 | 非常高,可以支持100W+以上的并发 | 较低,Nginx是W级别,LVS是10W级别 |
| 灵活性 | 不太灵活 | 更灵活,7层和4层负载均衡可以根据业务进行选择,也可以根据业务进行比较方便的扩展,比如:由于业务特殊性需要做一些定制化的功能。 |
| 安全性 | 高 | 低,没防火墙或者防DDos攻击等安全性功能 |
DNS负载均衡
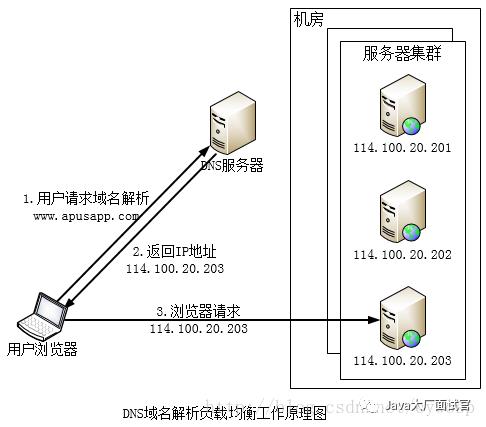
由上图可以看出,在DNS服务器中应该配置了多个A记录,如:
www.apusapp.com IN A 114.100.20.201;
www.apusapp.com IN A 114.100.20.202;
www.apusapp.com IN A 114.100.20.203;
优点:
-
将负载均衡的工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦。
-
技术实现比较灵活、方便,简单易行,成本低,使用于大多数TCP/IP应用。
-
对于部署在服务器上的应用来说不需要进行任何的代码修改即可实现不同机器上的应用访问。
-
服务器可以位于互联网的任意位置。
-
缺点:
-
目前的DNS是多级解析的,每一级DNS都可能缓存A记录,当某台服务器下线之后,即使修改了A记录,要使其生效也需要较长的时间,这段时间,DNS任然会将域名解析到已下线的服务器上,最终导致用户访问失败。
-
不能够按服务器的处理能力来分配负载。DNS负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异,不能反映服务器当前运行状态,所以其的负载均衡效果并不是太好。
-
事实上,大型网站总是部分使用DNS域名解析,利用域名解析作为第一级负载均衡手段,即域名解析得到的一组服务器并不是实际提供服务的物理服务器,而是同样提供负载均衡服务器的内部服务器,这组内部负载均衡服务器再进行负载均衡,请请求发到真实的服务器上,最终完成请求。
三、负载均衡算法
1. 健康检测(health checks)
我们有一个前提,就是流量只会被分配到健康的服务器上,那么负载均衡器怎么去判断服务器现在是否健康呢?
为了监控健康的服务器,健康检查一般会通过配置的协议和端口尝试去连接服务器来保证服务器正在监听。如果一个服务器的健康检查失败了,也就是说服务器无法正常响应请求,那么就会被自动的移除池子中,流量也不会被分配到这个坏掉的服务器直到它能通过健康检查。
2. 负载均衡如何处理状态
我们都知道基于session的用户认证会在服务器存有session的一些信息,但当系统引入负载均衡的时候这样会出现一些问题。
举个电商网站的例子,当用户U发送的登录请求被分发到了服务器S1并在服务器中记录了session信息,而当用户想要提交购物请求的时候这个请求被分发到了服务器S2,但服务器S2并没有保存用户U的session信息。
为了解决这个问题一个是可以使用IP hash算法,这个算法根据IP来分配流量对应的服务器,所以可以保证同一个用户的流量会访问到同一个服务器。另一个应用层的方法是sticky session,中文应该叫粘性会话,负载均衡器会设置一个cookie然后带有这个cookie的session都会被分配到同一个服务器上。
3. 负载均衡器如何选择后端服务器?
负载平衡器在将请求转发到后端服务器之前考虑两个因素。他们将首先确保他们选择的服务器实际上对请求做出了适当的响应,然后使用预先配置的算法从正常服务器中选择一个。常见的算法如下:
随机
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,
其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
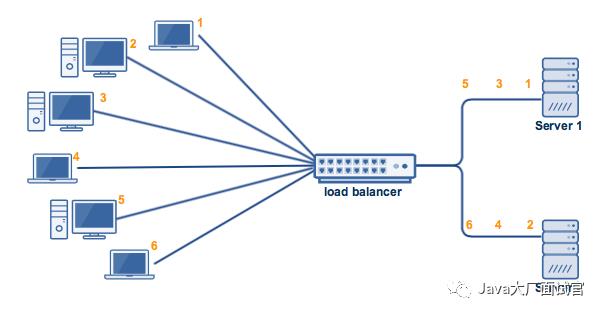
轮询
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
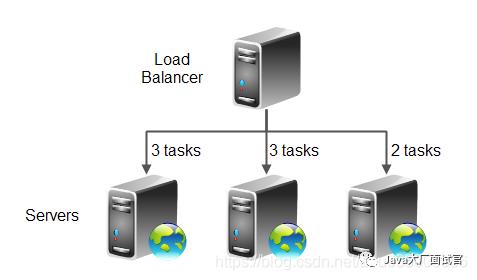
加权轮询
加权循环调度旨在更好地处理具有不同处理能力的服务器。每个服务器都分配有权重(指示处理能力的整数值)。权重较高的服务器比权重较小的服务器获得更多的连接到群集中的服务器上。这意味着您可以指定服务器应相对于其他服务器接收的任务的权重(比率)。如果群集中的服务器并非都具有相同的容量,这将很有用。
例如,如果三个服务器中有一个仅具有其他两个服务器的2/3容量,则可以使用weights 3, 3, 2。这意味着,每收到8个任务,第一个服务器应接收3个任务,第二个服务器应接收3个任务,而最后一个服务器应仅接收2个任务。这样,与群集中的其他服务器相比,具有2/3容量的服务器仅接收2/3任务。
IP哈希
最小连接数
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前
积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
一致性 Hash
相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
四、其他负载平衡方案
基于队列方案
所有任务都存储在任务队列中。服务器群集中的服务器连接到此队列,并接受它们可以处理的任务数。
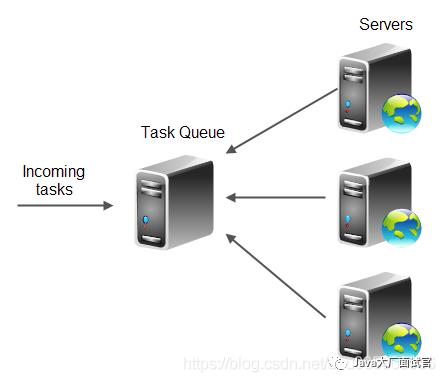
在此方案中,没有真正的负载平衡器,只有任务队列和服务器。每个服务器承担它能够处理的负载。如果服务器掉出群集,则其任务将在任务队列上保持未处理状态,并在以后由其他服务器处理。因此,每个服务器都可以独立于其他服务器和任务队列运行。负载均衡器不需要知道哪些服务器是集群等的一部分。任务队列不需要知道服务器。每个服务器只需要知道任务队列。
队列负载平衡还隐式考虑了每个服务器的工作负载和容量。服务器仅从队列中获取任务,然后它们才有能力对其进行处理。
五、自身高可用-负载均衡双机热备
负载均衡器本身就是一个单点故障隐患,其中一个解决方案就是双机热备(提高可用性的一大基本方法就是冗余)。
双机热备方案为了解决负载均衡器的单点故障问题,引入了第二个负载均衡器,当主节点挂了之后切换到备用节点。
这里的双机热备、故障转移,一般都是使用KeepAlive实现。
参考:
-
https://www.jianshu.com/p/253790f4aa20 -
https://www.cnblogs.com/bonelee/p/8890920.html -
https://www.educative.io
往期推荐
以上是关于系统设计基础 负载均衡的主要内容,如果未能解决你的问题,请参考以下文章