对库函数函数的一些总结
Posted 正义的伙伴啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对库函数函数的一些总结相关的知识,希望对你有一定的参考价值。
重点的库函数:
-
求字符串长度
- strlen
-
长度不受限制的字符串函数
- strcpy
- strcat
- strcmp
-
长度受限制的字符串函数介绍
- strncpy
- strncat
- strncmp
-
字符串查找
- strstr
- strtok
-
字符操作
-
内存操作函数
- memcpy
- memmove
- memcmp
strlen
size_t strlen(const char * str);
函数原理:
传过去一个指针,返回字符串在字符’\\0’之前的字符的个数。
注意事项:
注意事项:
- 字符串必须要以’\\0’结尾,否则会返回一个随机值(指针会一直读取后面的内存直到出现’\\0’为止)
- 注意函数返回参数为size_t无符号类型,例如下面这种情况:
#include<stdio.h>
#include<string>
int main()
{
const char* str1 = "abcdef";
const char* str2 = "bbb";
if (strlen(str2) - strlen(str1)>0)
{
printf("str2>str1\\n");
}
else
{
printf("str2<str1\\n");
}
return 0;
}

这里很明显str1的长度大于str2的长度,但是打印的结果说明strlen(str2) - strlen(str1)的结果大于0,实际上这里返回的类型是无符号类型,当表达式出现无符号数时会将所有有值转换成无符号数进行运算。
模拟实现strlen函数
,一下用三种方法实现:
循环实现
int my_strlen1(char* p) //正常的方法
{
int count = 0;
while (*p++)
{
count++;
}
return count;
}
循环指针自增直到出现’\\0’为止。
递归实现
int my_strlen2(char* p) //递归的方法
{
if (*p)
{
return my_strlen2(p + 1) + 1;
}
return 0;
}
递归的方法不用使用创建临时变量
指针减指针
int my_strlen3(char* p) //指针减指针的方法
{
char* cp = p;
while (*cp++)
{
;
}
return cp - p - 1;
}
这里利用的是指针的运算的性质。
strcpy
char * strcpy(char * destination, const char * source);
函数原理:
strcpy:将源头指针(source)所指向的数组包括’\\0’(并且拷贝停止于此),拷贝到目标数组(destination)中
注意事项:
- 源头字符串必须以’\\0’结束
- 目标空间必须足够大,以确保能放得下源字符串
- 目标空间不能是常量!
模拟实现
char* my_strcpy(char* p1, const char* p2)
{
char* p = p1;
while (*p1++ = *p2++)
{
;
}
return p;
}
strcat
char * strcpy(char * destination,const char * source)
函数原理:
将source指针指向的字符串(包括source结尾的’\\0’字符)添加到destination指针所指向的字符串后面,destination字符串结尾的’\\0’被source第一个字符替换。
注意事项:
- 源字符串必须以’\\0’结束
- 目标字符串必须足够的大,能容纳下源字符串的内容
- 目标空间不能是常量字符串(可修改)
- 不可以字符串给自己追加! (因为dest末尾的’\\0’会被source的第一个字符替换掉,导致source的’\\0’也被修改,最终strcat无法找到source末尾’\\0’的结束标志,使其死循环下去)
模拟实现
char* my_strcat(char *p1,char *p2)
{
char* p = p1; //记住起始地址
while (*p1)
{
*p1++;
}
while (*p1++ = *p2++)
{
;
}
return p;
}
分为两步:
- 找到dest字符串的’\\0’
- 从dest的’\\0‘开始向后面逐一拷贝
strcmp
int strcmp ( const char * str1,const char * str2 );
函数原理:
对str1和str2每个字符进行逐个比较,若相同,则继续往下比,直到出现不同或遇到’\\0’。
如果
- 第一个字符串大于第二个字符串,返回大于0的数字
- 第一个字符串小于第二个字符串,返回小于0的数字
- 第一个字符串等于第二个字符串,返回0
模拟实现:
int strcmp(const char* str1, const char* str2)
{
while ((*str1++ == *str2++)&&*str1&&*str2)
{
;
}
if (*str1 > * str2)
{
return 1;
}
else if (*str1 < * str2)
{
return -1;
}
else
{
return 0;
}
}
strncpy
char * strncpy(char * destination,const char * source,size_t num);
函数原理:
拷贝num个字符从源字符串到目标空间中,如果源字符串长度小于num则拷贝完源字符串之后,在目标的后边追加0,直到num个。
函数实现:
char* my_strncpy(char* p1, const char* p2, int n)
{
char* p = p1;
for (int i = 0; i < n; i++)
{
if (*p2)
{
*p++ = *p2++;
}
else
{
*p++ = '\\0';
}
}
return p1;
}
strncat
char * strncat(char * destination , const char *source , size_t num)
函数原理:
将num个source指向的字符拷贝到dest指向的字符串,拷贝开始于dest的出现的第一个’\\0’,结束于两种情况:

#include<assert.h>
char* my_strncat(char* p1, const char* p2, int num)
{
assert(p2 && p1);
char* pc = p1;
while (*p1)
{
p1++;
}
for (int i = 0; i < num; i++)
{
if (*p1 = *p2)
{
p1++;
p2++;
}
else
return pc; //num>source 的情况
}
*p1 = '\\0';
return pc;// num<source 的情况
}
strncmp:
int my_strncmp(char* p1, const char* p2, int num)
函数原理:
对str1和str2前num个字符进行逐个比较,若相同,则继续往下比,直到出现不同或遇到’\\0’。
如果
- 第一个字符串大于第二个字符串,返回大于0的数字
- 第一个字符串小于第二个字符串,返回小于0的数字
- 第一个字符串等于第二个字符串,返回0
函数实现:
#incldue<assert.h>
int my_strncmp(char* p1, const char* p2, int num)
{
assert(p1 && p2);
for (int i = 0; i < num; i++)
{
if (*p1 && *p2 && (*p1++ == *p2++));
else
{
if (*p1 > * p2)
return 1;
else if (*p1 < *p2)
return -1;
return 0;
}
}return 0;
}
strstr
const char* my_strstr(const char* p1, const char* p2)
函数原理:
p1里是否包含p2,如果是则返回p2在p1中第一个出现字符的地址,如果不包含则返回空指针。
模拟实现:
#incldue<assert.h>
const char* my_strstr(const char* p1, const char* p2)
{
assert(p1 && p2);
while (*p1 && *p2)
{
if (*p1 == *p2)
{
const char* a = p1;
const char* b = p2;
while (*a++ && *b++)
{
if (*a != *b)
break;
if (*a == *b && *(b+1) == 0)
return p1;
}
}
p1++;
}
return NULL;
}
strtok
char* strtok(char* str, const char* sep)
函数原理:
- sep参数是个字符串,定义了用作分隔的字符的集合
- 第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str中的下一个标记,并将其用\\0结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。
- strtok函数的第一个参数不为NULL,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
- strtok函数的第一个参数为NULL,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
- 如果字符串中不存在更多的标记,则返回NULL指针。
char* strtok1(char* str, const char* sep)
{
static int ret = 0;//这个静态变量也十分重要!当指针指向最后一个 字符串str 出现的 sep字符分隔符,
//因为最后一段字符串并不会再出现sep中任何一个分隔符,所以字符串就不会打印,
//那我们如何区分这种情况和str中就从来没有出现过sep字符的情况,我们设置一个静态变量,如果静态变量被修改过,就输出字符串,如果没修改过就返回空指针。
static char* a = NULL; //这里要用到静态变量,这样函数结束变量就不会销毁,a会记住上一次的地址
if (str != NULL) // 判断是否为NULL
{
a = str;
ret = 0;
}
else
{
if (ret == 2)
return NULL;
a++;
}
char* first = a;
while (*a)
{
const char* p = sep;
while (*p)
{
if (*p == *a)
{
*a = '\\0';
ret = 1;
return first;
}
p++;
}
a++;
if (*a == '\\0')
{
ret = 2;
break;
}
}
if (ret == 0)
return NULL;
else if(ret == 2)
return first;
}
代码示例:
char* my_strtok(char* str, const char* sep)
{
static int ret = 0;//这个静态变量也十分重要!当指针指向最后一个 字符串str 出现的 sep字符分隔符,
//因为最后一段字符串并不会再出现sep中任何一个分隔符,所以字符串就不会打印,
//那我们如何区分这种情况和str中就从来没有出现过sep字符的情况,我们设置一个静态变量,如果静态变量被修改过,就输出字符串,如果没修改过就返回空指针。
static char* a = NULL; //这里要用到静态变量,这样函数结束变量就不会销毁,a会记住上一次的地址
if (str != NULL) // 判断是否为NULL
{
a = str;
ret = 0;
}
else
{
if (ret == 2)
return NULL;
a++;
}
char* first = a;
while (*a)
{
const char* p = sep;
while (*p)
{
if (*p == *a)
{
*a = '\\0';
ret = 1;
return first;
}
p++;
}
a++;
if (*a == '\\0')
{
ret = 2;
break;
}
}
if (ret == 0)
return NULL;
else if(ret == 2)
return first;
}
int main()
{
char a[] = "everything is simple";
char b[] = " ";
char c[] = "1345424480@qq.com";
char d[] = "@.";
printf("%s\\n", my_strtok(a, b));
printf("%s\\n", my_strtok(NULL, b));
printf("%s\\n", my_strtok(c, d));
printf("%s\\n", my_strtok(NULL, d));
printf("%s\\n", my_strtok(NULL, d));
return 0;
}
结果:

strerror
char * strerror ( int errnom );
函数原理:
- 返回错误码,所对应的错误信息。
- 使用库函数调用失败的时候,都会设置错误码,并存储到errno中(errno是一个全局变量,在使用时必须引用头文件<errno.h>)
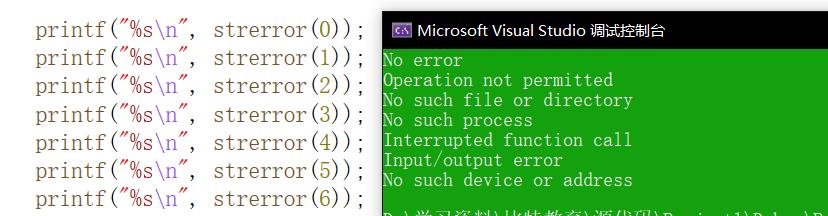
代码运用:
#include<stdio.h>
#include<string.h>
#include<errno.h>
int main()
{
FILE* pFILE;
pFILE = fopen("unexist.ent", "r");
if (pFILE == NULL)
printf("Error opening file unexist.ent: %s\\n", strerror(errno));
return 0;
}
字符操作函数:
字符分类函数
| 函数名 | 返回值为真的返回条件 |
|---|---|
| iscntrl | 任何控制字符。 |
| isdigit | 十进制数字0~9 |
| isspace | 空白字符:空格’ ‘,换页’\\f’,换行’\\n’,回车’\\r’,制表符’\\t’或者垂直制表符’\\v’ |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母a~f,大写字母A ~ F。 |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母a~z或A ~ Z |
| isalnum | 字母或数字,az,AZ,0~9。 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印)。 |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图型字符和空白字符。 |
注意:左边为函数名,右边是返回值为真的返回条件,字符函数一般都是有int类型的返回值,且调用字符分类函数一定要引头文件ctype.h
字符转换:
int tolower ( int c ); 把大写转换成小写
int toupper ( int c ); 把小写转换成大写
字符分类函数的应用:
这里列举一个实例:大写变小写
#include<stdio.h>
#include<ctype.h>
int main()
{
char arr[] = "abBBsjJSBHdlDLKDjdef";
char c;
int i = 0;
while (arr[i])
{
c = arr[i];
if (isupper(arr[i]))
c = tolower(arr[i]);
putchar(c);
i++;
}
return 0;
}
memcpy
void* my_memcpy(void* destination, const void* source, size_t num)
函数原理:
- 函数memcpy从source的位置开始向后复制复制num个字节的数据到destination的内存位置。
- 这个函数在遇到’\\0’的时候并不会停下来
- 如果source和destination有任何的重叠,复制的结果都是未定义的。
- memmcpy对于strcpy的优点是可以拷贝任意类型的数据。
模拟实现:
void* my_memcpy(void* destination, const void* source, size_t num)
{
void* p = destination;
for (unsigned int i = 0; i < num; i++)
{
*(char*)destination = *(char*)source; //强制类型转换成char *类型逐字节拷贝
destination = (char*)destination + 1;
source = (char*)source + 1;
}
return p;
}
memmove
函数原理:
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理
函数实现:
因为memmove可以拷贝内存重叠的字符串,所以我们主要考虑内存重叠的状况:
情况一:source < dest
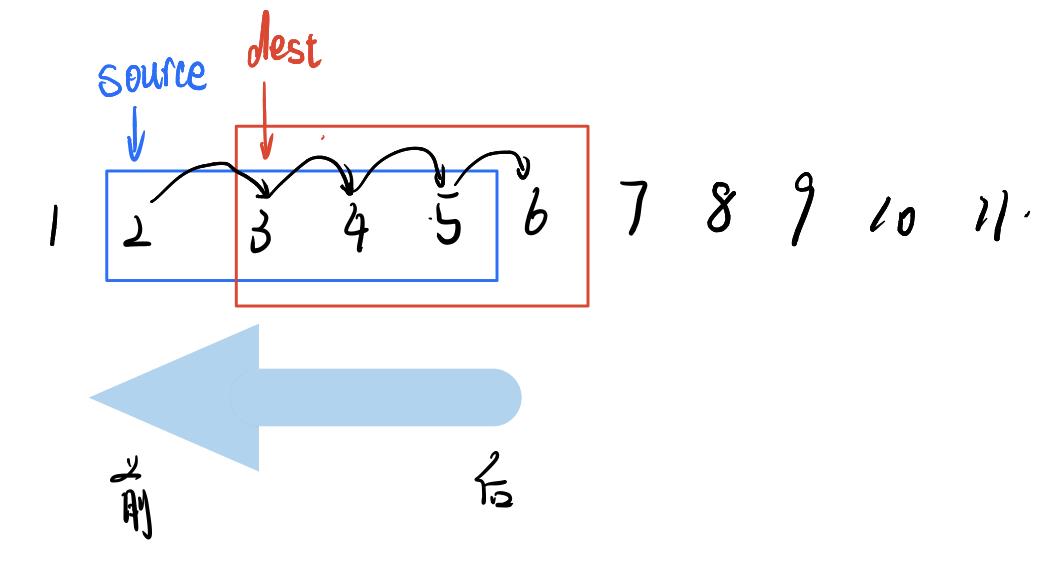
有图可知拷贝方向应从source字符串的后向前。
情况二 source > dest
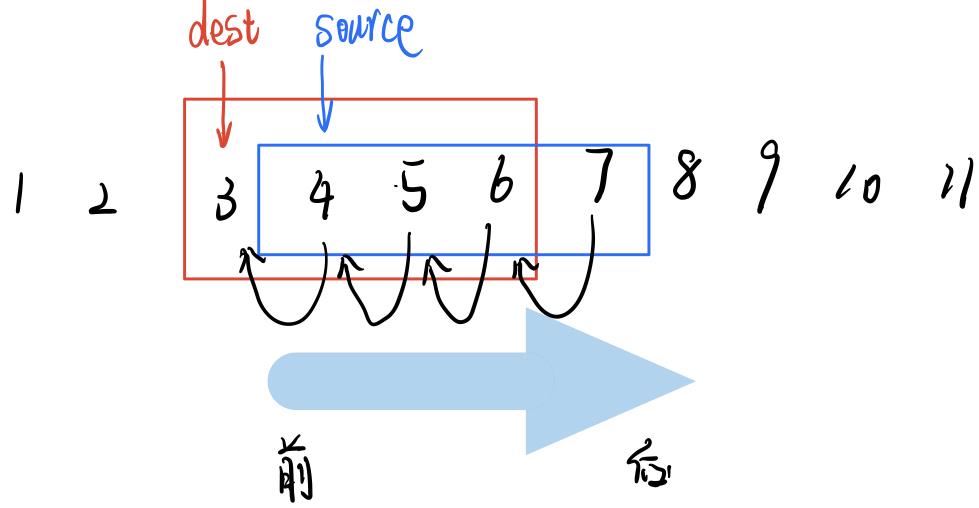
由图可知拷贝方向是从source字符串的前向后:
当source与dest没有重叠部分的时候,source从左向右和从右向左并没有什么区别。
void* my_memmove(void* destination, const void* source, size_t num)
{
void* p = destination;
if (destination > source) //从后向前拷贝
{
while (num--以上是关于对库函数函数的一些总结的主要内容,如果未能解决你的问题,请参考以下文章