K8s 中优雅停机和零宕机部署
Posted K8sMeetup社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8s 中优雅停机和零宕机部署相关的知识,希望对你有一定的参考价值。
创建、删除 Pod 是 K8s 中最常见的任务之一。本文介绍了 Pod 在响应创建、删除请求时发生的内部流程,还讨论了如何在 Pod 启动或关闭时防止断开连接,以及如何正常关闭长时间运行的任务。
翻译:Bach(才云)
校对:bot(才云)、星空下的文仔(才云)
-
关闭前的请求是否已完成? -
接下来的请求又如何呢?
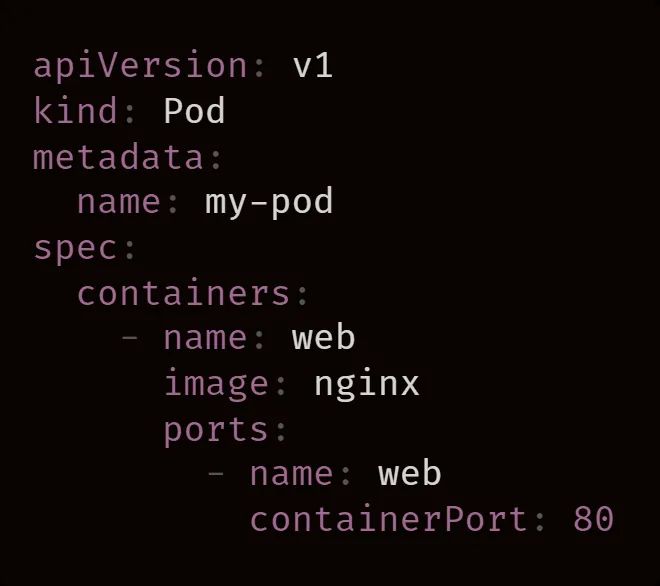
在输入命令后,kubectl 就会将 Pod 定义提交给 Kubernetes API。
在数据库中保存集群状态
API 接收并检查 Pod 定义,然后将其存储在 etcd 数据库中。另外,Pod 将被添加到调度程序的队列中。
-
在 etcd 中的 Pod 会被标记为 Scheduled。 -
Pod 被分配到一个节点。 -
Pod 的状态会存储在 etcd 中。
Kubelet
kubelet 的工作是轮询控制平面以获取更新。kubelet 不会自行创建 Pod,而是将工作交给其他三个组件:
-
容器运行时接口(CRI) :为 Pod 创建容器的组件。 -
容器网络接口(CNI) :将容器连接到集群网络并分配 IP 地址的组件。 -
容器存储接口(CSI) :在容器中装载卷的组件。

-
为 Pod 生成有效的 IP 地址。 -
将容器连接到网络。
如果 Pod 不是任何 Service 的一部分,那到这里就结束了,因为 Pod 已经创建完毕并可以使用,但如果 Pod 是 Service 的一部分,那还有几个步骤需要执行。
Pod 和 Service
在创建 Service 时,我们需要注意两点信息:
-
selector :指定接收流量的 Pod。 -
targetPort :通过 Pod 端口接收流量。
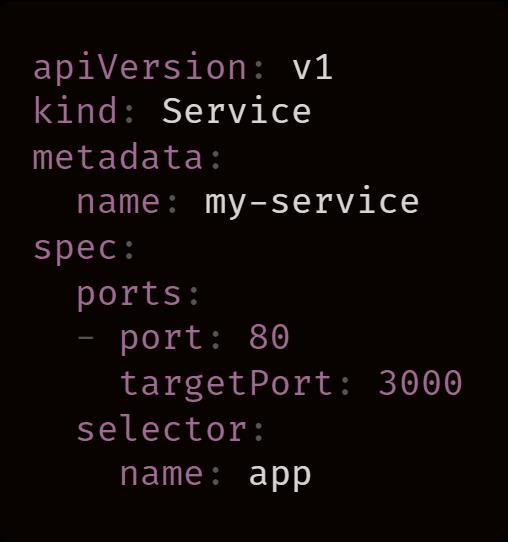
kubectl apply
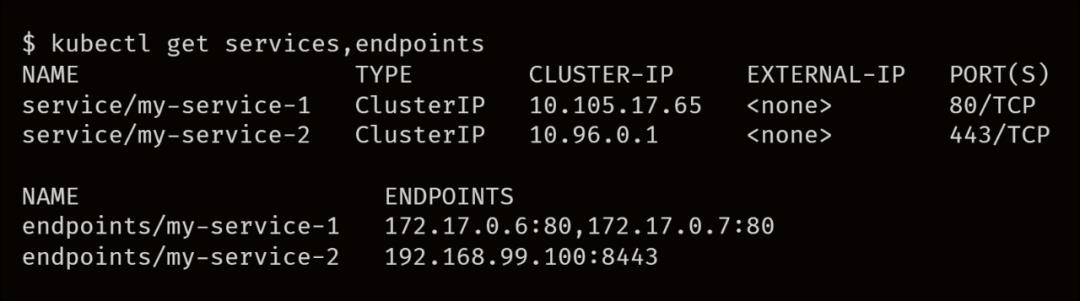
将 Service 提交给集群时,Kubernetes 会找到所有和选择器(name: app)有着相同标签的 Pod,并收集其 IP 地址,当然它们需要先通过 Readiness 探针,然后再将每个 IP 地址都和端口连接在一起。
10.0.0.3
,
targetPort
是 3000,Kubernetes 会将这两个值连接起来称为 endpoint。
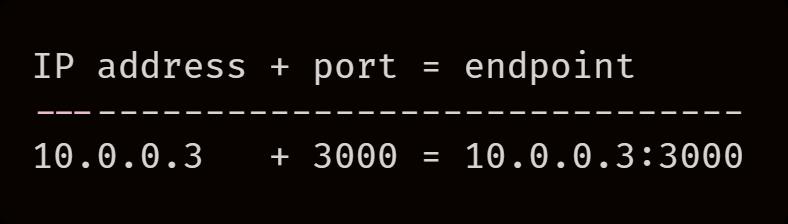
-
endpoint(e 小写)=IP 地址 + 端口(10.0.0.3:3000)。 -
Endpoint(E 大写)是 endpiont 的集合。
-
Pod 创建时。 -
Pod 删除时。 -
在 Pod 上修改标签时。
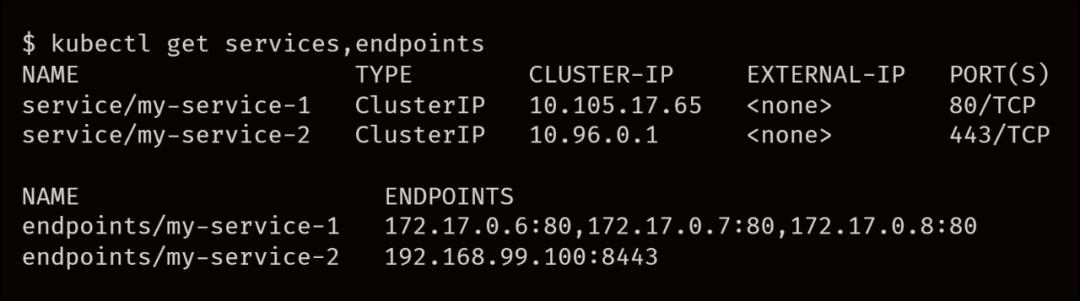
endpoint 存储在控制平面中,Endpoint 对象也会更新。
在 Kubernetes 中使用 endpoint
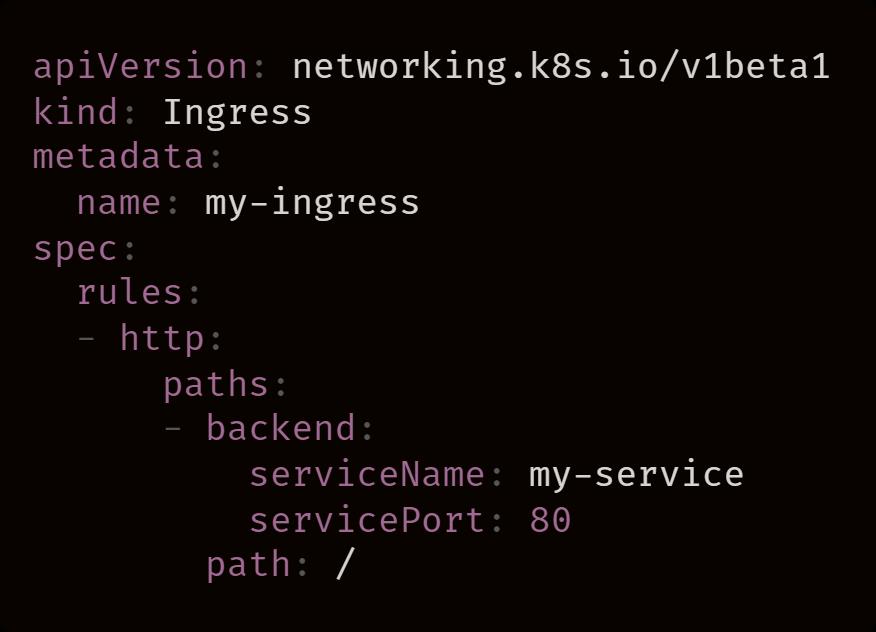
删除 Pod
优雅停机
terminationGracePeriodSeconds
)。如果我们无法更改代码以获得更长的等待时间要怎么办?我们可以调用脚本以获得固定的等待时间,然后退出应用程序。
preStop
hook。我们可以将
preStop
hook 设置为等待 15 秒。下面是一个例子:
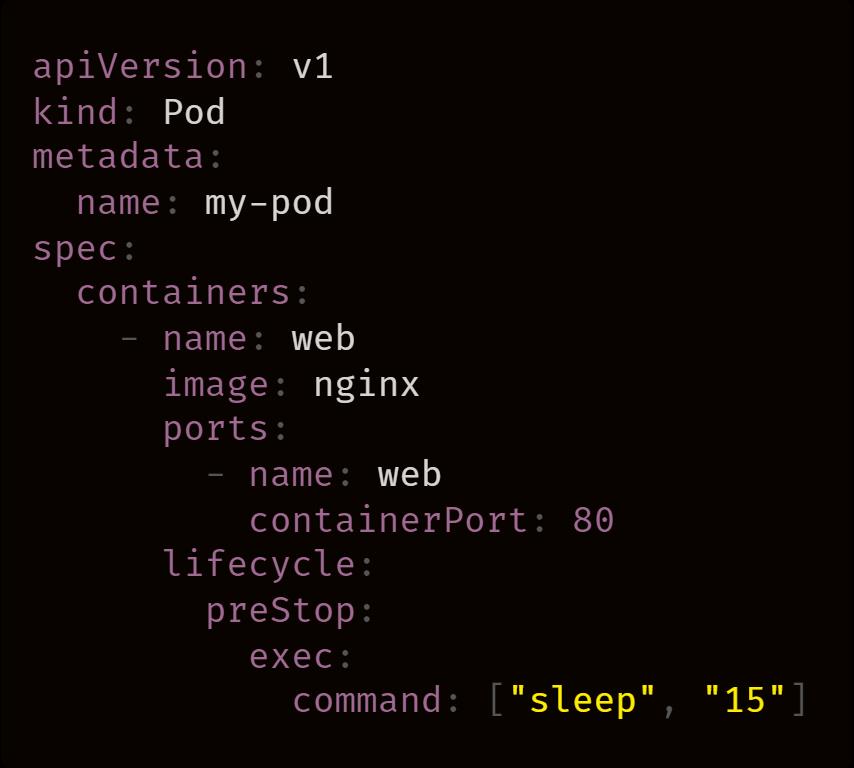
preStop hook 是 Pod LifeCycle hook 之一。
宽限期和滚动更新
优雅停机适用于要删除的 Pod,但如果我们不删除 Pod,会怎么样?其实即使我们不做,Kubernetes 也会删除 Pod。在每次部署较新版本的应用程序时,Kubernetes 都会创建、删除 Pod。
1.用新的容器镜像创建一个 Pod。
2.销毁现有的 Pod。
3.等待 Pod 准备就绪。
它会不断重复上述步骤,直到将所有 Pod 迁移到较新的版本。Kubernetes 在新 Pod 准备接收流量之后会重复每个周期。另外,Kubernetes 不会在转移 Pod 前等待 Pod 被删除。如果我们有 10 个 Pod,并且 Pod 需要 2 秒钟的准备时间和 20 秒的关闭时间,就会发生以下情况:
1.创建一个 Pod,终止前一个 Pod。
2.Kubernetes 创建一个新的 Pod 后,需要 2 秒钟的准备时间。
3.同时,被终止的 Pod 会有 20 秒的停止时间。
终止长时间运行的任务
如果我们要对大型视频进行转码,是否有任何方法可以延迟停止 Pod?
terminationGracePeriodSeconds
增加到几个小时,但这样 Pod 的 endpoint 将 unreachable。如果我们公开指标以监控 Pod,instrumentation 将无法访问 Pod。Prometheus 之类的工具依赖于 Endpoints 在集群中 scrape Pod。一旦删除 Pod,endpoint 删除信息就会在集群中传播,甚至传播到 Prometheus。
如果想自动删除,那我们可以需要设置一个自动伸缩器,当它们完成任务时,可以将 Deployment 扩展到零个副本。
总结

推荐阅读:
以上是关于K8s 中优雅停机和零宕机部署的主要内容,如果未能解决你的问题,请参考以下文章