生活这么无聊,保存点小姐姐图片作为调料吧(多线程版本)
Posted 一腔诗意醉了酒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生活这么无聊,保存点小姐姐图片作为调料吧(多线程版本)相关的知识,希望对你有一定的参考价值。
0、缘起
自从【生活这么无聊,保存点小姐姐的图片来点调料吧】出来,不少大哥都跟我反映下载速度太慢了,所以趁着今天摸鱼时间,补充一下多线程版本吧。
使用的技术栈 : python3, re, BeautifulSoup、python2的_thread、python3的threading
目标网站: https://www.umei.net/p/gaoqing/cn/
不了解多线程的,可以先了解一下下哦,推荐:Python3 多线程
免责声明:仅用于学习,请勿商用!!!!
1. 线程关系拓扑
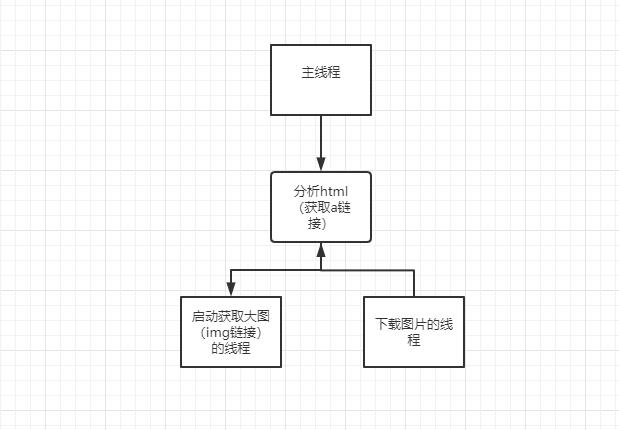
2. 代码实现
import requests
import re
from bs4 import BeautifulSoup
import _thread # python2 的多线程
import threading # python3 的多线程
imgs = [] # 保存a链接的列表
ans_imgs = [] # 保存图片大图的列表
cnt = 0
def downloadImg(cc):
while(len(ans_imgs)==0):
pass
k = ans_imgs.pop()
b = requests.get(str(k))
if(b.status_code==200):
with open('./pics/'+str(cc)+'.jpg','wb+') as f:
f.write(b.content)
'''
target: 获取图片的大图链接
params: a链接的url
'''
class get_ans_imgs( threading.Thread ):
def __init__( self ):
threading.Thread.__init__(self)
def run( self ):
k = imgs.pop()
src= str(url + k)
ans = requests.get( src )
if(ans.status_code==200):
soup1 = BeautifulSoup(ans.content, 'html5lib')
imgBody = soup1.select('.ImageBody img')
print(imgBody)
# 获取大图的src
obj = re.search('.*?src="(.*?)"', str(imgBody), re.M | re.I )
ans_imgs.append( obj.group(1))
url = 'https://www.umei.net/p/gaoqing/cn/'
r = requests.get(url)
# with open('./meinv.html','wb+') as f:
# f.write(r.content)
if(r.status_code == 200 ):
soup = BeautifulSoup(r.content, 'html5lib')
# 获取img外面的a标签
aList = soup.select('.TypeBigPics')
for item in aList:
# print( type (item) )
obj = re.search('.*?\\/cn\\/(.*?)".*', str(item), re.M | re.I )
imgs.append( str( obj.group(1)) )
print(imgs)
while( len(imgs)!=0 ):
thread1 = get_ans_imgs( )
thread1.start()
cnt += 1
print("正在下载第" + str(cnt) + "张图片")
_thread.start_new_thread( downloadImg(cnt))
# # 保存大图
print("完结撒花")
3. 注意
在启动程序之前要先创建一个pics文件夹哦,或者自己更改一下下路径。
4. 结果
少年不宜就不放啦
以上是关于生活这么无聊,保存点小姐姐图片作为调料吧(多线程版本)的主要内容,如果未能解决你的问题,请参考以下文章