-编译原理-
Posted zhixuChen333
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了-编译原理-相关的知识,希望对你有一定的参考价值。
状态转换矩阵、FIRST和FOLLOW怎么求等,看B站,书和我们一样
https://www.bilibili.com/video/BV1Ar4y1M7vG?t=224&p=7(博主书和我们一样,讲的挺好)
第一章
一、叙述编译程序结构框架。
1.词法分析器,又称扫描器,输入源程序,进行词法分析,输出单词符号。
2.语法分析器,又称分析器,对单词符号串进行语法分析(根据语法规则进行推导或规约),识别出各类语法单位,最终判断输入串是否构成语法上正确的“程序”。
3.语义分析与中间代码产生器,按照语义规则对语法分析器归约(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间代码。
4.优化器,对中间代码进行优化处理。
5.目标代码生成器,把中间代码翻译成目标程序。
二、什么是编译的前端和后端?
前端:主要由与源语言有关但与目标机无关的哪些部分组成。这些部分通常包括词法分析、语法分析、语义分析与中间代码产生,有的代码优化工作也可以包括在前端。
后端:包括编译程序中与目标机有关的那些部分,如与目标机有关的代码优化和目标代码生成等。
三、编译过程的五个阶段,哪些阶段是与硬件无关,哪一些是与硬件相关的?
与硬件无关:词法分析器、语法分析器
与硬件相关:语义分析与中间代码产生器、优化器、目标代码生成器
第二章
一、描述乔姆斯基四型文法。
乔姆斯基把文法分成四种类型,即0型、1型、2型和3型。
- 0型文法也称短语文法。它的能力相当于图灵机。任何0型语言都是递归可枚举的;反之,递归可枚举集必定是一个0型语言。
- 1型文法也称上下文有关文法。一般不允许替换成空串ε。G:αAβ→αγβ,也就是说,A推导出γ是和上下文α,β相关的,即A只有在上下文α,β的环境中才能推导出γ。
- 2型文法也称上下文无关文法。G:A→γ,A可以无条件的推导出γ,和上下文无关。
- 3型文法也称右线性文法(左线性文法)。或者称为正规文法,等价于正规式(正则表达式),G:A→Bα或A→α。
二、什么是句型、句子?
假定G是一个文法,S是它的开始符号。如果S*=>α,则称α是一个句型。仅含终结符号的句型是一个句子。
三、什么是语言?用形式语言描述什么是语言。
文法G所产生的句子的全体是一个语言,将它记为L(G)。
L(G)={α|S+=>α&α∈V*T}
第三章
一、请用状态图和正规式描述标识符。
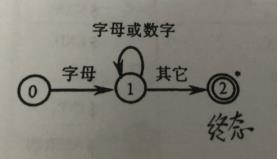
从初态0开始,若在状态0之下输入字符是一个字母,则读进它,并转入状态1.在状态1下,若输入字符为字母或数字,则读进它,并重新进入状态1。一直重复这个状态,直到状态1发现输入字符不在是字母或数字时就进入终态2,这意味着到此已识别出一个标识符。
正规式:令Σ={A,B,0,1},则正规式:(A|B)(A|B|0|1)* ,正规集:Σ上的“标识符”全体
二、确定有限自动机的形式化描述。
一个确定有限自动机(DFA)M是一个五元式 M=(S,Σ,δ,s0,F),其中:
(1)S是一个有限集,它的每个元素称为一个状态。
(2)Σ是一个有穷字母集,它的每个元素称为一个输入字符。
(3)δ是一个从S×Σ至S的单值部分映射。δ(s,a)=s’意味着:当现行状态为s、输入字符为a时,将转换带下一状态s’。我们称s’为s的一个后继状态。
(4)s0∈S,是唯一的初态。
(5)F⊆S,是一个终态集(可空)。
三、非确定有限自动机的形式化描述
一个非确定有限自动机(NFA)M是一个五元式 M=(S,Σ,δ,s0,F),其中:
(1)S是一个有限集,它的每个元素称为一个状态。
(2)Σ是一个有穷字母集,它的每个元素称为一个输入字符。
(3)δ是一个从S×Σ到S的子集的映照,即δ:S×Σ*→2S。
(4)s0∈S,是一个非空初态集。
(5)F⊆S,是一个终态集(可空)。
四、什么是lex?
一个描述词法分析器的LEX程序由一组正规式以及与每个正规式相应的一个“动作”组成。“动作”本身是一小段程序代码,它指出了当按正规式识别出一个单词符号时应采取的行动。将LEX程序被编译后所得的结果程序记为L,其作用就如同一个有限自动机一样,可用来识别和产生单词符号。结果程序含有一张状态转换表和一个控制程序。
五、64页12题
第四章
一、自上而下语法分析为什么要消除左递归?如何消除左递归?
因为含有左递归的文发将使自上而下的分析过程陷入无限循环。
左递归的消除 ,记住公式,假定关于非终极符P的规则为:
P->Pα|β
那么我们可以将P的规则改写为如下的非直接递归形式:
P->βP’
P’->αP’|ε
二、自上而下语法分析为什么要消除算法的回溯?
由于回溯,就会碰到一大堆麻烦的事情。如果我们走了一大段错路,最后必须回头,那么,就应把已经做的一大堆语义工作(指中间代码产生工作和各种表格的薄记工作)推倒重来。这些事情既麻烦又费时间,所以,最好应设法消除回溯。
三、请写出First集和Follow集的形式化定义。
令G是一个不含左递归的文法,对G的所有非终结符的每个候选α定义它的首符集FIRST(α)为
FIRST(α)={a|α=>a…,a∈Vt}
设定S是文法G的开始符号,对于G的任何非终结符号A,我们定义
FOLLOW(A)={a|S=>…Aa…,a∈Vt}
四、什么是LL(1)文法?
1.文法不含左递归
2.对于文法中每一个非终结符A的各个产生式的候选首符集两辆不相交。即,若A->a1|a2|a3|…|an
则 FIRST(αi)∩ FIRST(αj) = 空集 (i!=j)
3.对文法中每一个非终结符A,若它存在某个候选首符集包含ε,则:
FIRST(A) ∩ FOLLOW(A)=空集
如果一个文法满足上面条件,则称该文法G为LL(1)文法。
LL(1)中的第一个L表示从左到右扫描输入串,第二个L表示最左推导,1表示分析时每一步只需向前查看一个符合。
五、简述LL(1)分析的基本思想。
为构造不带回溯的自上而下分析算法,首先要消除文法的左递归性,并找出克服回溯的充分必要条件。
六、递归下降分析有什么优缺点?
用这种定义系统来描述语法的好处是,直观易懂,便于表示左递归消去和因子提取。对于构造自上而下分析器来说,采用这种定义系统描述文法显然是非常可取的。
解答题:
1、简单总结描述第76页,5节有关LL(1)分析过程。
2、第82页第3题

第五章

第六章
什么是属性文法?什么是综合属性?什么是继承属性?
属性文法:属性文法(也称属性翻译文法)是在上下文无关文法的基础上,为每个文法符号(终结符或非终结符)配备若干相关的“值”(称为属性)。这些属性代表与文法符号相关信息,例如它的类型、值、代码序列、符号表内容等等。
综合属性:在语法树中,一个结点的综合属性的值由其子节点的属性值确定。因此,通常使用自底向上的方法在每一个结点处使用语义规则计算综合属性的值。仅仅使用综合属性的属性文法称S-属性文法。
继承属性:在语法树中,一个结点的继承属性由此结点的父结点和/或兄弟结点的某些属性确定。用继承属性来表示程序设计语言结构中的上下文依赖关系很方便。
第七章
中间代码生成对编译器构造的意义是什么?
(1) 便于进行与机器无关的代码优化工作;
(2) 使编译程序改变目标机更容易;
(3) 使编译程序的结构在逻辑上更为简单明确。以中间语言为界面,编译前端和后端的接口更清晰。
第十章
代码优化的原则是什么?
优化的目的是为了产生更高效的代码。
原则:
(1)等价原则。经过优化后不应改变程序运行的结果。
(2)有效原则。使优化后所产生的目标代码运行时间较短,占用的存储空间较小。
(3)合算原则。应尽可能以较低的代价取得较好的优化效果。
第十一章
代码生成器的输出是目标程序,目标程序有哪几种形式?
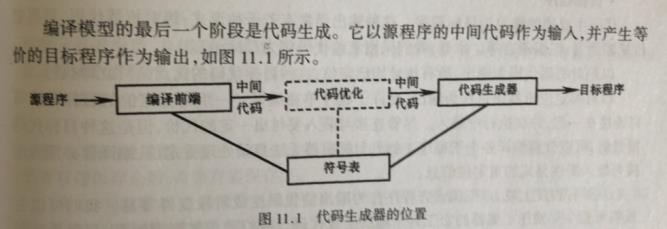
代码生成器的输入包括中间代码和符号表中的信息。
代码生成是把语义分析后或优化后的中间代码变换成目标代码。一般有以下三种形式:
(1)能够立即执行的机器语言代码,所有地址均已定位(代真)。
(2)带装配的机器语言模块。带需要执行时,由连接装入程序把它们和某些运行程序连接起来,转换成能执行的机器语言代码。
(3)汇编语言代码,尚需经过汇编程序汇编,转换成可执行的机器语言代码。
以上是关于-编译原理-的主要内容,如果未能解决你的问题,请参考以下文章