JVM 类加载机制全面解析,一篇完整彻底搞懂
Posted 小乔不掉发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM 类加载机制全面解析,一篇完整彻底搞懂相关的知识,希望对你有一定的参考价值。
1、概述:

2、类的生命周期:
包括7个阶段: 加载、验证、准备、解析、初始化、使用 和 卸载。
(其中验证、准备、解析3个部分统称为连接(Linking))
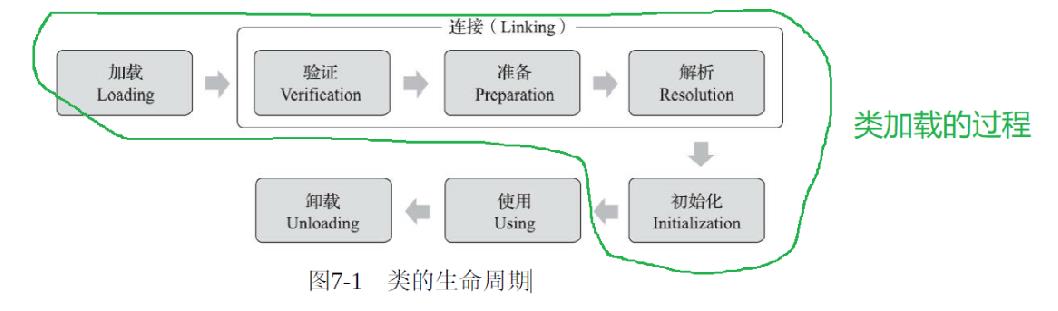
解析阶段 在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。
加载:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
(方法区:JDK1.7在 Java 进程,1.8是本地内存(名称改为元空间/元数据区)) - 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
验证:
这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
(规范验证、安全验证)
准备:
准备阶段是正式为 类变量 分配内存并设置类变量 初始值 的阶段,这些变量所使用的内存都将在方法区中进行分配。
假设一个类变量的定义为:
public static int value=123;
那变量value在准备阶段过后的初始值为0而不是123,因为这时候尚未开始执行任何Java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器 < clinit >() 方法之中,所以把value赋值为123的动作将在初始化阶段才会执行。
解析:
虚拟机将常量池内的符号引用替换为直接引用的过程。
- 符号引用:符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。
- 直接引用:直接引用是和虚拟机实现的内存布局相关的。如果有了直接引用,那引用的目标必定已经在内存中存在。
初始化:
在准备阶段,变量已经赋过一次系统要求的初始值,而在初始化阶段,则根据程序员通过程序制定的主观计划去初始化类变量和其他资源,或者可以从另外一个角度来表达:初始化阶段是执行类构造器 < clinit >() 方法的过程
(该方法为 Class对象的构造方法)
- < clinit >() 方法是由编译器自动收集类中的 所有类变量的赋值动作和静态语句块(static{}块)中的语句合并产生 的,编译器 收集的顺序 是由 语句在源文件中出现的顺序 所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问:
public class Test{
static{
i=0; //给变量赋值可以正常编译通过
System.out.print(i); //这句编译器会提示"非法向前引用"
}
static int i=1;
}
- < clinit >() 方法与类的构造函数(或者说实例构造器()方法)不同,它不需要显式地调用父类构造器,虚拟机会保证在 子类的< init >()方法执行之前,父类的< clinit >()方法已经执行完毕。因此在虚拟机中第一个被执行的()方法的类肯定是 java.lang.Object。
- < clinit >() 方法对于类或接口来说并不是必需的,如果一个类中 没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成()方法。
- 接口中定义的变量使用时,接口才会初始化:接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生< clinit >()方法。但接口与类不同的是,执行接口的< clinit >()方法不需要先执行父接口的< clinit >()方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的< clinit >()方法。
- 虚拟机会保证一个类的< clinit >()方法在多线程环境中被正确地加锁、同步,如果 多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的< clinit >()方法,其他线程都需要阻塞等待,直到活动线程执行< clinit >()方法完毕。如果在一个类的< clinit >()方法中有耗时很长的操作,就可能造成多个进程阻塞,在实际应用中这种阻塞往往是很隐蔽的。
父子类的执行顺序:

补充:
对象的构造方法编译为字节码 < init >,也是类似 < clinit > 收集的过程
(收集 成员变量 + 实例代码块 + 构造方法)
3、类加载器:
类加载器可以分为:启动类加载器、扩展类加载器、应用程序类加载器、自定义类加载器。他们的关系一般如下:
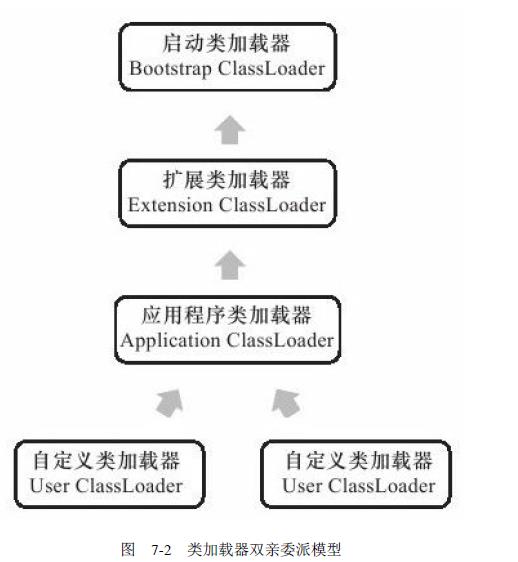
启动类加载器:
这个类将器负责将存放在<JAVA_HOME>\\lib 目录中的类库加载到虚拟机内存中
扩展类加载器:
这个加载器由sun.misc.Launcher $ExtClassLoader实现,它负责加载<JAVA_HOME>\\lib\\ext 目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
应用程序类加载器:
这个类加载器由sun.misc.Launcher $App-ClassLoader实现。由于这个类加载器是 ClassLoader 中的 getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
4、类加载机制 — — 双亲委派机制
工作过程:
如果一个类加载器收到了类加载的请求,它首先 不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
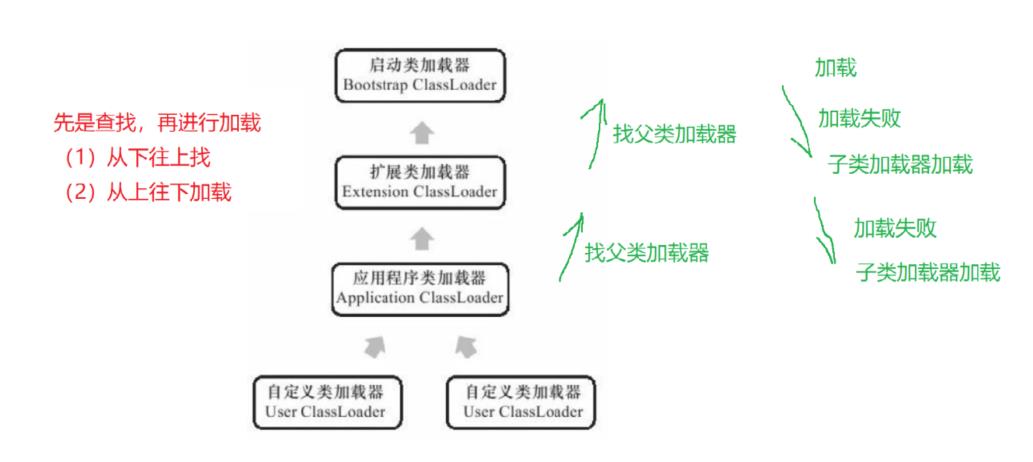
使用双亲委派机制:
- 好处 :保证 Java 程序的稳定运作
如果没有使用双亲委派模型,由各个类加载器自行去加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,Java类型体系中最基础的行为也就无法保证,应用程序也将会变得一片混乱。 - 劣势:无法满足灵活的类加载方式
(解决方案:自己重写 loadClass 破坏双亲委派模型)
实现:
实现双亲委派的代码都集中在 java.lang.ClassLoader 的 loadClass () 方法之中,逻辑清晰易懂:先检查是否已经被加载过,若没有加载则调用父加载器的 loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的 findClass()方法进行加载。
以下为ClassLoader中的代码:

双亲委派的具体逻辑就实现在这个方法之中,JDK1.2 之后已不提倡用户再去覆盖 loadClass()方法,而应当把自己的类加载逻辑写到findClass()方法中,在 loadClass()方法的逻辑里如果父类加载失败,则会调用自己的 findClass()方法来完成加载,这样就可以保证新写出来的类加载器是符合双亲委派规则的。
- 重写loadClass():不遵循双亲委派机制,按照自己的方式加载
- 重写findClass():遵循双亲委派机制,只有父类找不到时,才按照自己的方式加载
类加载器给⽤用户提供最⼤大的帮助为:可以通过动态的路径进行类的加载操作。
比较两个类相等的前提:必须是由同一个类加载器加载的前提下才有意义。否则,即使两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载他们的类加载器不同,那么这两个类注定不相等。
以上是关于JVM 类加载机制全面解析,一篇完整彻底搞懂的主要内容,如果未能解决你的问题,请参考以下文章