Python数据可视化之散点图(进阶篇---图文并茂详细版!!!)
Posted 温柔且上进c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据可视化之散点图(进阶篇---图文并茂详细版!!!)相关的知识,希望对你有一定的参考价值。
数据获取
•进阶散点图可视化需要大量的数据,网上有很多获取数据的来源,在这里我们可以从GitHub中获取我们想要的数据!!!
•数据来源GitHub:https://github.com/selva86/datasets
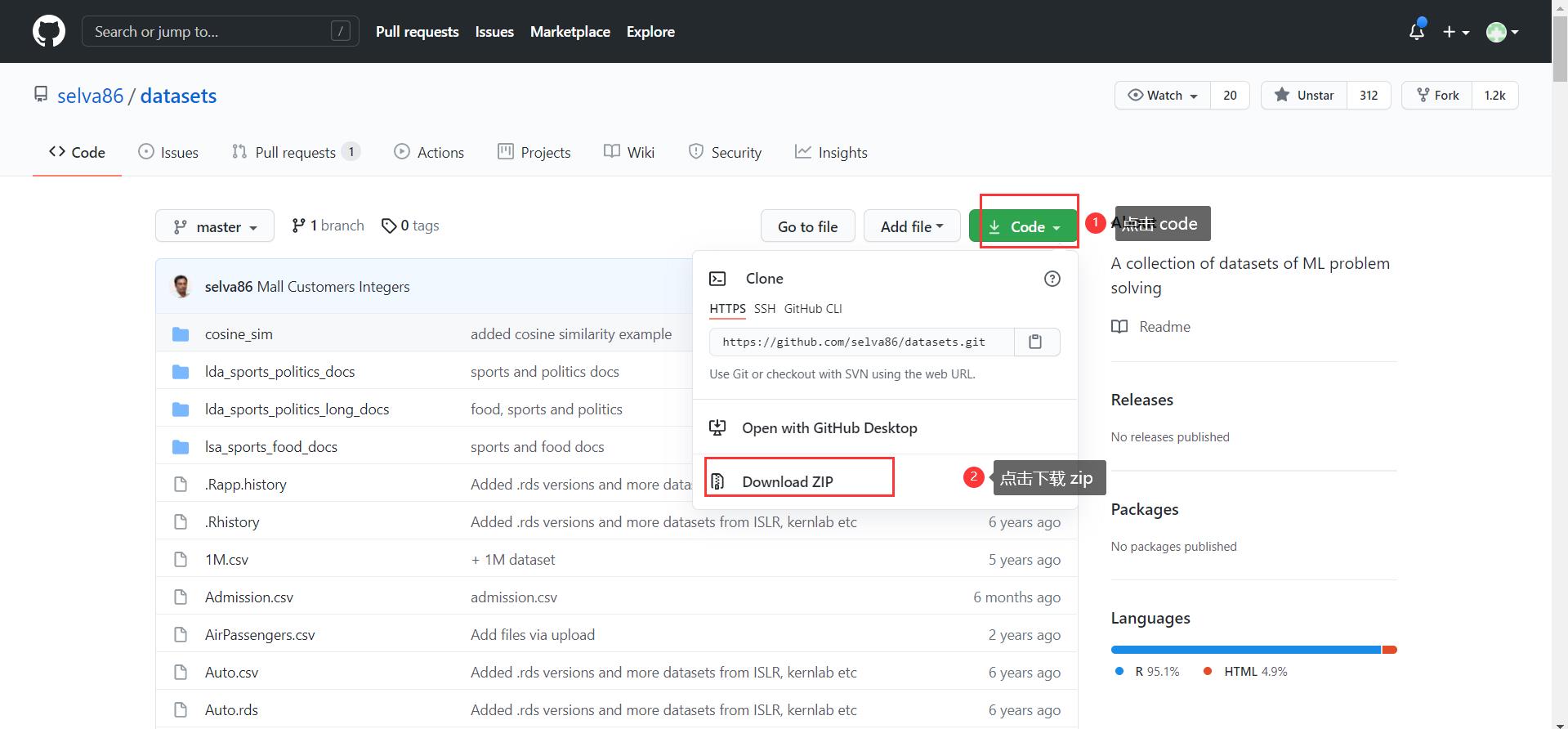
•GitHub是国外网站,可能因为网速慢导致下载失败,一可以百度解决下载问题,二可以评论留言,博主会私信发给完整的数据集!!!
•将上述链接的整个数据集下载下来,数据集中有很多我们可以练习的数据类,我们从中选择一个数据类进行散点图的演示!!
数据展示
•数据集下载完成后,解压,在文件目录中找到下图中的csv数据文件
•上述的csv文件数据为:美国中西部地区人口分布详细数据,我们对此数据进行分析!!!
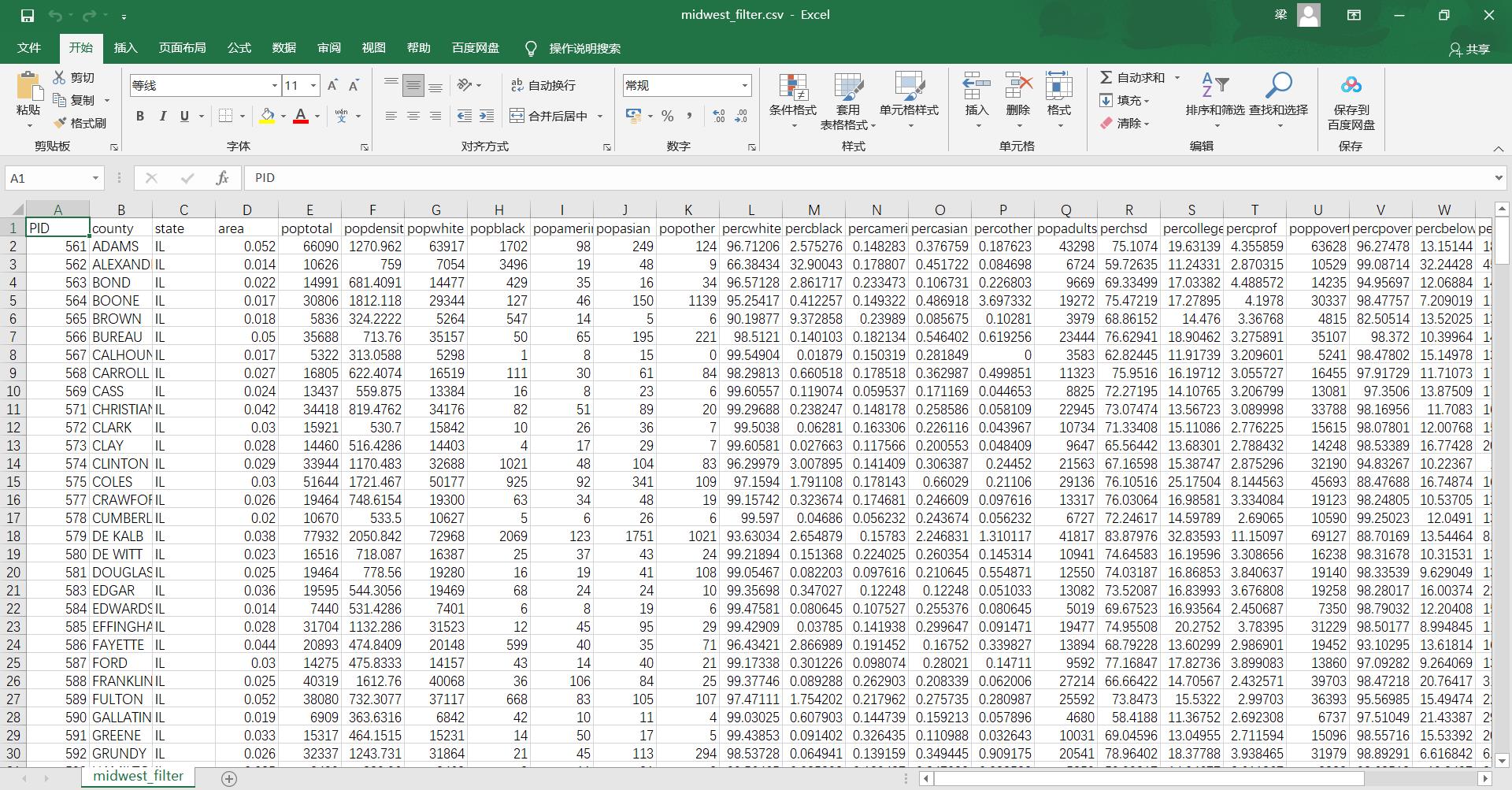
•图中所示,大量的数据已满足我们可视化散点图的需求!!!
数据分析
1.确定横纵坐标的选择
•首先分析数据表中的特征值关系,我们需要研究总人口与面积的关系!!

•上述表中特征值意思为:
•[“城市ID”, “郡”,“州",“面积",“总人口”,“人口密度","白人人口”,"非裔人口”,“美洲印第安人人口”,"亚洲人口”,"其他人种人口”,“白人所占比例”,“非裔所占比例”,“美洲印第安人所占比例”,“亚洲人所占比例”,“其他人种比例”“成年人口”,“具有高中文凭的比率”,“大学文凭比例”,“有工作的人群比例”“已知贫困人口”,“已知贫困人口的比例”,“贫困线以下的人的比例”,“贫困线以下的儿童所占比例”,“贫困的成年人所占的比例”,“贫困的老年人所占的比例”,“是否拥有地铁”,“标签”,“点的尺寸”]
•红色圈出的两个特征值是需要使用的关系特征值,即为我们所需的横纵坐标!!
2.准备标签的列表与颜色
•首先要提取标签中不重复的值,观察一共有多少中标签,即确定我们需要多少中颜色!!
import numpy as np
import pandas as pd
# 导入数据
midwest = pd.read_csv(r'D:\\9\\midwest_filter.csv')
# 提取标签中不重复类别
categories = np.unique(midwest['category']) # 使用unique去除重复项
print(categories)
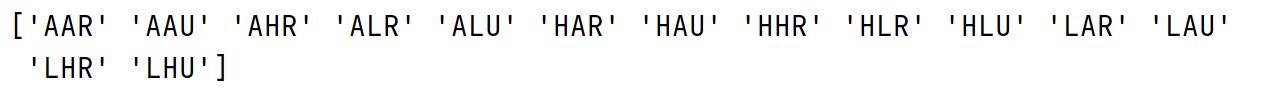
•上述图中有14个不重复的标签,即我们需要14种不重复颜色!!
•对于这14种不同颜色我们可以选择matplotlib中的十号光谱,自动生成14中不同颜色!!
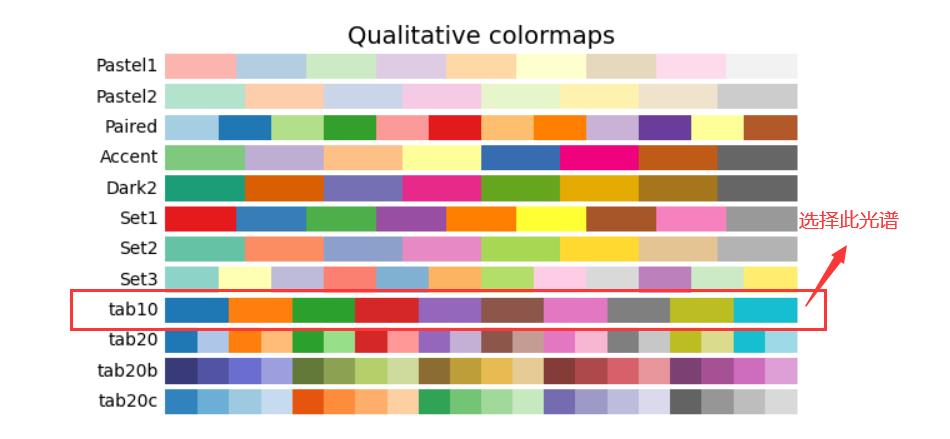
举例:代码演示tab10生成不同颜色:
import matplotlib.pyplot as plt
import numpy as np
color1 = plt.cm.tab10(5.2) # tab(10)括号中输入随机数,生成颜色
x = np.random.rand(10) # 生成十个随机数
y = x + x ** 2 - 10 # 函数关系确定y的值
plt.scatter(x, y,
c=np.array(color1).reshape(1, -1))
plt.show() # 显示图像
•当你在代码中直接使用color1时,不会报错,但会出现下图警告!!!解决方法解释参考博文,此博文也是博主自己写的,可详细理解:解决警告:c argument looks like a single numeric RGB or RGBA sequence, which should be avoi(图文并茂详细版!!!)

4.确定横纵坐标的值
•使用循环取出不同标签的横纵坐标,(面积,总人口)
import numpy as np
import pandas as pd
# 导入数据
midwest = pd.read_csv(r'D:\\9\\midwest_filter.csv')
# 提取标签中不重复类别
categories = np.unique(midwest['category']) # 使用unique去除重复项
for i in range(len(categories)):
area = midwest.loc[midwest['category'] == categories[i], 'area'] # 横坐标
poptoal = midwest.loc[midwest['category'] == categories[i], 'poptotal'] # 纵坐标
print(area)
print(poptoal)
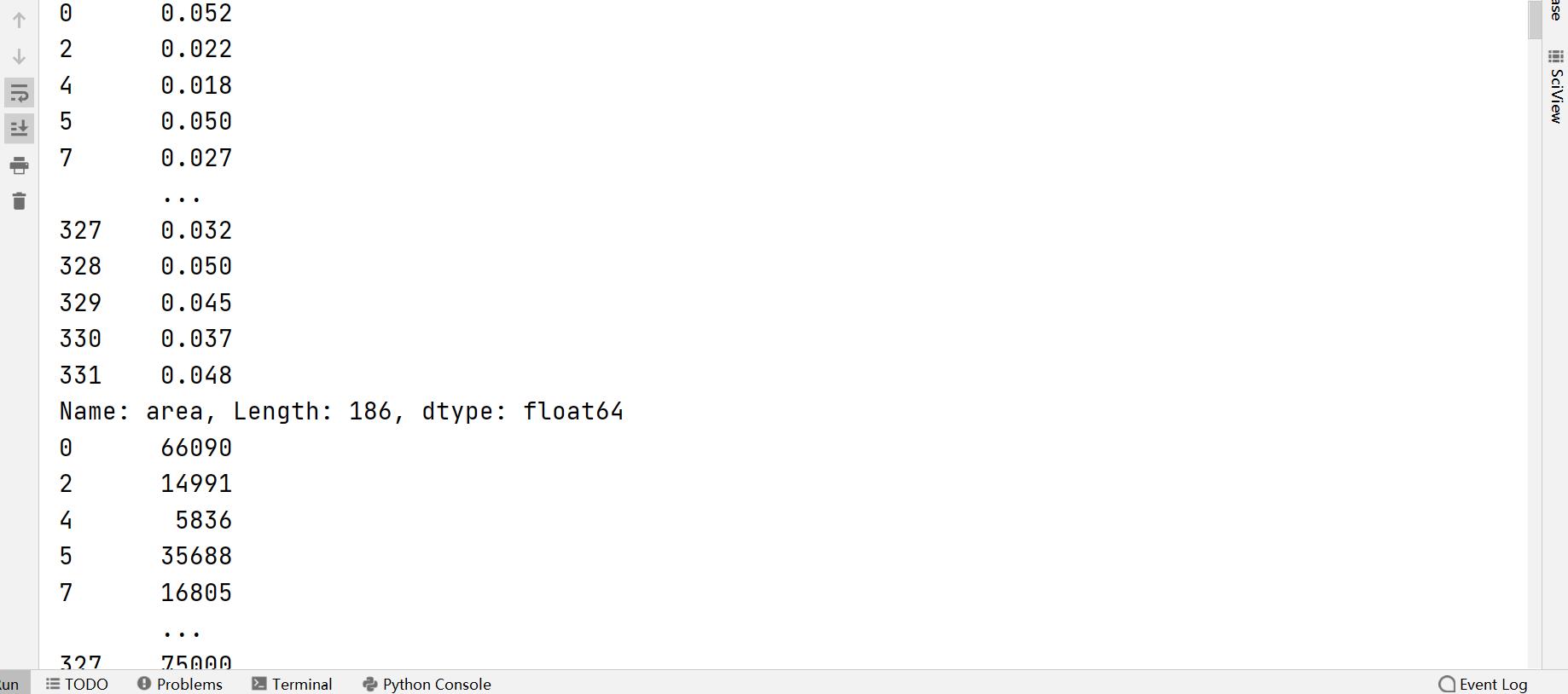
•如上图所示:即为成功取出所需横,纵坐标!!
5.绘制基础图像
•将上述代码融合可得:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 导入数据
midwest = pd.read_csv(r'D:\\9\\midwest_filter.csv')
# 提取标签中不重复类别
categories = np.unique(midwest['category']) # 使用unique去除重复项
plt.figure(figsize=(16, 10))
for i in range(len(categories)):
plt.scatter(midwest.loc[midwest['category'] == categories[i], 'area'] # 横坐标
, midwest.loc[midwest['category'] == categories[i], 'poptotal'] # 纵坐标
, s=20 # 数据点大小
, c=np.array(plt.cm.tab10(i / len(categories))).reshape(1, -1) # 颜色
, label=categories[i]) # 标签
plt.legend() # 显示图例(标签)
plt.show() # 显示图像
•将上述代码优化(效果相同!!)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 导入数据
midwest = pd.read_csv(r'D:\\9\\midwest_filter.csv')
# 准备标签列表与颜色列表
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i / float(len(categories) - 1)) for i in range(len(categories))]
plt.figure(figsize=(16, 10))
for i, category in enumerate(categories): # i 为索引 category为特征
plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category == category, :]
, s=20 # 点的大小
, c=np.array(colors[i]).reshape(1, -1) # 点的颜色
, label=str(category)) # 标签
plt.legend() # 显示图例(标签)
plt.show() # 显示图像
•上述的两个代码块的图像都为下图:
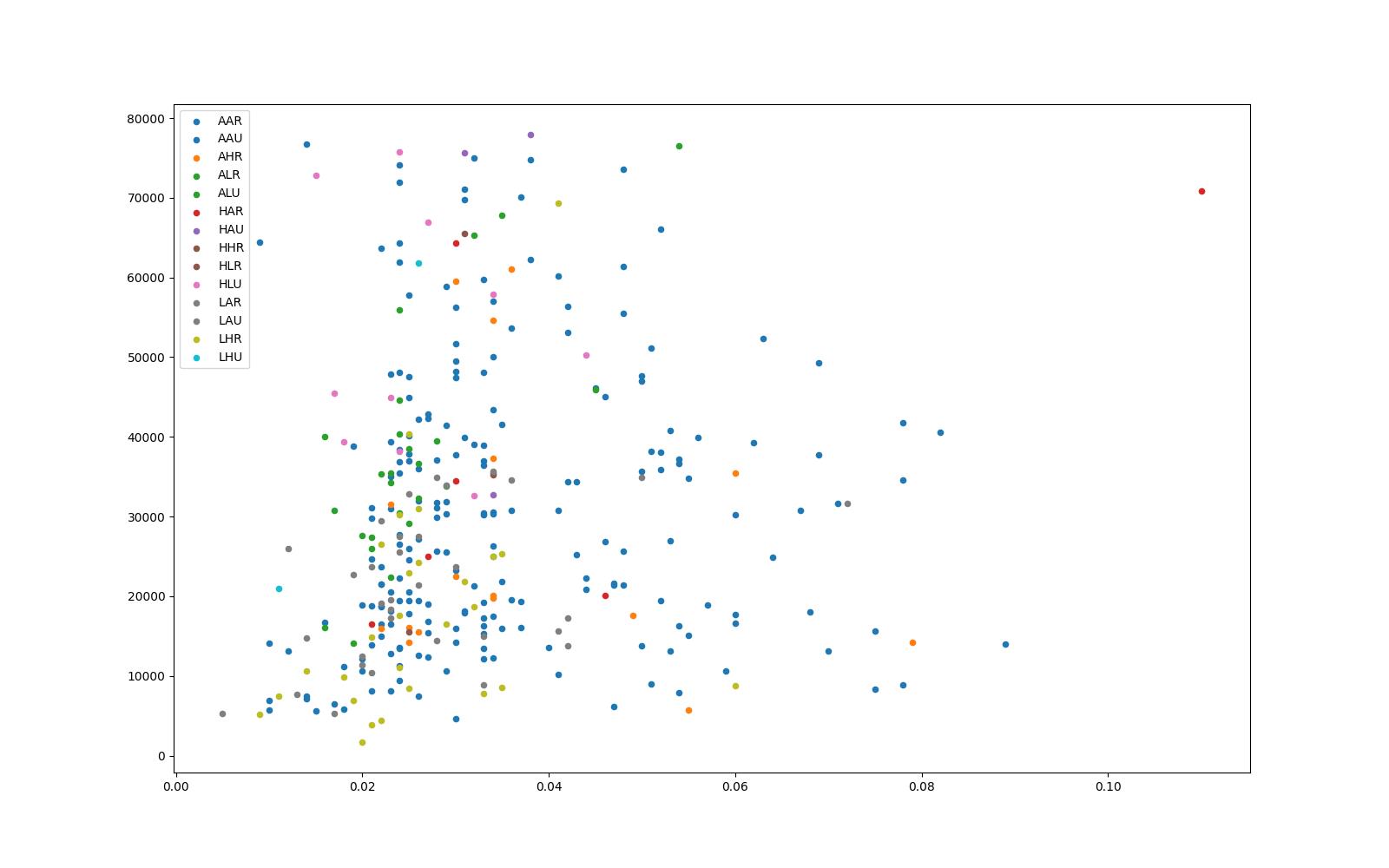
•由上述绘制的图片可以看出:仅有少许发达城市为面积小,人口多,也有右上角的特殊点面积非常大,人口非常多,但是大部分城市的面积与人口是称相似正比的
•出现上述图像即为绘制成功,在应对以后多个标签类型时,即可游刃有余的处理图像!!!
以上是关于Python数据可视化之散点图(进阶篇---图文并茂详细版!!!)的主要内容,如果未能解决你的问题,请参考以下文章