C++并发编程----并发代码的设计(《C++ Concurrency in Action》 读书笔记)
Posted 小丑快学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++并发编程----并发代码的设计(《C++ Concurrency in Action》 读书笔记)相关的知识,希望对你有一定的参考价值。
线程间的工作划分
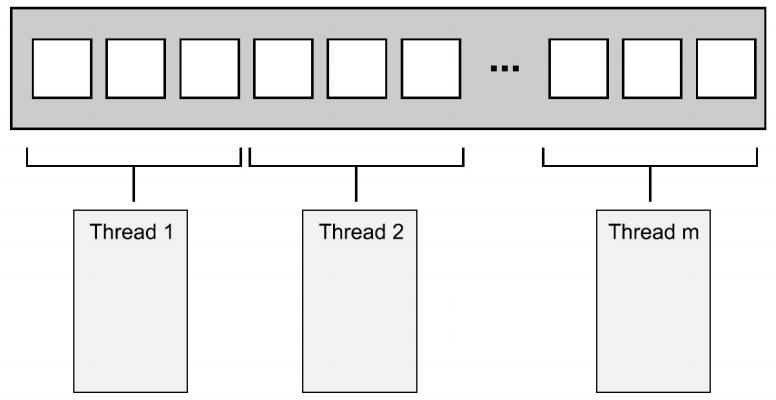
数据划分
:第一组N个元素分配一个线程,下一组N个元素再分配一个线程,以快速排序为例,以此类 推:
一项任务被分割成多个,放入一个并行任务集中,执行线程独立的执行这些任务,结果在会有主线 程中合并。
递归划分

一般来说每次递归产生一个新的进程对数据进行划分并处理操作,这样每递归一次,线程的数量将会翻一倍,线程数量将会呈现指数级的增长,但是当大量的线程产生时,将会导致大量时间和资源用于线程切换,因而导致程序的指向效果很差。一般会通过使用 std::thread::hardware_concurrency() 函数来确定线程的数量,确定硬件上做多能运行的线程数。可以把多个数据块放置于线程安全的栈上去,然后当有线程空闲时便可以栈中的数据块去除进行排序操作。
template<typename T>
struct sorter // 1
{
struct chunk_to_sort
{
std::list<T> data;
std::promise<std::list<T> > promise;//传递一个保存list<T>的future
};
thread_safe_stack<chunk_to_sort> chunks; // 2
std::vector<std::thread> threads; // 3
unsigned const max_thread_count;//最大的线程数应该为 硬件并发 - 1
std::atomic<bool> end_of_data;
sorter() :
max_thread_count(std::thread::hardware_concurrency() - 1),
end_of_data(false)
{}
~sorter() // 4
{
end_of_data = true; // 5
for (unsigned i = 0; i < threads.size(); ++i)
{
threads[i].join(); // 6 线程回收
}
}
/*
从栈中取出一块数据进行排序
*/
void try_sort_chunk()
{
boost::shared_ptr< chunk_to_sort > chunk = chunks.pop(); // 7
if (chunk)
{
sort_chunk(chunk); // 8 排序并将数据放入到promise中的future
}
} //try_sort_chunk()
/*
对一个数据进行排序,返回已经排好序的数据
*/
std::list<T> do_sort(std::list<T>& chunk_data) // 9
{
//数据为空直接返回
if (chunk_data.empty())
{
return chunk_data;
}
std::list<T> result;
//切分一个数据到result中
result.splice(result.begin(), chunk_data, chunk_data.begin());
//取出划分数据 partition_val
T const& partition_val = *result.begin();
//划分数据,divide_point 指向第二组数据的第一个元素
typename std::list<T>::iterator divide_point = // 10
std::partition(chunk_data.begin(), chunk_data.end(),
[&](T const& val) {return val < partition_val; });
//小于划分值的数据放入到ew_lower_chunk的data内,此时chunk_data中的数据为大于划分值的数据
chunk_to_sort new_lower_chunk;
new_lower_chunk.data.splice(new_lower_chunk.data.end(),
chunk_data, chunk_data.begin(),
divide_point);
//new_lower是new_lower_chunk中的future,其对应数据为划分值之前的
std::future<std::list<T> > new_lower =
new_lower_chunk.promise.get_future();
//将第前半部分数据块放到栈中,如果其他其他线程对齐进行排序则其future中将得到有序数据
chunks.push(std::move(new_lower_chunk)); // 11
//如果有备用处理器则则产生新的线程, 然后存放到vector中
if (threads.size() < max_thread_count) // 12
{
//新线程产生则会对栈中的数据进行排序,并设置对应的future
//线程中传入的函数为this->sort_thread()
threads.push_back(std::thread(&sorter<T>::sort_thread, this));
}
//递归对第二组数据进行排序
std::list<T> new_higher(do_sort(chunk_data));
//将排好序的第二组数据放入到划分值的后面
result.splice(result.end(), new_higher);
//有可能数据还未处理完成,则需等待其他线程处理完成数据
while (new_lower.wait_for(std::chrono::seconds(0)) !=
std::future_status::ready) // 13 如果future已经设置完毕则退出
{
try_sort_chunk(); // 14 线程等待期间可以先处理栈上的数据
}
//将排好序的第一组数据放入到划分值之前
result.splice(result.begin(), new_lower.get());
return result;
}//do_sort
/*
将排好的数据放到promise的future中
*/
void sort_chunk(boost::shared_ptr<chunk_to_sort> const& chunk)
{
chunk->promise.set_value(do_sort(chunk->data)); // 15
}
void sort_thread()
{
while (!end_of_data) // 16 如果还未完成排序则继续处理栈上的数据
{
try_sort_chunk(); // 17
std::this_thread::yield(); // 18 当前线程放弃cpu,回到竞争状态,以便其他线程执行
}
}
};
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input) // 19
{
if (input.empty())
{
return input;
}
sorter<T> s;
return s.do_sort(input); // 20 返回后将会设置end_fo_data,并回收线程资源
}
每次对数据进行划分,将数据的前半部分放入到栈中,可以交由其他线程进行处理,然后该该线程递归处理后半部分数据,最后通过和相应的数据块绑定的future获取已经排好序的数据块,整合两部分数据以及划分值后返回即可。
以上是关于C++并发编程----并发代码的设计(《C++ Concurrency in Action》 读书笔记)的主要内容,如果未能解决你的问题,请参考以下文章