系统架构设计-数据库系统知识点
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统架构设计-数据库系统知识点相关的知识,希望对你有一定的参考价值。
一、数据库的结构与模式
数据库技术中采用分级的方法将数据库的结构划分为多个层次。最著名的是美国ANSI/ SPARC 数据库系统研究组 1975年提出的三级划分法。
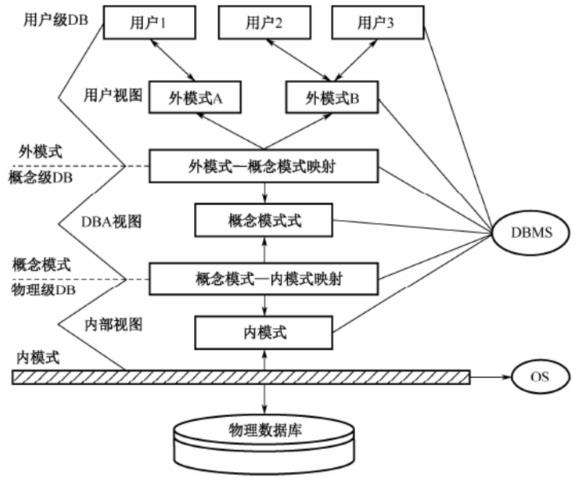
1. 三级模式
数据库系统的三级模式为外模式、概念模式、内模式。
-
概念模式。概念模式(模式、逻辑模式)用以描述整个数据库中数据库的逻辑结构,描述现实世界中的实体及其性质与联系,定义记录、数据项、数据的完整性约束条件及记录之间的联系,是数据项值的框架。 数据库系统概念模式通常还包含有访问控制、保密定义、完整性检查等方面的内容,以及概念/物理之间的映射。
概念模式是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。一个数据库只有一个概念模式。 -
外模式。外模式(子模式、用户模式)用以描述用户看到或使用的那部分数据的逻辑结构,用户根据外模式用数据操作语句或应用程序去操作数据库中的数据。外模式主要描述组成用户视图的各个记录的组成、相互关系、数据项的特征、数据的安全性和完整性约束条件。
外模式是数据库用户(包括程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。一个数据库可以有多个外模式。一个应用程序只能使用一个外模式。 -
内模式。内模式是整个数据库的最低层表示,不同于物理层,它假设外存是一个无限的线性地址空间。内模式定义的是存储记录的类型、存储域的表示以及存储记录的物理顺序,指引元、索引和存储路径等数据的存储组织。
2. 三级抽象
数据库系统划分为三个抽象级:用户级、概念级、物理级。
-
用户级数据库。用户级数据库对应于外模式,是最接近用户的一级数据库,是用户可以看到和使用的数据库,又称用户视图。用户级数据库主要由外部记录组成,不同的用户视图可以互相重叠,用户的所有操作都是针对用户视图进行的。
-
概念级数据库。概念级数据库对应于概念模式,介于用户级和物理级之间,是所有用户视图的最小并集,是数据库管理员可看到和使用的数据库,又称 DBA(DataBase Administrator,数据库管理员)视图。概念级数据库由概念记录组成,一个数据库可有多个不同的用户视图,每个用户视图由数据库某一部分的抽象表示所组成。一个数据库应用系统只存在一个 DBA 视图,它把数据库作为一个整体的抽象表示。概念级模式把用户视图有机地结合成一个整体,综合平衡考虑所有用户要求,实现数据的一致性、最大限度降低数据冗余、准确地反映数据间的联系。
-
物理级数据库。物理级数据库对应于内模式,是数据库的低层表示,它描述数据的实际存储组织,是最接近于物理存储的级,又称内部视图。物理级数据库由内部记录组成,物理级数据库并不是真正的物理存储,而是最接近于物理存储的级。
3. 两级独立性
数据库系统两级独立性是指物理独立性和逻辑独立性。三个抽象级间通过两级映射(外模式—模式映射,模式—内模式映射)进行相互转换,使得数据库的三级形成一个统一的整体。
-
物理独立性。物理独立性是指用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的。当数据的物理存储改变时,应用程序不需要改变。
物理独立性存在于概念模式和内模式之间的映射转换,说明物理组织发生变化时应用程序的独立程度。 -
逻辑独立性。逻辑独立性是指用户的应用程序与数据库中的逻辑结构是相互独立的。当数据的逻辑结构改变时,应用程序不需要改变。
逻辑独立性存在于外模式和概念模式之间的映射转换,说明概念模式发生变化时应用程序的独立程度。
二、数据库设计过程
1978 年 10 月来自 30 多个欧美国家的主要数据库专家在美国新奥尔良市专门讨论了数据库设计问题,提出了数据库设计规范,把数据库设计分为需求分析、概念结构设计、逻辑结构设计、物理结构设计 4 个阶段。
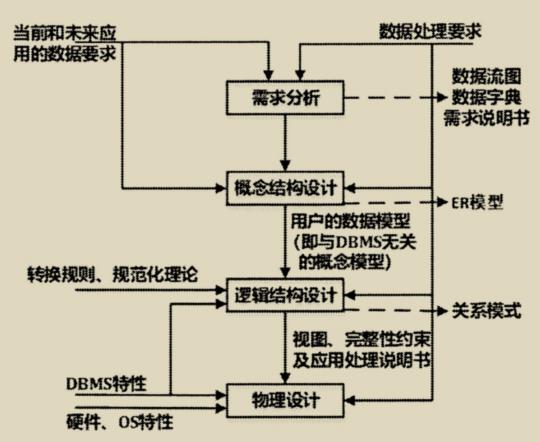
三、数据模型
数据模型主要有两大类,分别是概念数据模型(实体—联系模型)和基本数据模型(结构数据模型)。
其中概念数据模型是按照用户的观点来对数据和信息建模,主要用于数据库设计。概念模型主要用实体—联系方法(Entity-Relationship Approach)表示,所以也称 E-R 模型。
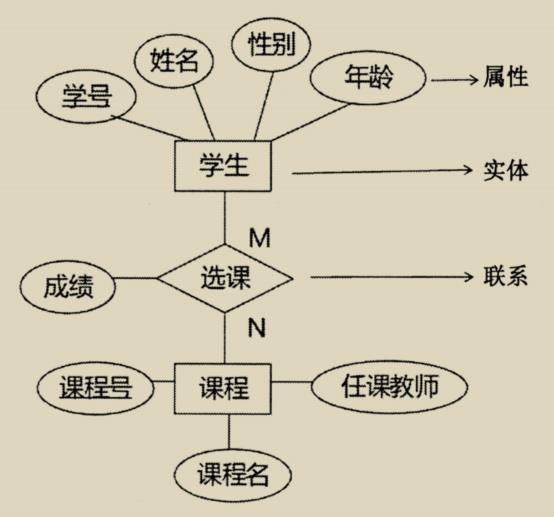
图中的椭圆代表属性字段,矩形代表实体数据表,菱形代表之间的联系。
1. ER模型集成
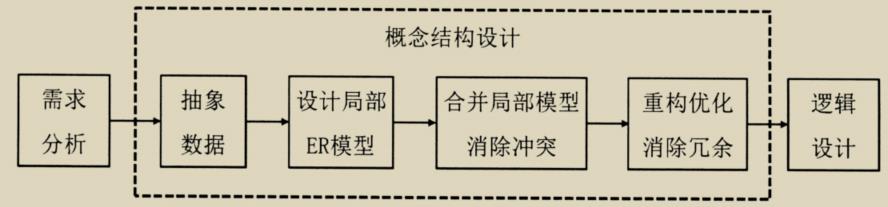
集成方法:
- 多个局部E-R图一次集成。
- 逐步集成,用累加的方式一次集成两个局部E-R。
集成产生的冲突及解决方法:
- 属性冲突:包括属性域冲突和属性取值冲突。
- 命名冲突:包括同名异义和异名同义。
- 结构冲突:包括同一对象在不同应用中具体有不同的抽象,以及同一实体在不同局部E-R图中所包含的属性个数和属性排列次序不完全相同。
2. 实体转换关系
- 一个实体转换为一个关系模型。
- 1 : 1联系可以转化为一个关系模型,也可以与任意一端实体的关系模型合并。
- 1 : n联系可以转换为一个关系模型,也可以与 n 端实体的关系模型合并。
- m : n联系必须单独转成一个关系模式。
- 三个以上实体间的关系转为一个多元联系。
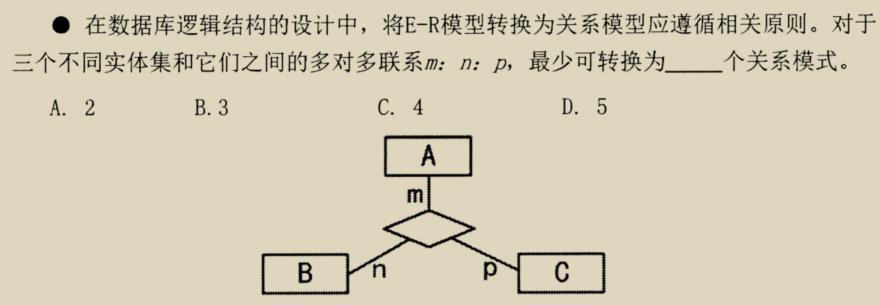
上题符合三个实体间的关系,其中三个实体转为三个关系模型,联系转为一个关系模型,即最少可转四个关系模型。
四、关系代数
关系代数的基本运算主要有并、交、差、笛卡尔积、选择、投影、连接和除法运算。
比如:关系S1和关系S2
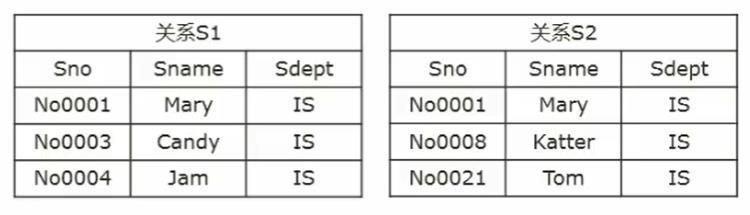
-
S1 ∩ S2
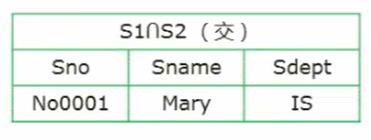
-
S1 ∪ S2
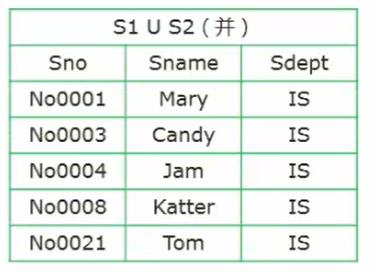
-
S1 - S2
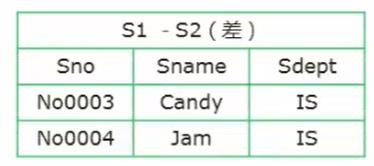
-
S1 X S2 (笛卡尔积)
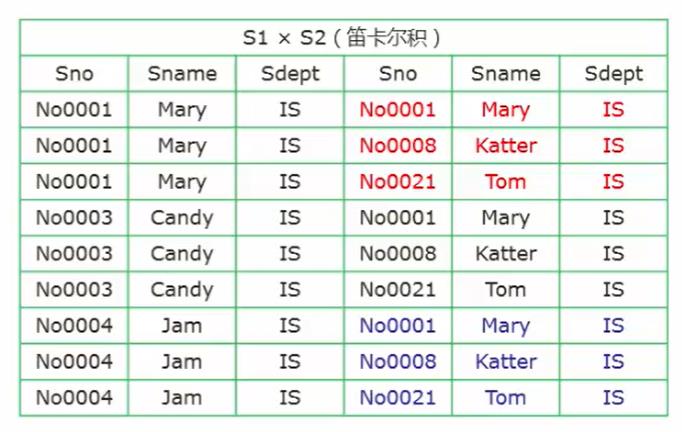
-
投影 π
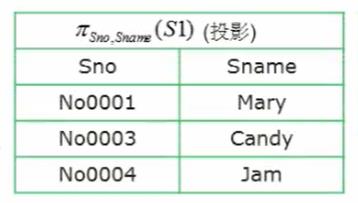
6. 条件选择 σ

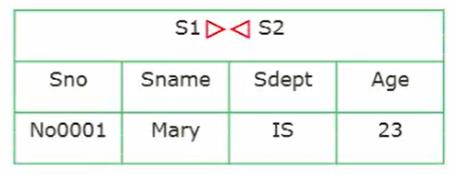
7. 连接
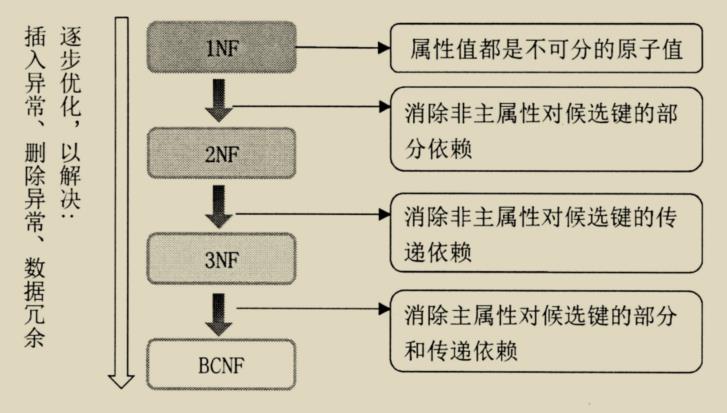
五、数据库范式
关系模型满足的确定约束条件称为范式,根据满足约束条件的级别不同,范式由低到高分为 1NF(第一范式)、2NF(第二范式)、3NF(第三范式)、BCNF(BC 范式)、4NF(第四范式) 等。不同的级别范式性质不同。
把一个低一级的关系模型分解为高一级关系模型的过程,称为关系模型的规范化。关系模型分解必须遵守两个准则。
- 无损连接性:信息不失真(不增减信息)。
- 函数依赖保持性:不破坏属性间存在的依赖关系。
-
第一范式
1NF 是最低的规范化要求。如果关系 R 中所有属性的值域都是简单域,其元素(即属性)不可再分,是属性项而不是属性组,那么关系模型 R 是第一范式的。 -
第二范式
如果一个关系 R 属于 1NF,且所有的非主属性都完全依赖于主属性,则称之为第二范式。 -
第三范式
如果一个关系 R 属于 2NF,且每个非主属性不传递依赖于主属性。 -
BC 范式
如果一个关系 R 属于 3NF,且每个主属性间没有函数依赖关系。
六、反规范化
数据库中的数据规范化的优点是减少了数据冗余,节约了存储空间,相应逻辑和物理的 I/O 次数减少,同时加快了增、删、改的速度,但是对完全规范的数据库查询,通常需要更多的连接操作,从而影响查询速度。 因此,有时为了提高某些查询或应用的性能而破坏规范规则,即反规范化(非规范化处理)。
反规范化技术包括:
-
增加冗余列
增加冗余列是指在多个表中具有相同的列,它常用来在查询时避免连接操作。
-
增加派生列
增加派生列指增加的列可以通过表中其他数据计算生成。它的作用是在查询时减少计算量,从而加快查询速度。
-
重新组表
重新组表指如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接而提高性能。
-
分割表
有时对表做分割可以提高性能,比如: 水平分割 和 垂直分割。
七、 事务管理
数据库系统运行的基本工作单位是事务,事务相当于操作系统中的进程,是用户定义的一个数据库操作序列,这些操作序列要么全做要么全不做,是一个不可分割的工作单位。事务具有以下特性:
- 原子性(Atomicity):数据库的逻辑工作单位。
- 一致性(Consistency):使数据库从一个一致性状态变到另一个一致性状态。
- 隔离性(Isolation):不能被其他事务干扰。
- 持续性(永久性)(Durability):一旦提交,改变就是永久性的。
1. 并发控制
在多用户共享系统中,许多事务可能同时对同一数据进行操作,此时数据库管理系统的并发控制子系统负责协调并发事务的执行,保证数据库的完整性不受破坏,同时避免用户得到不正确的数据。
数据库的并发操作带来的问题有:丢失更新问题、不一致分析问题(读过时的数据)、依赖于未提交更新的问题(读了“脏”数据)。这三个问题需要 DBMS 的并发控制子系统来解决。
处理并发控制的主要方法是采用封锁技术。它有两种类型:排他型封锁(X 封锁)和共享型封锁(S 封锁)。
2. 并发控制-封锁协议
- 一级封锁协议。事务 T 在修改数据 R 之前必须先对其加 X 锁,直到事务结束才释放。一级封锁协议可防止丢失修改,并保证事务 T 是可恢复的。但不能保证可重复读和不读“脏”数据。
- 二级封锁协议。一级封锁协议加上事务 T 在读取数据 R 之前先对其加 S 锁,读完后即可释放 S 锁。二级封锁协议可防止丢失修改,还可防止读“脏”数据,但不能保证可重复读。
- 三级封锁协议。一级封锁协议加上事务 T 在读取数据 R 之前先对其加 S 锁,直到事务结束才释放。三级封锁协议可防止丢失修改、防止读“脏”数据与防止数据重复读。
- 两段锁协议。所有事务必须分两个阶段对数据项加锁和解锁。其中扩展阶段是在对任何数据进行读、写操作之前,首先要申请并获得对该数据的封锁;收缩阶段是在释放一个封锁之后,事务不能再申请和获得任何其他封锁。若并发执行的所有事务均遵守两段封锁协议,则对这些事务的任何并发调度策略都是可串行化的。遵守两段封锁协议的事务可能发生死锁。
八、备份与恢复
数据库中的数据一般都十分重要,不能丢失。事先制定一个合适的、可操作的备份和恢复计划至关重要。
数据备份分为:冷备份(静态备份,需要关闭服务)和热备份(动态备份,无需关闭服务)。
1. 备份的方式
- 完全备份:备份所有数据。
- 差量备份:仅备份上一次完全备份之后变化的数据。
- 增量备份:备份上一次备份之后变化的数据。
2. 数据恢复
- 事物中的错误:可通过RollBack 恢复为原先的数据。
- 其他因素:通过备份数据进行恢复,但有可能造成部分数据丢失。
九、分布式数据库
分布式数据库系统的模式结构有六个层次,如图 所示,实际的系统并非都具有这种结构。在这种结构中各级模式的层次清晰,可以概括和说明任何分布式数据库系统的概念和结构。
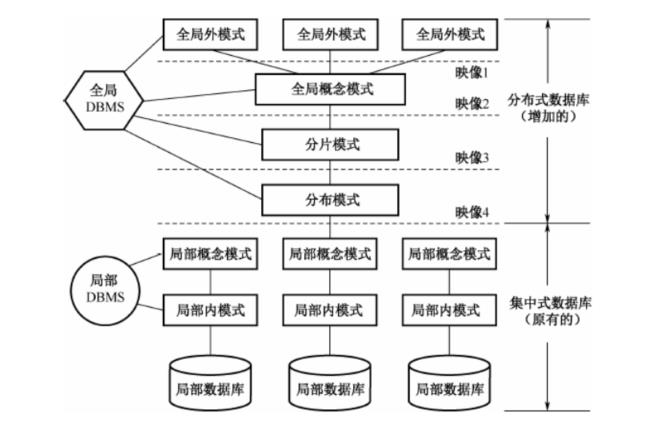
从整体上可以分为两大部分:下半部分是集中式数据库的模式结构,代表了各局部场地上局部数据库系统的基本结构;上半部分是分布式数据库系统增加的模式级别。
数据分片和透明性
将数据分片,使数据存放的单位不是关系而是片段,这既有利于按照用户的需求较好地组织数据的分布,也有利于控制数据的冗余度。分片的方式有多种,水平分片和垂直分片是两种基本的分片方式,混合分片和导出分片是较复杂的分片方式。
分布透明性指用户不必关心数据的逻辑分片,不必关心数据存储的物理位置分配细节,也不必关心局部场地上数据库的数据模型。分布透明性包括:分片透明性、位置透明性和局部数据模型透明性。
- 分片透明性是分布透明性的最高层次: 指用户或应用程序只对全局关系进行操作而不必考虑数据的分片。
- 位置透明性是分布透明性的下一层次:用户或应用程序应当了解分片情况,但不必了解片段的存储场地。
- 局部数据模型透明性:用户或应用程序应当了解分片及各片断存储的场地,但不必了解局部场地上使用的是何种数据模型。
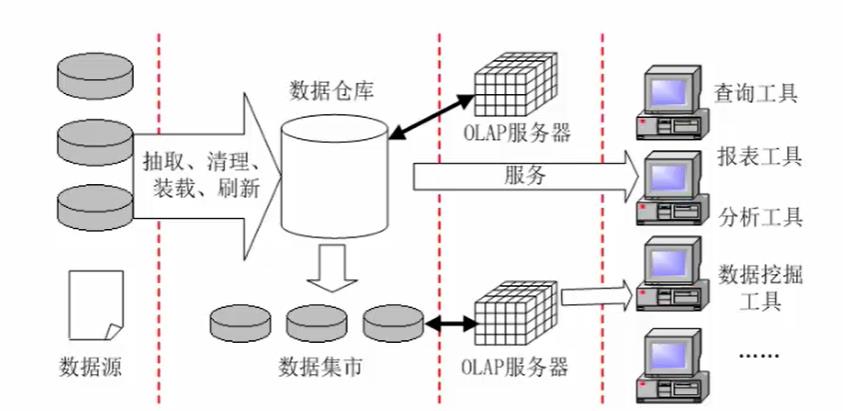
十、数据仓库与数据挖掘
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、且随时间变化的数据集合,用于支持管理决策。
1. 数据挖掘的方法
- 决策树
- 神经网络
- 遗传算法
- 关联规则挖掘算法
2. 数据挖掘方法分类
- 关联分析: 挖掘出隐蔽在数据间的相互关系。
- 序列模式分析:侧重点十分析数据间的前后关系(因果关系)。
- 分类分析:为每一个记录富裕一个标记再标记分类。
- 聚类分析:分类分析法的逆向过程。
十一、扩展
1. 数据库完整性约束
为了提高可靠性,需要对表数据进行约束,包括:
- 实体完整性约束(主键)
- 参照完整性约束(依赖其他表的字段)
- 用户自定义完整性约束
- 触发器(脚本约束)
2. 分布式事物两阶段提交协议指:表决阶段、收缩阶段。
以上是关于系统架构设计-数据库系统知识点的主要内容,如果未能解决你的问题,请参考以下文章