Python爬取人民网夜读文案
Posted 忆想不到的晖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取人民网夜读文案相关的知识,希望对你有一定的参考价值。
Python爬取人民网夜读文案
引言
人民网夜读文案中,有许多晚安的高清图片,爬下来做晚安素材,顺便练习Python爬虫知识。
来源:夜读 | 人与人之间最难得的,是看到别人的不容易 https://mp.weixin.qq.com/s/bYJAsb6R2aZZPTJPqUQDBQ
本项目仅供自我学习,无其他想法。
结果展示
资源信息
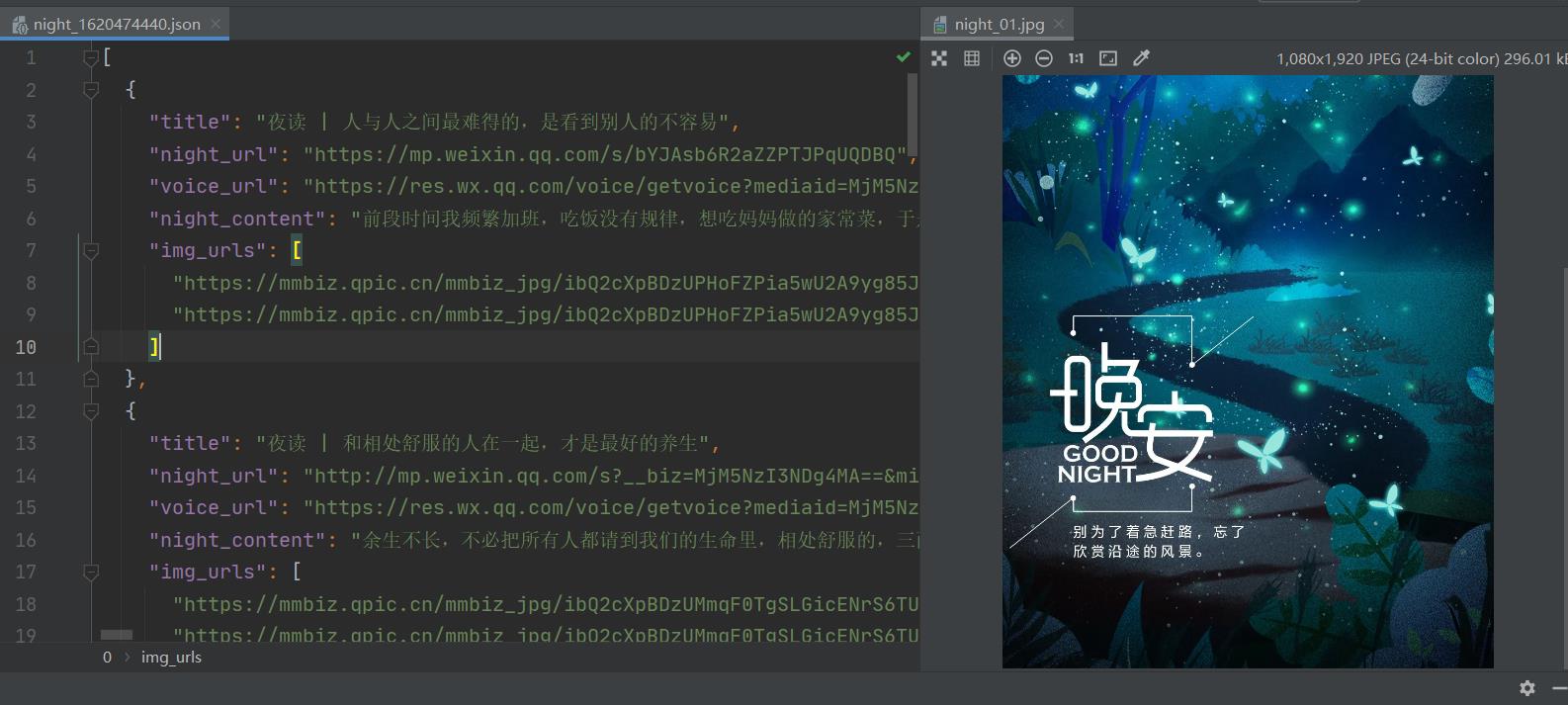
json数据展示
爬虫准备步骤
1、确认待爬数据
- 输入起始
urlhttps://mp.weixin.qq.com/s/bYJAsb6R2aZZPTJPqUQDBQ - 在网页中确认待爬数据
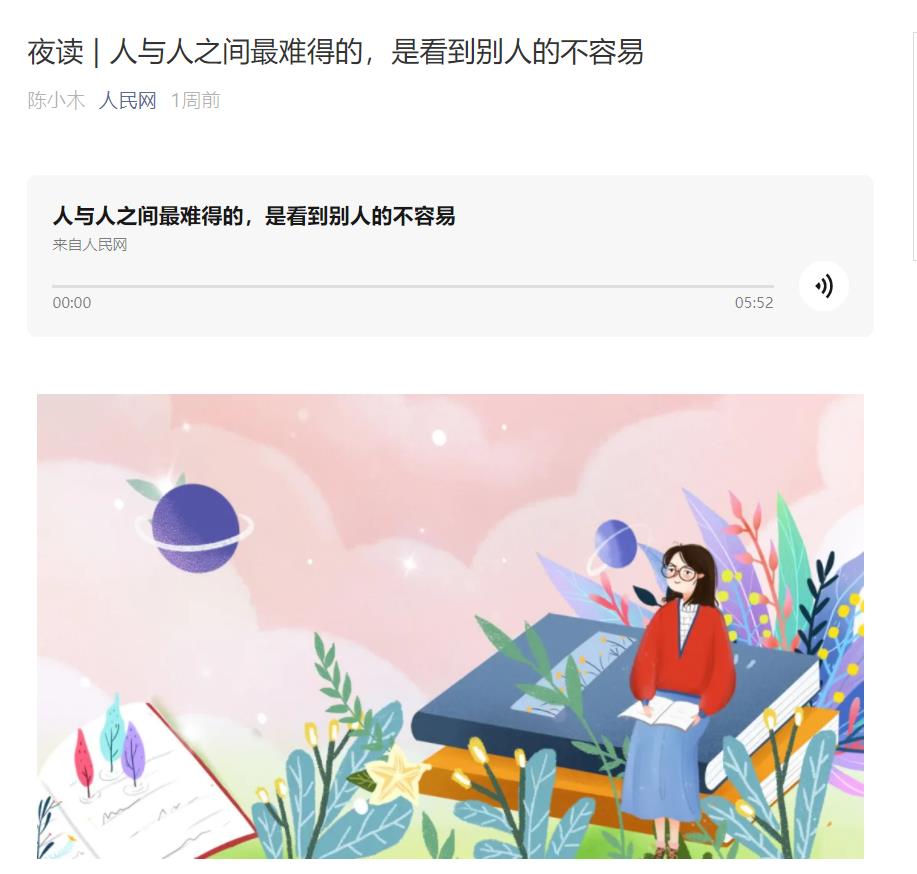


待爬数据如下
- 夜读标题
- 夜读音频
- 夜读文案
- 夜读图片
- 往期推荐 URL
2、页面分析,确认数据来源
- 打开浏览器开发者工具,选择
Network选项,刷新网页,查看网络请求 - 在网页中选择待爬元素,右击检查,查看详细。
- 复制你想爬取的数据到浏览器开发者工具中搜索看看能不能找到,确认其是否在响应中,因为一些数据是被浏览器渲染后才有。
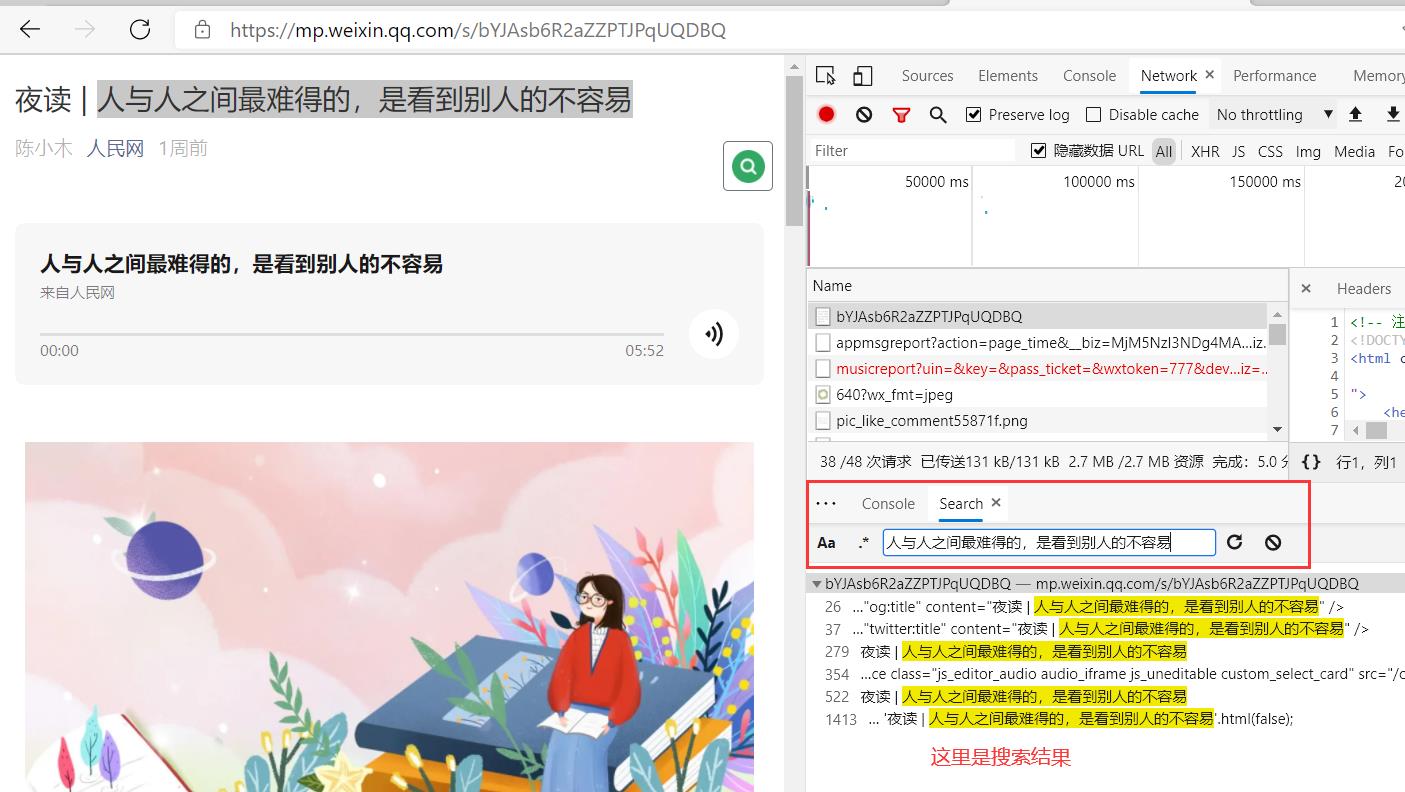
经分析,夜读标题、文案、图片都可以在网页元素中获取,只有一个音频,在其他地方。
在音频元素 <mpvoice> 中有一个 src 属性通过其拼接 https://mp.weixin.qq.com/ 域名,以为就可以了,谁知打开一看,还是没有音频数据,页面如下:
另寻它路,点击音频播放按钮,在浏览器开发者工具中捕获请求,发现有一个音频请求
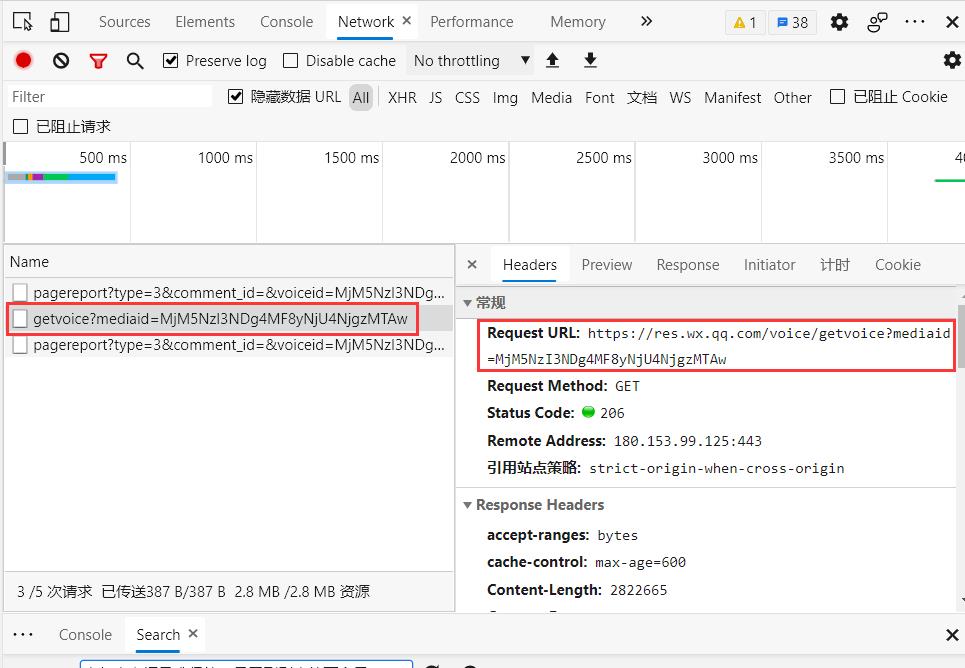
复制链接,在浏览器打开
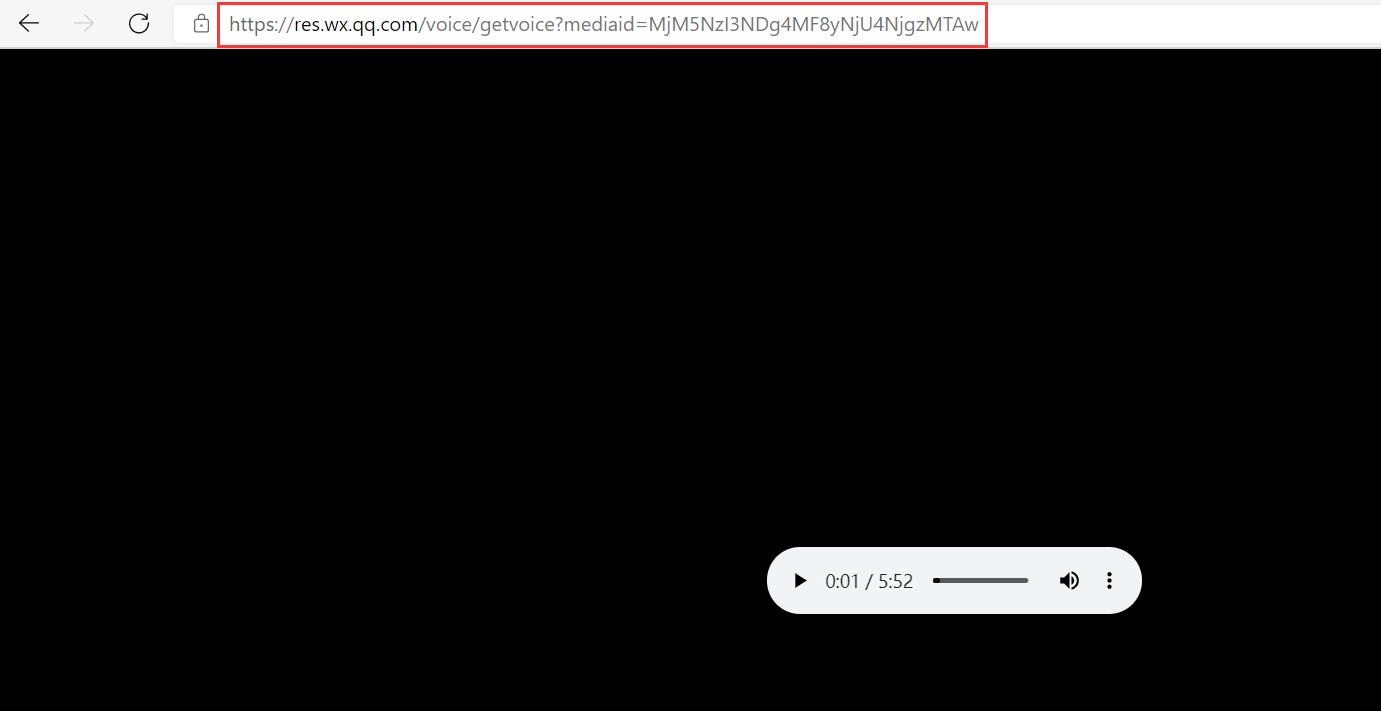
经过多篇文章测试,音频资源都在 https://res.wx.qq.com/voice/getvoice 下获取
只是每个id不同,因此看看 网页中能不能找到,一搜发现在<mpvoice> 元素的 voice_encode_filed 属性中

OK 所有数据都确认了获取途径。
编写代码测试获取
构造爬虫类
"""
Author: Hui
Desc: { 人民网夜读文案信息爬取 }
"""
import os
import json
import time
import random
import requests
import threading
from lxml import etree
# 请求头Agent信息
AGENTS = [
...
]
class PeopleNight(object):
def __init__(self):
# 起始 URL
self.start_url = 'https://mp.weixin.qq.com/s/bYJAsb6R2aZZPTJPqUQDBQ'
# 获取音频资源url
self.res_url = 'https://res.wx.qq.com/voice/getvoice?'
self.headers = {
'User-Agent': random.choice(AGENTS)
}
def get_data(self, url):
"""
获取人民网夜读数据
:param: url: 夜读url
:return:
"""
response = requests.get(url, headers=self.headers)
return response.content
def parse_data(self, data):
"""
解析人民网夜读数据, 并提取文章中往期推荐夜读 url
:param data: 人民网夜读响应数据
:return: night_info_dict
"""
pass
def save_data(self):
"""
保存夜读信息数据
:return:
"""
pass
def run(self):
data = self.get_data(self.url)
self.parse_data(data)
def main():
night = PeopleNight()
night.run()
if __name__ == '__main__':
main()
编写解析数据方法 parse_data() 【重点】
数据解析有很多方法,如下图
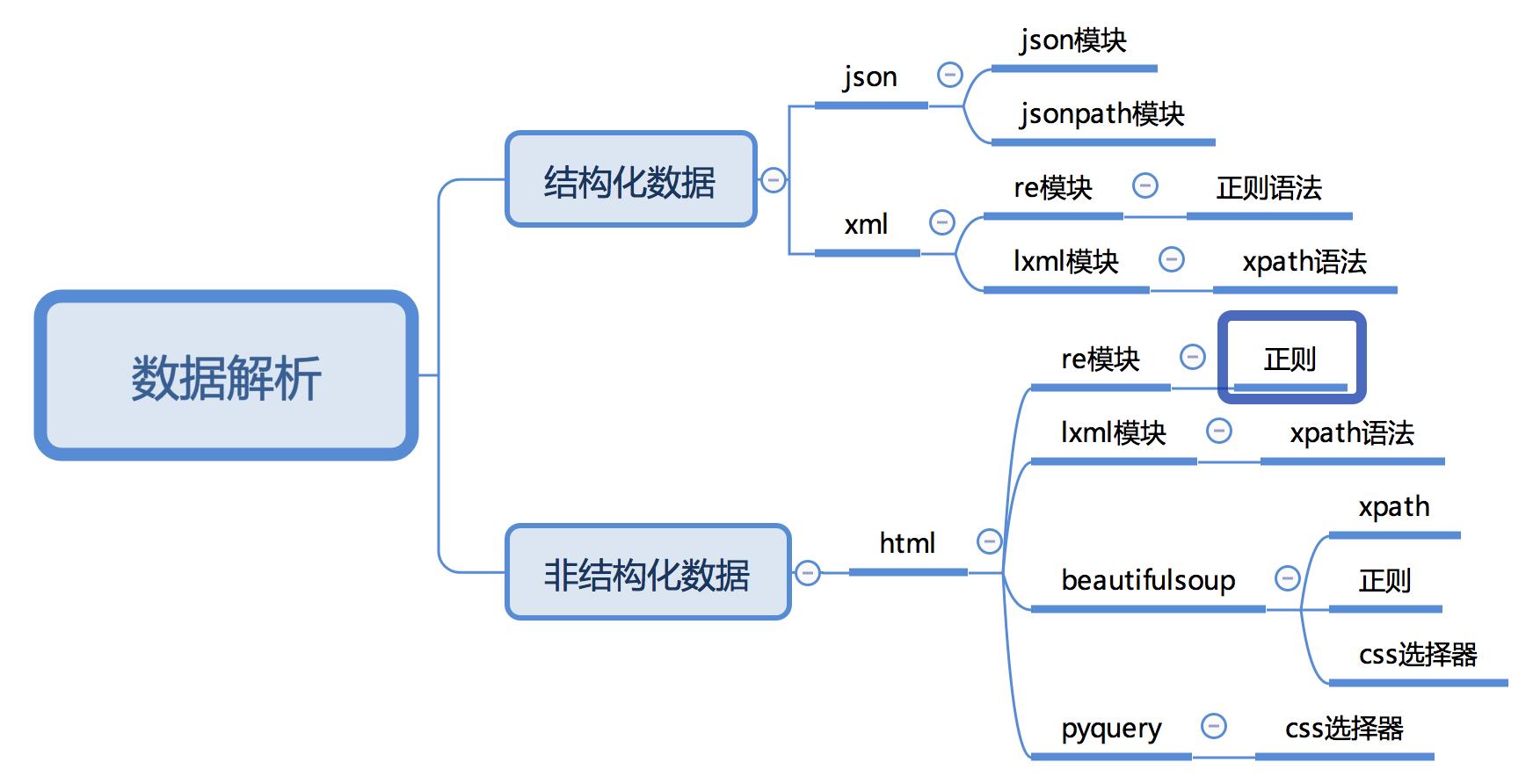
我这里选用的是 lxml 模块,利用 xpath 来提取
我们先不着急写代码,我们可以先用 Xpath Helper 插件在网页上写xpath 测试如何定位元素获取数据
测试获取标题
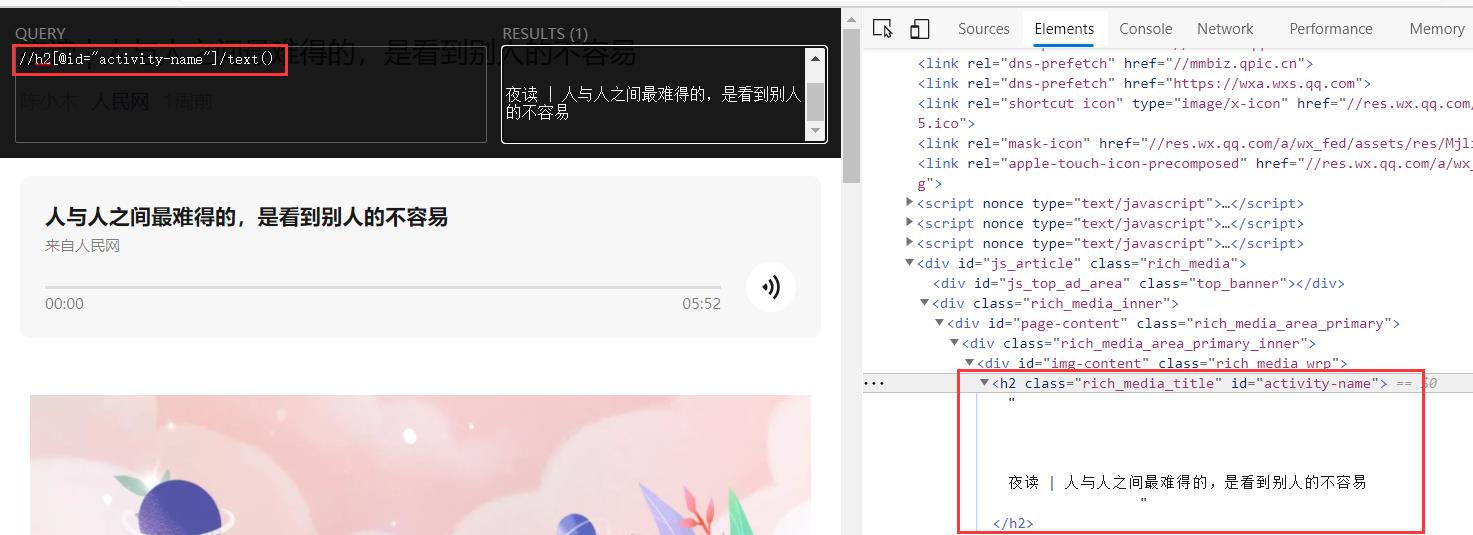
xpath如下:
//h2[@id="activity-name"]/text()
测试获取音频 mediaid
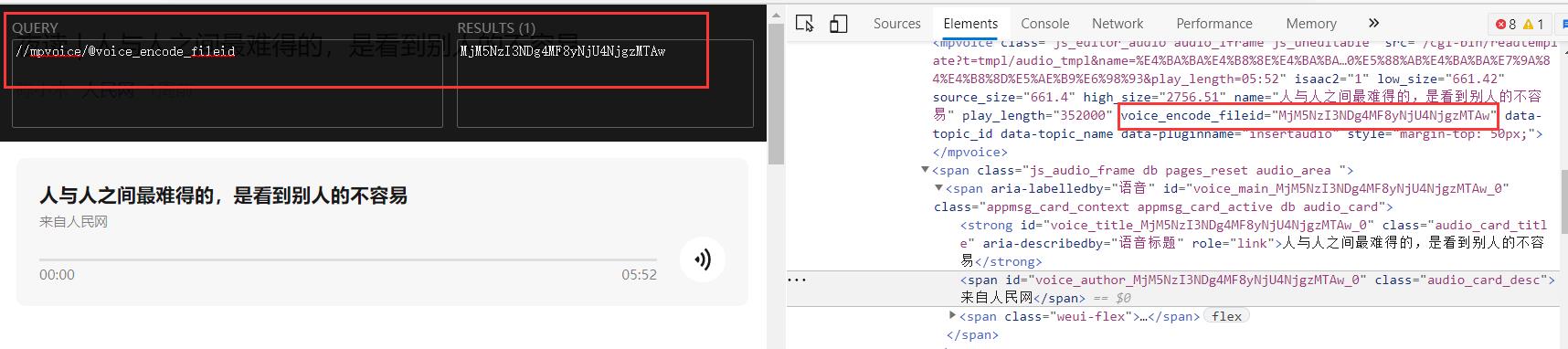
xpath如下:
//mpvoice/@voice_encode_fileid
测试获取夜读文案
经测试有些文案在
section标签下,因此 定义xpath语法如下:
//p/span[@style] | //section[contains(@style, "line-height")]/span
测试获取夜读图片
因为有些
GIF图、logo图、广告图我们不需要又有些文章图片在
section标签下因此xpath语法定义如下
//p/img[contains(@class, "rich_pages")]/@data-src |
//section/img[contains(@class, "rich_pages") and @data-type="jpeg"]/@data-src
测试获取往期推荐
xpath如下:
//section/a/@href
编写解析方法
# 获取音频资源url
# self.res_url = 'https://res.wx.qq.com/voice/getvoice?'
def parse_data(self, data):
"""
解析人民网夜读数据, 并提取文章中往期推荐夜读 url
:param data: 人民网夜读响应数据
:return: night_info_dict
"""
html = etree.HTML(data.decode())
# 获取夜读标题
title = html.xpath('//h2[@id="activity-name"]/text()')[0].strip()
# 获取音频url
media_id = html.xpath('//mpvoice/@voice_encode_fileid')[0]
voice_url = self.res_url + 'mediaid=' + media_id
# 获取夜读文案内容 ( 有些文案在 section标签下 )
el_list = html.xpath('//p/span[@style] | //section[contains(@style, "line-height")]/span')
# 由于文案中文字有些加粗的样式,不能直接用text()获取,因此改用 string(.)
# string(.)不能直接与之前的xpath一起使用,需要在之前对象的基础上使用
night_content = ''
for span in el_list:
paragraph = span.xpath('string(.)')
# 拼接每一段落
if paragraph.strip():
night_content = night_content + paragraph + '\\n'
# 获取夜读图片
xpath_express = '//p/img[contains(@class, "rich_pages")]/@data-src | ' \\
'//section/img[contains(@class, "rich_pages") and @data-type="jpeg"]/@data-src'
img_urls = html.xpath(xpath_express)
# 获取往期推荐夜读url, 并加入url任务队列中
night_urls = html.xpath('//section/a/@href')
# 封装夜读数据
night_info_dict = {
'title': title,
'night_url': self.current_url,
'voice_url': voice_url,
'night_content': night_content,
'img_urls': img_urls,
}
# 格式化打印
# from pprint import pprint
# pprint(night_info_dict)
return night_info_dict
编写解析方法时千万不要一次性写完,我们写一段 xpath 获取数据,就打印测试一下,以防出错。
这里有一个需要注意的是获取夜读文案
由于文案中文字有些加粗的样式,含有其他标签,有些文字不能直接用 text() 获取,因此改用 string(.)
string(.) 不能直接与之前的 xpath 一起使用,下面代码时 错误示范
//p/span[@style]/string(.) |
//section[contains(@style, "line-height")]/span/string(.)
需要在之前对象的基础上使用
# 获取夜读文案内容 ( 有些文案在 section标签下 )
el_list = html.xpath('//p/span[@style] | //section[contains(@style, "line-height")]/span')
night_content = ''
for span in el_list:
paragraph = span.xpath('string(.)')
# 拼接每一段落
if paragraph.strip():
night_content = night_content + paragraph + '\\n'
这里再介绍一个如何把一个列表切成几份的方法,在分配多任务中很有用
@staticmethod
def cut_list(ls, part):
"""
把列表切分为 part 份
:param ls: 列表
:param part: 份量
:return: ls[start:end]
"""
# 计算出每份的大小
size = len(ls) // part
for i in range(part):
start = size * i
end = size * (i + 1)
if i == part - 1:
# 把剩余的给最后一份
end = len(ls)
yield ls[start:end]
其他代码,我就不一一赘述了,就根据自己需求来,如:定义保存路径,保存类型,开启多线程等。
源代码
源代码已上传到 Gitee SpiderPractice: 爬虫练习项目,用于练习爬虫知识点,欢迎大家来访。
✍ 码字不易,万水千山总是情,点赞再走行不行,还望各位大侠多多支持❤️
以上是关于Python爬取人民网夜读文案的主要内容,如果未能解决你的问题,请参考以下文章