论文泛读149GlyphCRM:汉字及其字形的双向编码器表示
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读149GlyphCRM:汉字及其字形的双向编码器表示相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《GlyphCRM: Bidirectional Encoder Representation for Chinese Character with its Glyph》
一、摘要
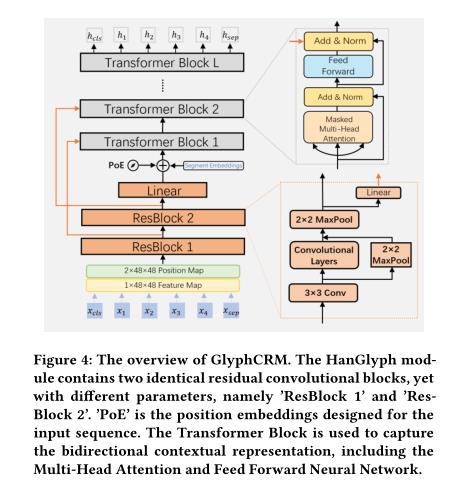
以往的工作表明,汉字的字形包含丰富的语义信息,具有增强汉字表征的潜力。利用字形特征的典型方法是将它们合并到字符嵌入空间中。受之前方法的启发,我们创新地提出了一种中文预训练表示模型,名为 GlyphCRM,它摒弃了基于 ID 的字符嵌入方法,而仅基于序列字符图像。我们将每个字符渲染成二进制灰度图像并为其设计双通道位置特征图。形式上,我们首先设计了一个两层残差卷积神经网络,即 HanGlyph 来生成汉字的初始字形表示,并随后采用多个双向编码器 Transformer 块作为上层结构来捕获上下文敏感信息。同时,我们通过跳过连接方法将从 HanGlyph 模块的每一层提取的字形特征输入到底层的 Transformer 块中,以充分利用汉字的字形特征。由于HanGlyph模块可以获得任意汉字的足够字形表示,可以有效解决长期存在的词汇量不足问题。大量实验结果表明,GlyphCRM 在 9 个微调任务上大大优于之前基于 BERT 的最新模型,并且在专业领域和低资源任务上具有很强的可迁移性和泛化性。
二、结论
本文受汉字字形能够增强汉字表示的启发,提出了完全基于字形的汉字预训练表示模型——字形模型。为了验证其有效性,我们在中国NLU的一系列任务上进行了广泛的实验。GlyphCRM令人惊讶的性能是,它在9个中国NLU任务中优于以前的最先进的模型BERT。预训练过程和微调结果表明,与BERT相比,该模型具有更强的学习能力、可移植性和泛化能力。值得一提的是,一个更大的预先训练好的中文表示模型GlyphCRM即将问世(?等一手github叭)。
三、model
HanGlyph模块和双向编码器层。
GlyphCRM概述:
以上是关于论文泛读149GlyphCRM:汉字及其字形的双向编码器表示的主要内容,如果未能解决你的问题,请参考以下文章