R语言向量化运算:apply函数族用法心得
Posted 修罗神天道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言向量化运算:apply函数族用法心得相关的知识,希望对你有一定的参考价值。
当初入坑R语言的时候,就在各种场合看到老司机的忠告,“尽量避免使用循环!”一开始并不明白这其中的奥义,直到后来对R语言有深入接触后,才领会R语言在向量化运算方面的强大功能。本篇内容就总结小编在使用R语言向量化运算apply函数族的一些心得体会。
至于R写循环为什么执行效率低下,小编也从技术论坛上得到了一些解释。说是像for和while之类的循环语句是基于R本身来实现的,而apply函数族的向量化运算是基于C语言函数来实现的,所以二者的计算效率有很大差距。小编不是计算机出身,也不懂C,既然大神们这么说了就知道是这么回事就好啦。
所谓apply函数族,指的是以apply函数为核心,包括lapply, sapply, tapply, mapply, rapply, vapply, eapply等在内八个函数。先上个表格具体理解下每个函数的含义:
| 函数名 | 含义 |
| apply | apply |
| lapply | list apply |
| sapply | simplify list apply |
| tapply | table apply |
| mapply | mutiple list apply |
| rapply | recursively apply |
| vapply | vector apply |
| eapply | environment apply |
再上个图看一下apply函数族各函数之间的关系:
(图片来自张丹老师博客http://blog.fens.me/r-apply/)
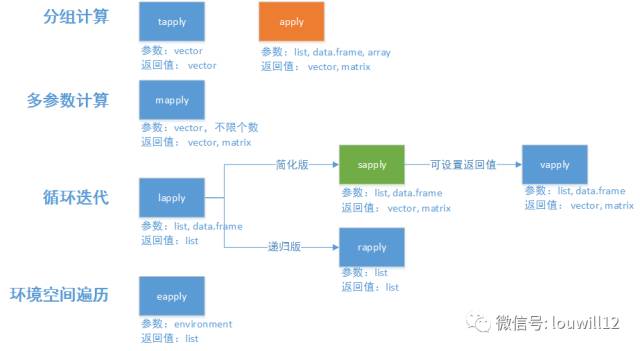
apply函数
作为该函数族最原始最核心的函数,apply函数一直担任着向量化运算的艰巨任务。apply函数可以对矩阵和数组以及数据框按照指定的函数在不同维度上进行循环运算,其用法如下:
apply(X,margin,FUN,...)
X:矩阵,数组,数据框
margin:对象维度,表示按行还是按列,1表示行2表示列
FUN:对X执行运算的函数
具体用法可看实例:
x <- cbind(x1 = 3, x2 = c(4:1, 2:5))
dimnames(x)[[1]] <- letters[1:8]
(x1<-apply(x, 2, mean, trim = .2))
x1 x2
3 3
(col.sums <- apply(x, 2, sum))
x1 x2
24 24
(row.sums <- apply(x, 1, sum))
a b c d e f g h
7 6 5 4 5 6 7 8
rbind(cbind(x, Rtot = row.sums),
Ctot = c(col.sums, sum(col.sums)))
x1 x2 Rtot
a 3 4 7
b 3 3 6
c 3 2 5
d 3 1 4
e 3 2 5
f 3 3 6
g 3 4 7
h 3 5 8
Ctot 24 24 48
tapply函数
tapply函数应用于分组循环计算,其功能类似于dplyr包中的group by函数。其用法如下:
tapply(X,INDEX,FUN,...,simplify=TRUE)
X:向量
INDEX:用于分组的索引
FUN:应用于X的函数
. . .:接收多个数据
simplify:返回值是否数组化
用法实例:对iris数据集中按花种类计算花瓣宽度的均值
attach(iris)
tapply(Petal.Width,Species,mean)
setosa versicolor virginica
0.246 1.326 2.026
lapply和sapply函数
这两个函数放一起讲,那当然是它们实在太相似了。lapply函数顾名思义,list apply,除了其对象参数是一个list或者data.frame之外,其返回值也是一个list。而sapply函数作为一个简化版的lapply,其返回值形式可以不是list。二者用法如下:
lapply(X,FUN,...)
sapply(X,FUN,...,simplify=TRUE,USE.NAMES=TRUE)X:矩阵,数组,数据框
FUN:作用在对象上的函数
. . .:其他参数(可选)
simplify:是否数组化
USE.NAMES:若X为一个字符串,TRUE表示设置字符串为数据名
用法实例:
e<-list(alpha=3:7,beta=exp(2:8),gamma=c(TRUE,FALSE,FALSE,TRUE))
lapply(e, fivenum)
$alpha
[1] 3 4 5 6 7
$beta
[1] 7.389056 37.341843 148.413159 750.030976 2980.957987
$gamma
[1] 0.0 0.0 0.5 1.0 1.0
#simplify参数为FALSE时,sapply与lapply效果一样
sapply(e, fivenum,simplify=FALSE)
$alpha
[1] 3 4 5 6 7
$beta
[1] 7.389056 37.341843 148.413159 750.030976 2980.957987
$gamma
[1] 0.0 0.0 0.5 1.0 1.0
#simplify参数为TRUE时,sapply函数返回值数组化
sapply(e, fivenum,simplify=TRUE)
alpha beta gamma
[1,] 3 7.389056 0.0
[2,] 4 37.341843 0.0
[3,] 5 148.413159 0.5
[4,] 6 750.030976 1.0
[5,] 7 2980.957987 1.0
vapply函数
vapply函数与sapply函数也较为类似,不同的是它可以通过FUN.VALUE参数对返回值行名进行预定义。其用法如下:
vapply(X,FUN,FUN.VALUE,...,USE.NAMES=TRUE)
FUN.VALUE:通用型向量,以控制返回值的行名
用法实例:
g <- data.frame(cbind(x1=3, x2=c(2:1,4:5)))
vapply(g,cumsum,FUN.VALUE=c('a'=0,'b'=0,'c'=0,'d'=0))
x1 x2
a 3 2
b 6 3
c 9 7
d 12 12
rapply函数
rapply函数可以理解为一个递归版本的lapply,同样只处理list类型的数据,对list中的每个元素进行递归遍历,如果list元素还包括子元素也需要继续遍历。其用法如下:
rapply(X, FUN,classes = ANY,deflt=NULL,how=c(unlist, replace, list),...)
X:list对象
FUN:作用在对象上的函数
classes:关于类名的字符向量,若为any则表示为任意类型
deflt:默认结果,若how参数选择了replace则不能使用
how:字符串匹配的三种结果
. . .:更多参数
rapply用法实例:
X <- list(list(a = pi, b = list(c = 1:1)), d = "a test")
rapply(X, sqrt, classes = "numeric", how = "replace")
[[1]]
[[1]]$a
[1] 1.772454
[[1]]$b
[[1]]$b$c
[1] 1
$d
[1] "a test"
mapply函数
mapply函数也是sapply函数的近亲,从函数名来看就知道mapply函数可以接受多个数据对象。其使用格式较前面几个有略微区别:
mapply(FUN,...,MoreArgs = NULL,SIMPLIFY = TRUE,USE.NAMES=TRUE)
FUN:作用对象函数
. . .:多个数据对象
MoreArgs:参数列表
SIMPLIFY:返回值是否数组化
USE.NAMES:控制返回值行名
mapply用法实例:
x<-1:8
y<-3:-5
z<-round(runif(10,-5,5))
mapply(max,x,y,z)
[1] 5 2 3 4 5 6 7 8 2 3
eapply函数
eapply函数可以遍历计算R当前环境空间中的每个变量。其用法如下:
eapply(env,FUN,...,all.names=FALSE,USE.NAMES=TRUE)
env:定义的R环境空间
FUN:作用在对象上的函数
. . .:更多参数,可选
all.names:逻辑值,指示是否对所有值使用函数
USE.NAMES:控制返回值行名
epplay函数用法实例:
#定义一个环境空间
env <- new.env(hash = FALSE)
#向这个环境空间中存入3个变量
env$a <- 5:15
env$beta <- exp(3:8)
env$logic <- c(TRUE, FALSE, FALSE, TRUE)
env
#查看env空间中的变量
ls(env)
[1] "a" "beta" "logic"
ls.str(env)
a : int [1:11] 5 6 7 8 9 10 11 12 13 14 ...
beta : num [1:6] 20.1 54.6 148.4 403.4 1096.6 ...
logic : logi [1:4] TRUE FALSE FALSE TRUE
#对环境空间内所有对象遍历计算均值
eapply(env, mean)
$logic
[1] 0.5
$beta
[1] 784.0195
$a
[1] 10
总结
apply函数族作为R语言向量化运算的精髓,可以完全代替运算效率低下的循环,在平常练习中加强数据化思维的训练,对于apply函数族的8个函数较常用的是apply、lapply函数和sapply函数,其余函数虽不常用但也需要了解一二。
以上是关于R语言向量化运算:apply函数族用法心得的主要内容,如果未能解决你的问题,请参考以下文章