NLP基础知识点:ROUGE
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP基础知识点:ROUGE相关的知识,希望对你有一定的参考价值。
ROUGE: A Package for Automatic Evaluation of Summaries
1. 简介
ROUGE 指标由 Chin-Yew Lin 提出, 主要用于评估机器翻译和文章生成摘要的质量,其全称是 (Recall-Oriented Understudy for Gisting Evaluation)
它主要基于召回率和n-gram
2. 预备知识:召回率(Recall)与F1值
先复习一下召回率(Recall)的概念
召回率即查全率,是所有正例被正确预测的比例。
这里放上西瓜书的上对查准率与查全率的定义

F1值是综合考虑了查准率和查全率的性能度量。

3. 论文部分
NMT中漏翻会导致低召回率
论文中介绍了四种ROUGE的形式
- ROUGE-N: 在 N-gram层面上计算召回率
- ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列
- ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列
- ROUGE-S: ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许"跳词 (Skip)",即单词不需要连续出现。
3.1 ROUGE-N: N-gram Co-Occurrence Statistics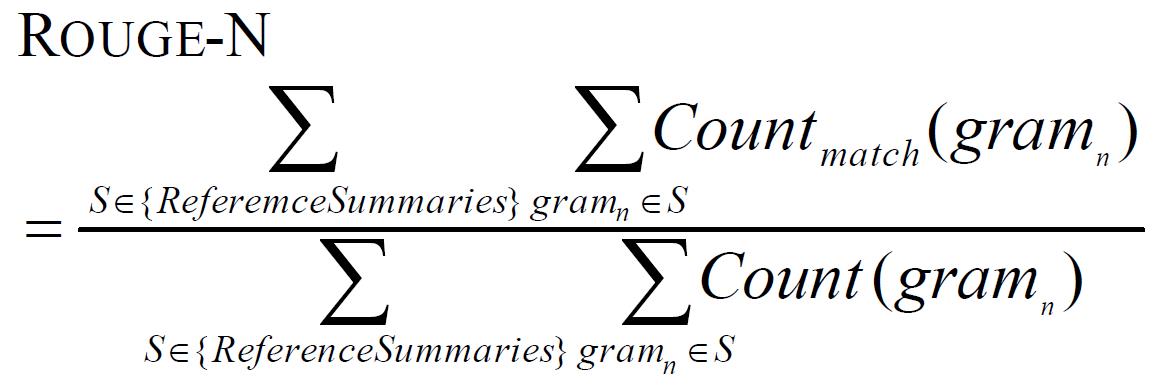
N
/
n
N/n
N/n为n-gram的长度
R
e
f
e
r
e
n
c
e
S
u
m
m
a
r
i
e
s
ReferenceSummaries
ReferenceSummaries 为样本的一段参考摘要(一段话由多个句子组成),
S
S
S为其中的一个句子。
C
o
u
n
t
m
a
t
c
h
(
g
r
a
m
n
)
Count_{match}(gram_n)
Countmatch(gramn)是候选摘要和一组参考摘要中共同出现的n-grams的最大数量。
下面示例来自于知乎
生成文本:“I love China very much”(1-gram有5个词组,2-gram有4个)
参考文本:“I love my hometown very much”(1-gram有6个词组,2-gram有5个)
1-gram下两者的公共词组有{‘I’, ‘love’, ‘very’, ‘much’}4个,ROUGE-1=4/6
2-gram下两者的公共词组有{‘I love’, ‘very much’}2个,ROUGE-2=2/5。
上述情况为用一个候选摘要与一个参考摘要进行评估的计算公式
假设有 M 个reference,ROUGE-N 会分别计算candidate summary和这些reference的 ROUGE-N 分数,并取其最大值。
This procedure is also applied to computation of ROUGE-L , ROUGE-W , and ROUGE-S.
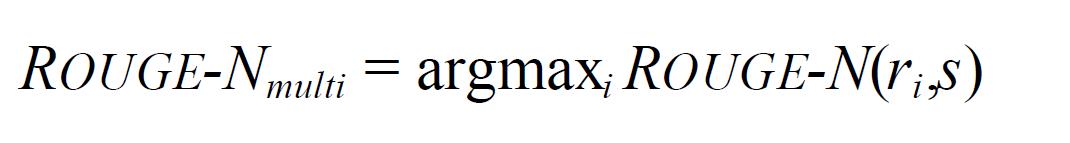
3.2 ROUGE-L: Longest Common Subsequence
3.2.1 Sentence-Level LCS
X是一个reference summary sentence(长度为m), Y是一个candidate summary sentence(长度为n)
LCS(X, Y)是X,Y的最长子序列长度。
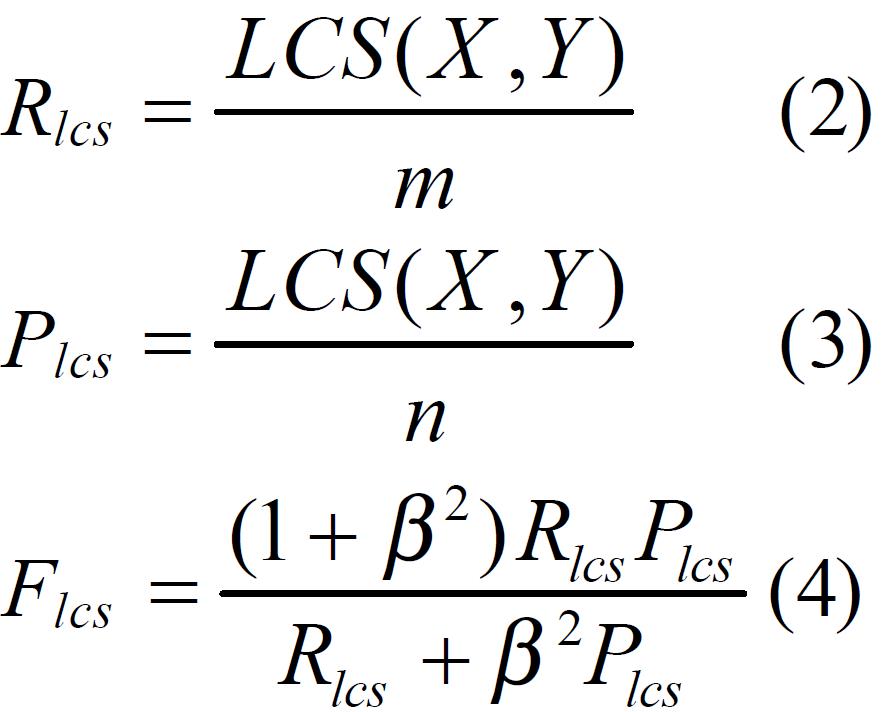
R
l
c
s
R_lcs
Rlcs为召回率,
P
l
c
s
P_lcs
Plcs为准确率,
F
l
c
s
F_lcs
Flcs为F1度量的一般形式。
ROUGE-L还以自然的方式捕捉句子级结构。
下面给出一个例子:

使用S1作为参考,S2和S3作为候选句,S2和S3将有相同的ROUGE-2评分,因为它们都有一个bigram,即“the gunman”。
但这两句话的语义,可以说是恰恰相反的。
在ROUGE-L中,令
β
\\beta
β=1,S2 = (2x0.75x0.75)/(0.75+0.75) = 0.75,S3 = (2x0.5x0.5)/(0.5+0.5) = 0.5
根据ROUGE-L,候选句S2的得分更高,这和人的认知也是一致的。
然而,LCS有一个缺点,它只计算主要的在序列中的词;因此,其他可选的LCSes和较短的序列不会反映在最终得分中。
例如再来一个句子S4. the gunman police killed
S3和S4的ROUGE-2得分是相同的,这显然是不合理的。
3.2.2 Summary-Level LCS
使用union LCS(union longest common subsequence)评估一个reference summary sentence和每个candidate summary sentence的匹配程度。
r
i
r_i
ri:reference summary sentence
c
j
c_j
cj: candidate summary sentence
一个reference summary有u个句子,总计有m个词
一个candidate summary有v个句子,总计有n个词
计算公式如下:
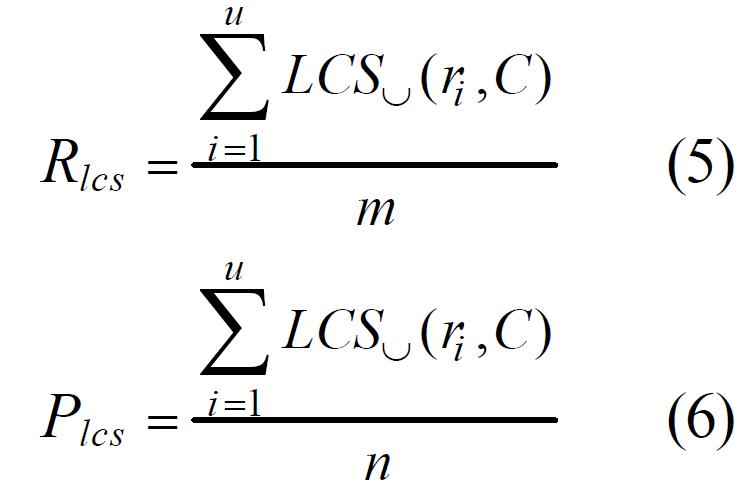
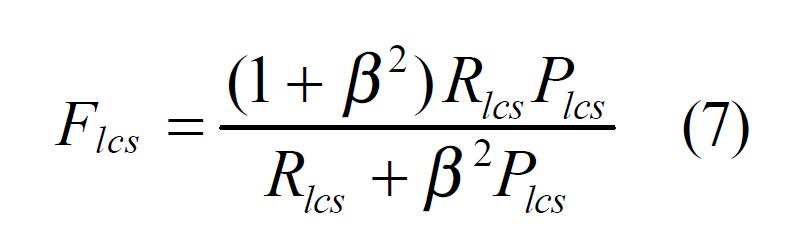
论文中指出参数
β
\\beta
β在国际评比中一般设为∞,所以F值一般由召回率R确定。
L
C
S
U
(
r
i
,
C
)
LCS_U(r_i, C)
LCSU(ri,C)是
r
i
r_i
ri和候选summary C的union LCS的召回率
下面用一个具体例子来说明union LCS如何计算。
ri = w1 w2 w3 w4 w5
C中有2个句子,c1 = w1 w2 w6 w7 w8 ,c2 = w1 w3 w8 w9 w5
LCS(r1, c1) = “w1 w2”, LCS(r1, c2) = “w1 w3 w5”.
union LCS = “w1 w2 w3 w5”
L
C
S
U
(
r
i
,
C
)
=
4
/
5
LCS_U(r_i, C) = 4/5
LCSU(ri,C)=4/5
以上是关于NLP基础知识点:ROUGE的主要内容,如果未能解决你的问题,请参考以下文章