NLP基础知识点:CIDEr算法
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP基础知识点:CIDEr算法相关的知识,希望对你有一定的参考价值。
CIDEr的主要应用场景为Image Caption
参考论文:[1] Vedantam R , Zitnick C L , Parikh D . CIDEr: Consensus-based Image Description Evaluation[J]. IEEE, 2015.
目的是评估对图像 I i I_i Ii,一个候选句(candidate sentence) c i c_i ci和一组和一组图像描述 S i = { s i 1 , . . . , s i m } S_i = \\{s_{i1},...,s_{im}\\} Si={si1,...,sim}的一致性有多好。
直觉上,一致性度量将编码候选句子中的n-grams在参考句子中出现的频率。
同样,参考句中不存在的n-grams也不应该出现在候选句中。
最后,通常出现在数据集中所有图像上的n-grams应该被赋予较低的权重,因为它们的信息可能较少。
- h k ( s i j ) h_k(s_{ij}) hk(sij): n-gram ω k \\omega_k ωk出现在参考句 s i j s_{ij} sij中的次数
- h k ( c i ) h_k(c_{i}) hk(ci): n-gram ω k \\omega_k ωk出现在候选句 c i c_i ci中的次数
为每个n-gram
ω
k
\\omega_k
ωk计算TF-IDF权重
Ω is the vocabulary of all n-grams
I is the set of all images in the dataset.
与参考集相对应的公式如下:
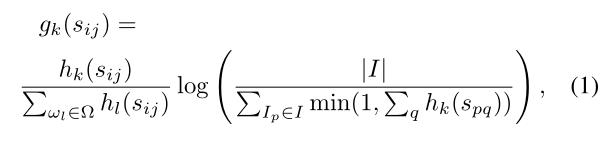
这个公式中,
TF部分是归一化的
ω
k
\\omega_k
ωk的词频
IDF部分的分子为图像的总数量,分母为其参考句中含有
ω
k
\\omega_k
ωk的图像的数量。
同理,应该可以计算一个
g
k
(
c
i
)
g_k(c_i)
gk(ci),假设只有一个候选句
它的公式可能为:(这里原论文没有给出计算公式,只是猜测)
g
k
(
c
i
)
=
T
F
(
k
)
∗
I
D
F
(
k
)
g_k(c_i)= TF(k) * IDF(k)
gk(ci)=TF(k)∗IDF(k)
T F ( k ) = h k ( c i ) ∑ w ∈ Ω h l ( c i ) TF(k) = \\frac{h_k(c_i)}{\\sum_{w\\in\\varOmega} h_l(c_i)} TF(k)=∑w∈Ωhl(ci)hk(ci)
I D F ( k ) = l o g ( ∣ I ∣ ∑ I p ∈ I m i n ( 1 , h k ( c p ) ) ) IDF(k) = log(\\frac{|I|}{\\sum_{I_p\\in I}min(1, h_k(c_{p}))}) IDF(k)=log(∑Ip∈Imin(1,hk(cp))∣I∣)
计算一个平均余弦相似度
C
I
D
E
r
n
(
c
i
,
S
i
)
CIDEr_n(c_i, S_i)
CIDErn(ci,Si)(参考句有
m
m
m句)
g
n
(
c
i
)
g^n(c_i)
gn(ci)是一个由所有的
g
k
(
c
i
)
g_k(c_i)
gk(ci)组成的向量(所有长度为n的n-grams),
g
n
(
s
i
j
)
g^n(s_{ij})
gn(sij)同理
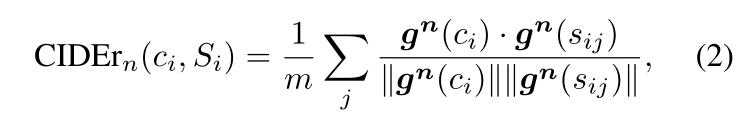
进行一个不同n-grams的加权求和,从经验来看,取
w
n
=
1
/
N
w_n= 1/N
wn=1/N效果最佳
原论文中使用N = 4.
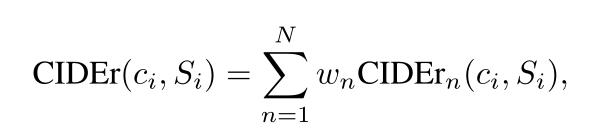
改进:CIDEr-D
(后续有空做整理)
以上是关于NLP基础知识点:CIDEr算法的主要内容,如果未能解决你的问题,请参考以下文章