Django网站开发——HTMLCSSPython知识点回顾
Posted Mrs.King_UP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django网站开发——HTMLCSSPython知识点回顾相关的知识,希望对你有一定的参考价值。
工作方式
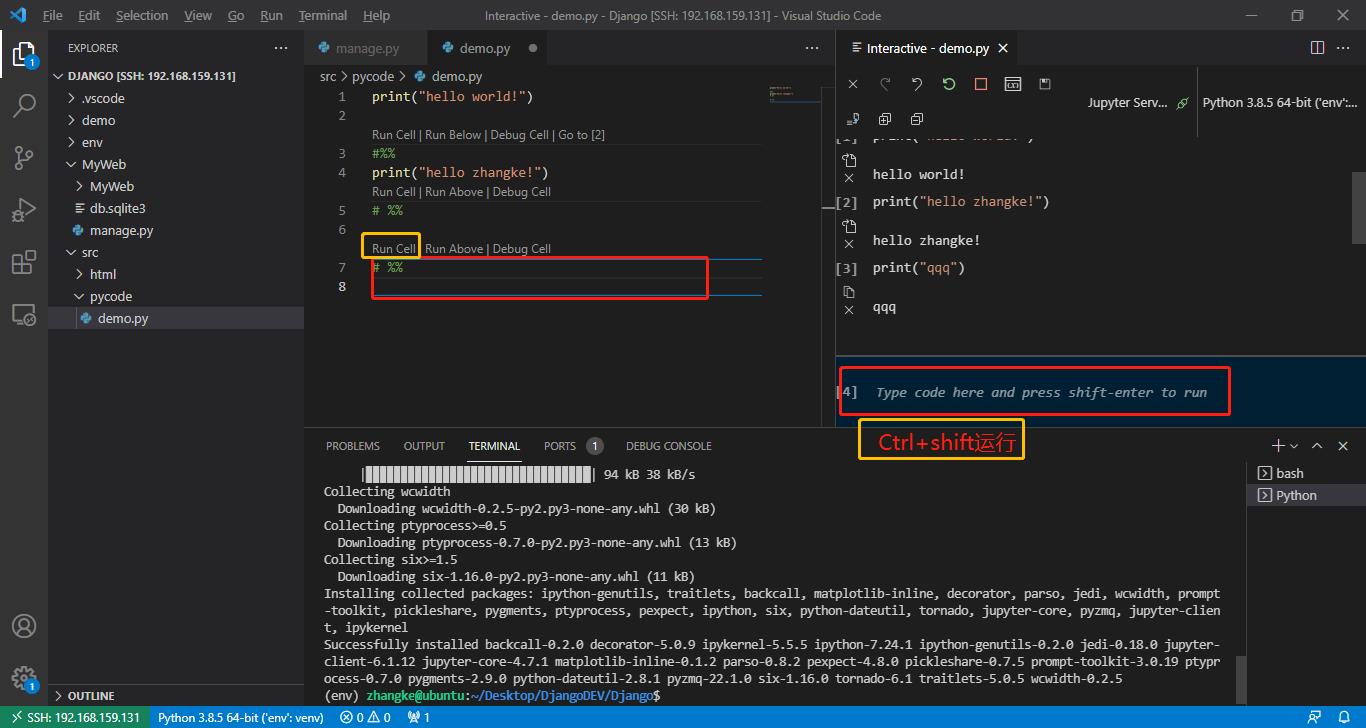
VSCode中三种工作方式,红框中写入代码,黄框为运行方式(类似Anaconda的工作形式),还有一种是写完代码,在终端中输入python demo.py
Python
1. 数据类型
- 字符串:单引号、双引号、三引号
- 数值
- 布尔
- 其他:[]列表->可变;()元组->不可变;{} 字典->可变
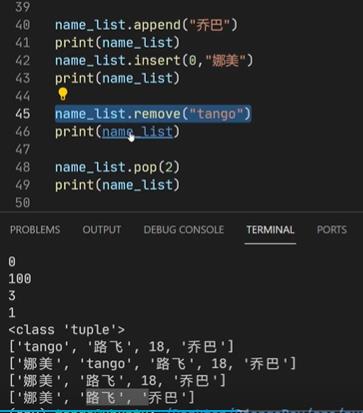
- list列表中的增删查改:pop和remove都是删除,但是pop删除之后会将删除结果返回()
可以通过key直接访问value值,若key在字典中,返回value,若key不在字典中,则添加新的键值对- user_info.keys()获取所有的key
- user_info.values()获取所有的value
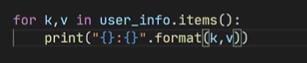
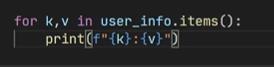
- user_info.items()同时获取key,value
str类型:- 字符串逆置->my_str=my_str[::-1]
- 字符串切片
- a,b=b,a 两数交换

注释技巧:(1)ctrl+/ 可以使用#注释一行或多行;(2)三引号;(3)Shift+Alt 控制鼠标选择多行,能够同时输入#
2. 流程控制
判断语句:if else
if name in name_list:
print("OK")
else:
print("no")
if a>b and print(c):#短路思想:and中如果前面的条件为假,后边就不用判断了
print("OK")
else:
print("no")
if a>5:
print("a>5")
elif a<5:
print("a<5")
else:
print("a=5")
3. python方法实现
def test(msg):#msg为形参
print(msg)
#调用
test("zhangke")
————————————————
def test(msg,msg2=0):#msg为形参
print(msg,msg2)
#调用
test("zhangke")
————————————————
def test(msg,msg2=0):#msg为形参,msg2为默认形参
print(msg,msg2)
#调用
test("zhangke",1)
html
1. 标签回顾
<html>
<head>
<script>
function test(){
alert("点击按钮啦!")
}
</script>
</head>
<body>
<p>一段文字</p>
<!-- 换行 -->
<br>
<table>
<tr>
<td>1</td>
<td>2</td>
</tr>
<tr>
<td>3</td>
<td>4</td>
</tr>
</table>
<a href="http://www.baidu.com"></a>
<div></div>
<input type="text" value="123">
<input type="button" onclick="test();" value="提交">
</body>
</html>
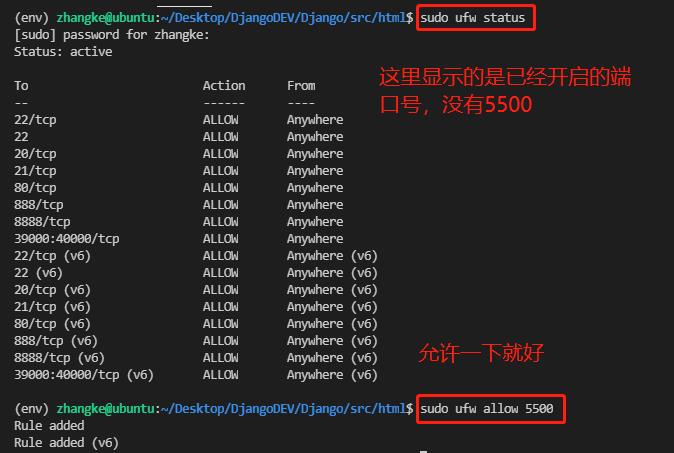
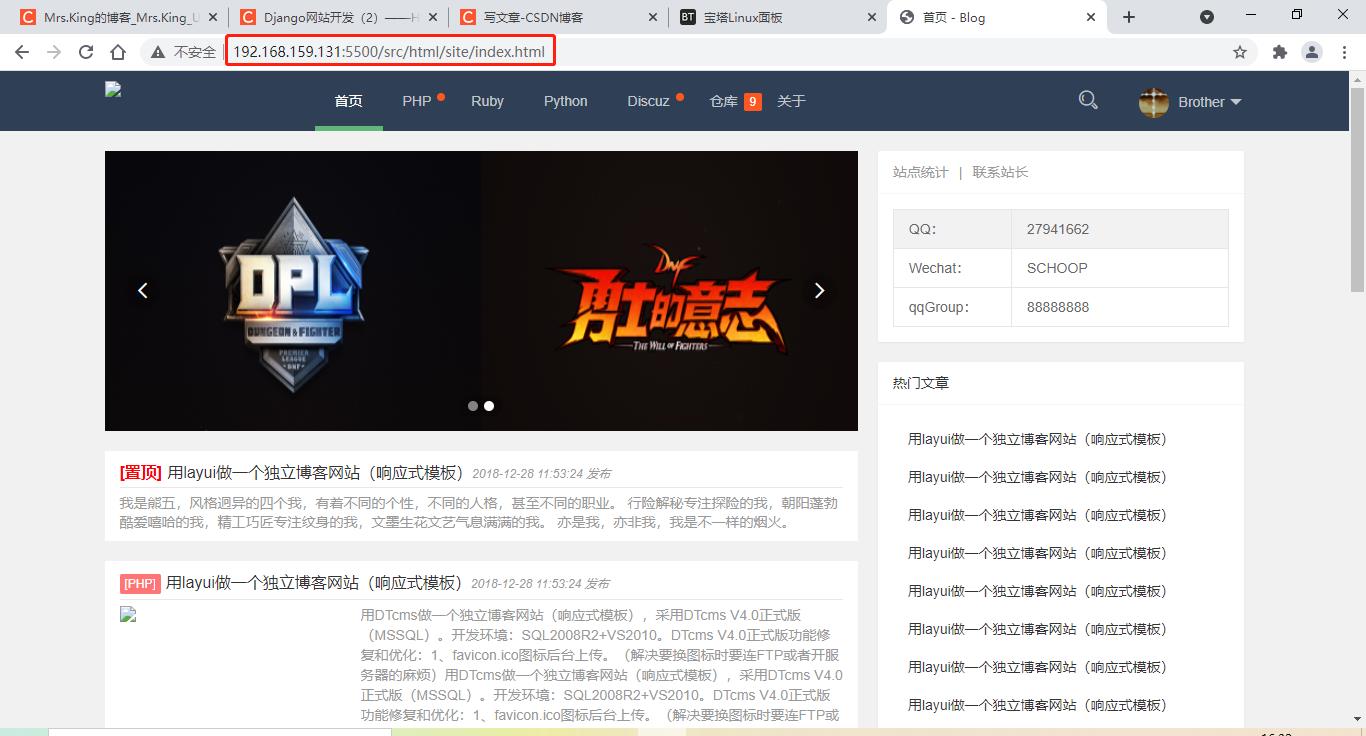
项目时部署在Ubuntu上的,所以可以在Ubuntu中找到相应的文件夹可以进行访问,但是每次都需要到Ubuntu中访问比较麻烦,在VSCode中安装插件Live Server,安装成功后会在右下角出现go live,分配一个端口号,比如我的是5500,就可以在Ubuntu浏览器上通过192.168.159.131/5500/src/html/,访问网页,但是在windows的浏览器上仍然不可访问,为什么哪?因为此端口号没有开启,通过下方的设置,就可以通过192.168.159.131/5500//src/html/访问啦!
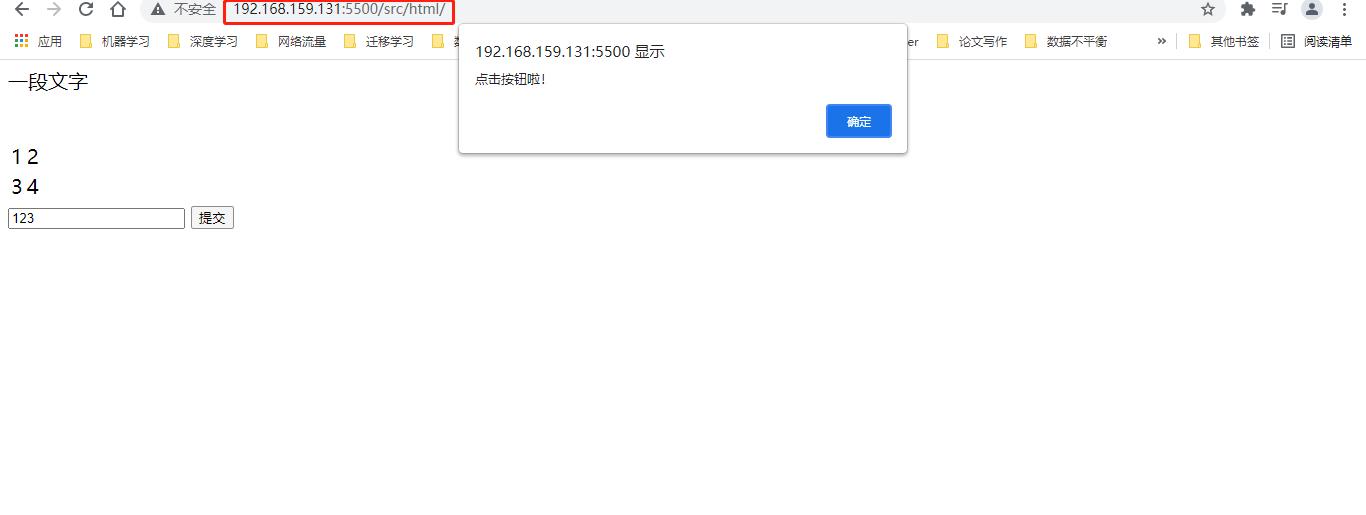
时过若干天,我回来了,继续我的Django之行,But,通过上述方式访问不到网页了,此时,你需要重新点击go live
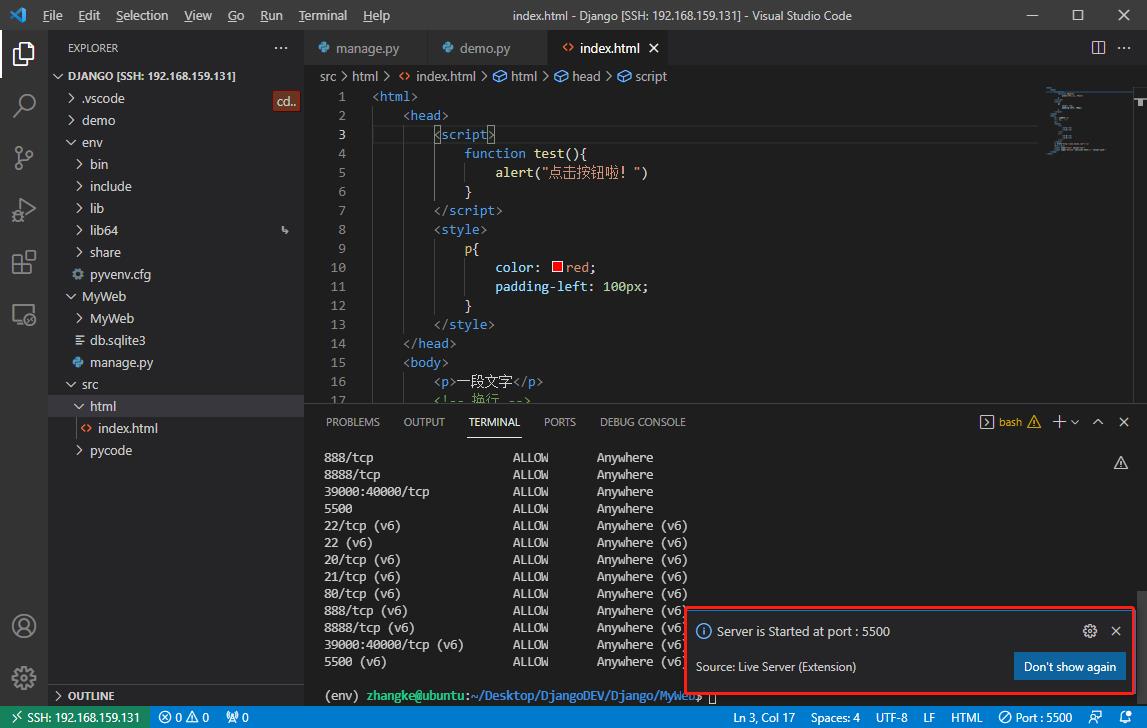
忘记了宝塔登陆的方式,那就这样

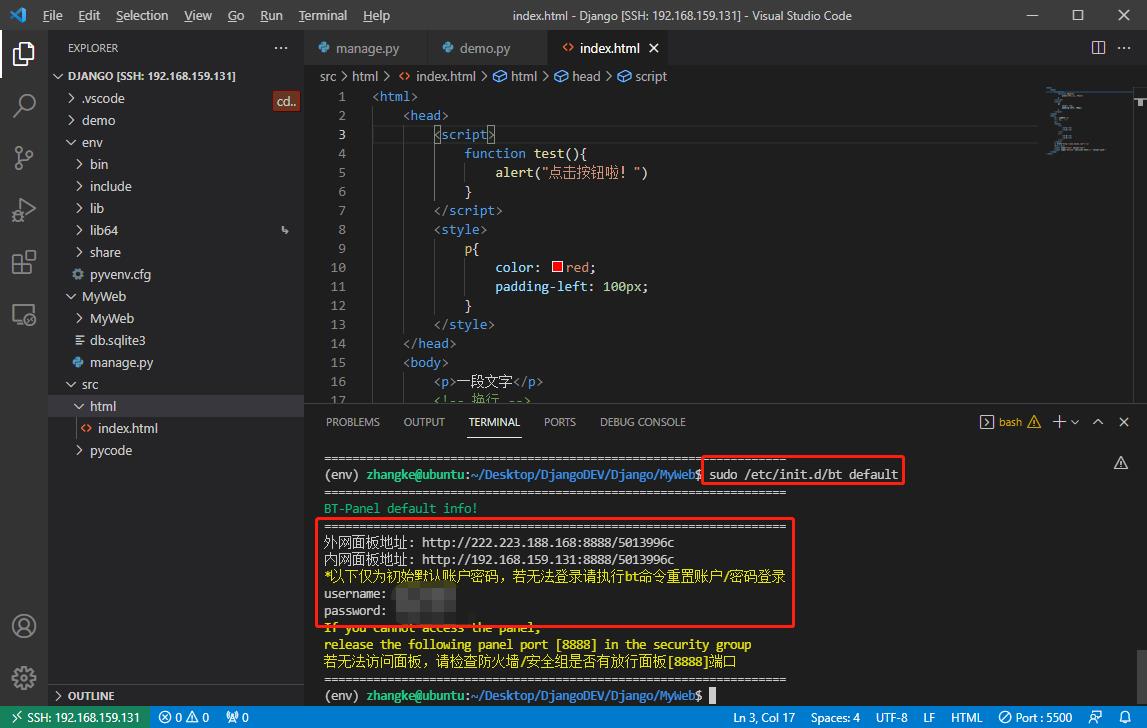
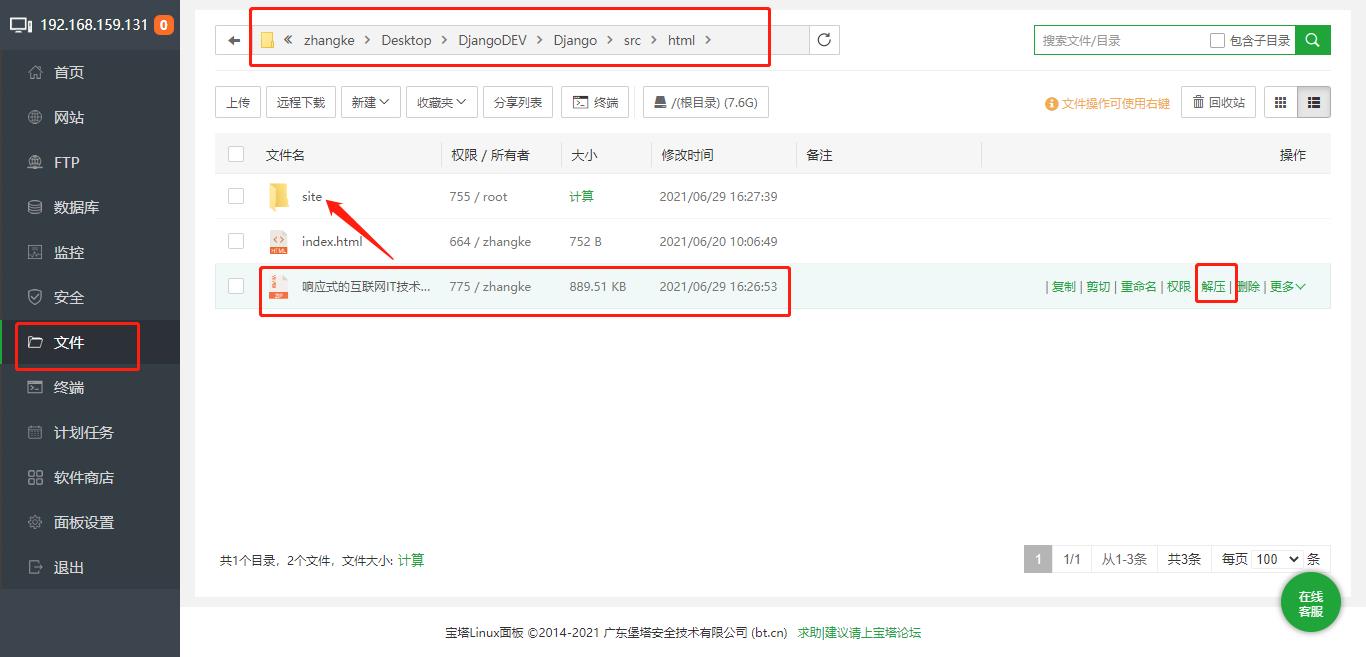
嘿嘿嘿,这不就出来了吗,登陆进行,宝塔这玩意儿贼好用,可以通过它访问到Ubuntu环境,还可以将windows上的文件/文件夹/压缩包上传到到Ubuntu上相应的文件夹下解压缩,下边就是上传的压缩包,解压,访问解压文件中的页面的过程。
Python爬取信息
安装BS4、requests库:pip install BS4 / pip installrequests
直接上代码:
#BS4 requests
import requests
from bs4 import BeautifulSoup
from time import sleep
class robot():
def __init__(self):
self.url="https://kakawanyifan.com/"#随便找了个网站爬一下
def getInfo(self):
try:
req=requests.get(self.url)
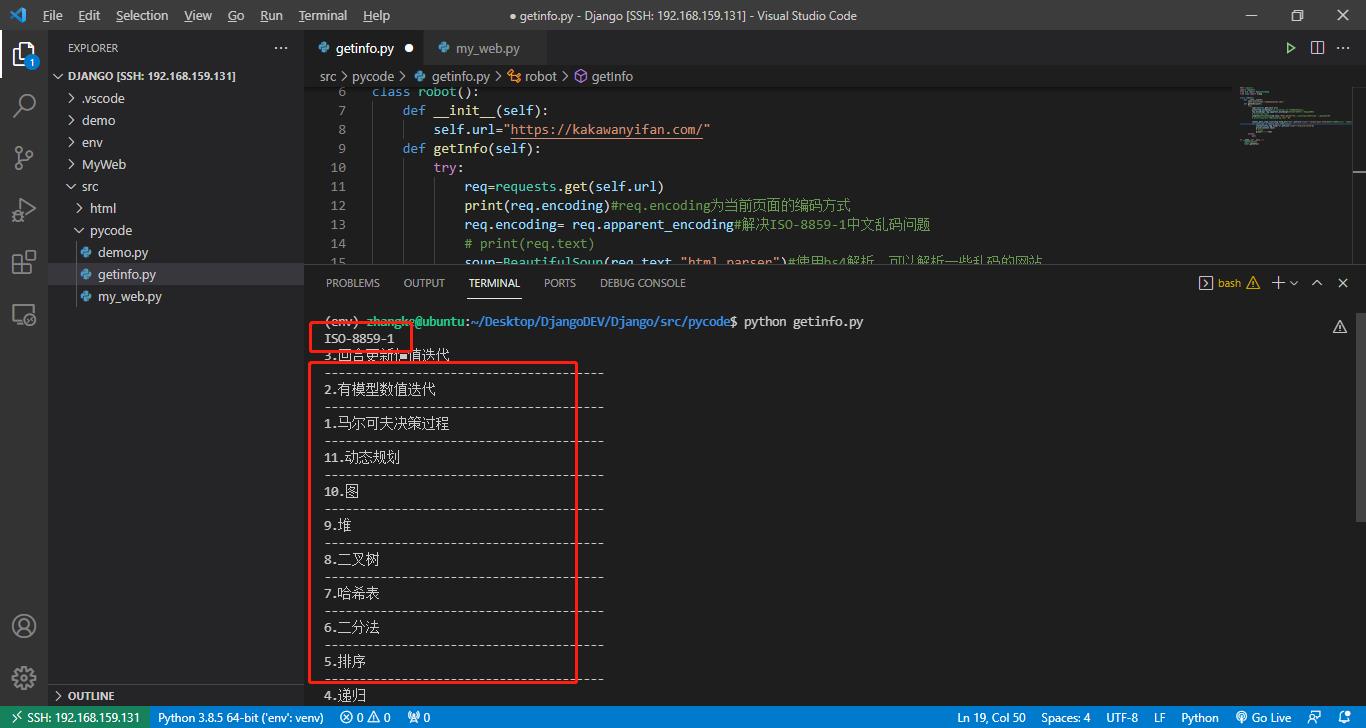
print(req.encoding)#req.encoding为当前页面的编码方式
req.encoding= req.apparent_encoding#解决ISO-8859-1中文乱码问题
# print(req.text)
soup=BeautifulSoup(req.text,"html.parser")#使用bs4解析,可以解析一些乱码的网站
# print(soup)#其实跟上边的req.text一样
recent_post_item_list=soup.find_all("div",attrs={"class":"recent-post-item"})#返回列表:寻找所有的class为recent-post-item的div
for info_tag in recent_post_item_list:
content=info_tag.find("a",attrs={"class":"article-title"})
print(content.text)
# break
print("----"*10)
except:
pass
if __name__=="__main__":
robot=robot()
robot.getInfo()
运行结果:
python模拟网络请求
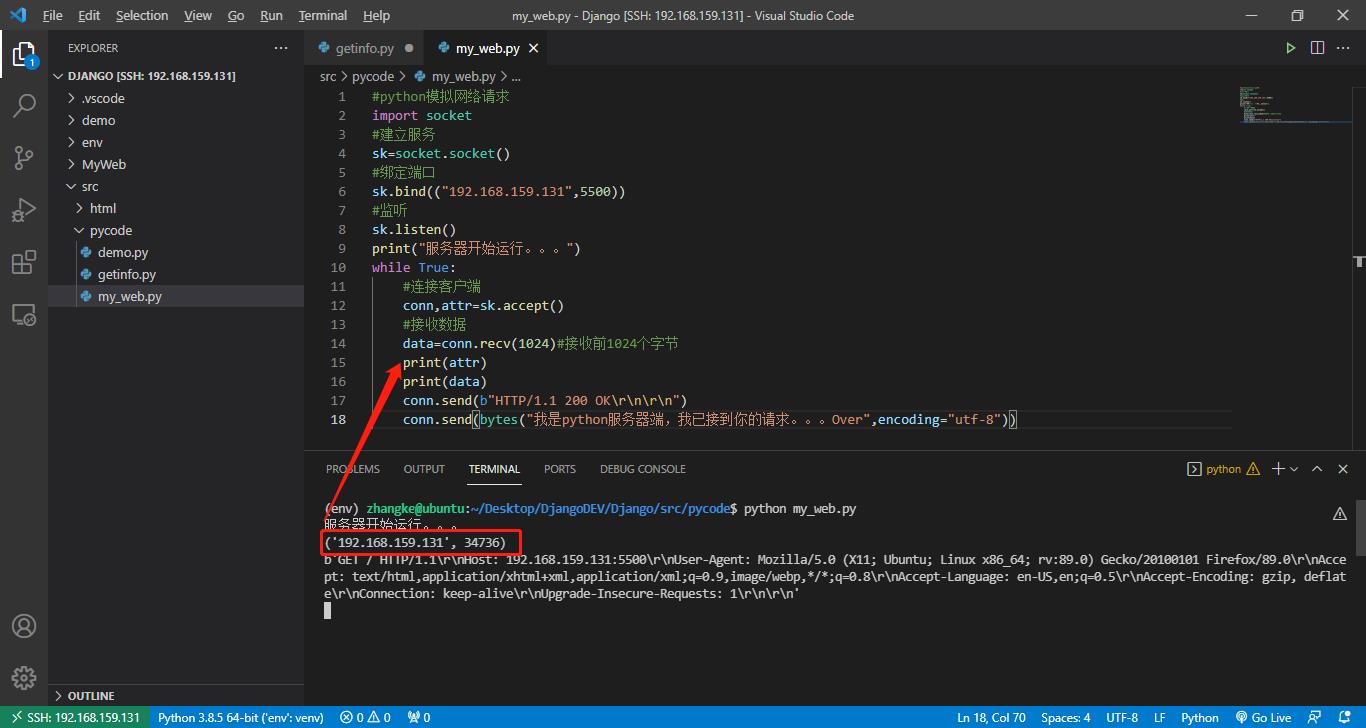
废话不多说,直接上代码
#python模拟网络请求
import socket
#建立服务
sk=socket.socket()
#绑定端口
sk.bind(("192.168.159.131",5500))
#监听
sk.listen()
print("服务器开始运行。。。")
while True:
#连接客户端
conn,attr=sk.accept()
#接收数据
data=conn.recv(1024)#接收前1024个字节
print(attr)
print(data)
conn.send(b"HTTP/1.1 200 OK\\r\\n\\r\\n")
conn.send(bytes("我是python服务器端,我已接到你的请求。。。Over",encoding="utf-8"))
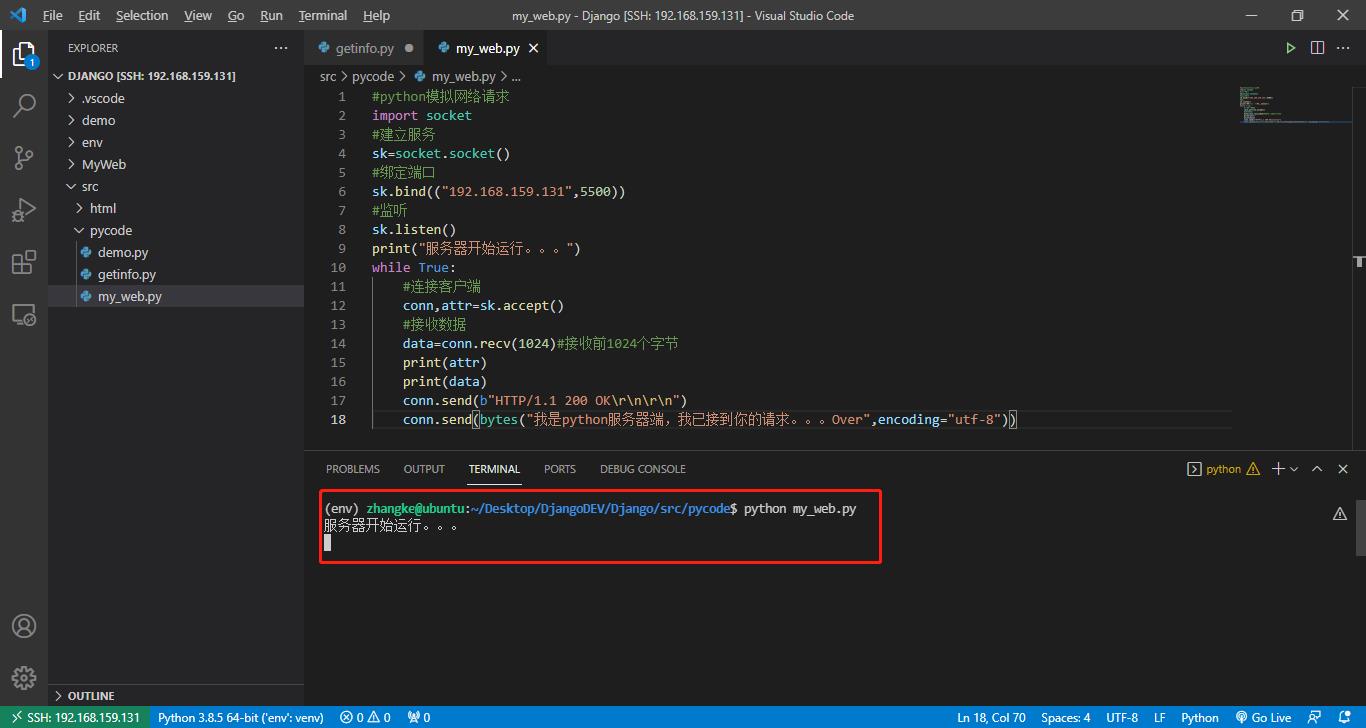
当在浏览器中输入地址访问时,出现:
以上是关于Django网站开发——HTMLCSSPython知识点回顾的主要内容,如果未能解决你的问题,请参考以下文章