MySQL笔记基础篇
Posted 可持续化发展
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL笔记基础篇相关的知识,希望对你有一定的参考价值。
小铭今天来到了湖北省图书馆,决定系统地补一下mysql。写这篇文章是为了记录一下,看书过程中的收获。
目录
MySQL8的新特性
①更简便的NoSQL支持;
②新增了隐藏索引和降序索引;
③更完善的JSON支持,JSON数据存储,JSON_ARRAYAGG()和JSON_OBJECTAGG(),将参数聚合为JSON数组或对象,优化了JSON的排序和更新;
④新增caching_sha2_password授权插件、FIPS模式支持;
⑤优化了InnoDB的自增、索引、加密、死锁、共享锁等方面,支持原子DDL;
⑥之前的字典数据都存在元数据文件和非事务表中。8新增了事务数据字典,用于存储数据库对象信息,该字典存在内部事务表中;
⑦原子DDL,Automic DDL。目前只有InnoDB支持原子DDL。其作用:将与DDL操作相关的数据字典更新、存储引擎操作、二进制日志写入结合到一个单独的原子事务中,使得即使服务器崩溃,事务也会提交或回滚。用支持原子操作的存储引擎创建的表,在执行drop table、create table、alter table、rename table、truncate table等操作时,都支持原子操作,即事务要么完全操作成功,要么失败回滚,不再进行部分提交。
⑧优化器增强,验证索引的必要性时先将索引隐藏,如果优化器性能无影响,则删掉索引。
⑨支持支持递归和非递归的通用表达式。通用表达式通过在select或其他特定语句前使用with语句对临时结果集进行命名。
⑩支持窗口函数、正则表达式。TempTable存储引擎取代Memory成为内部临时表的默认存储引擎。
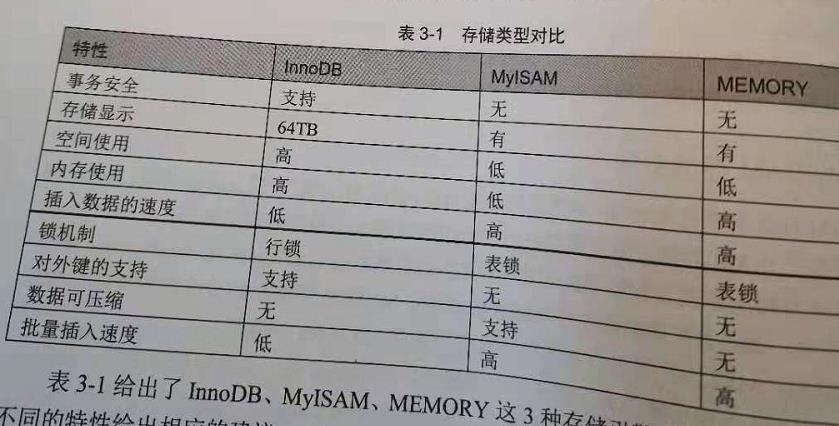
InnoDB、MyISAM、MEMORY存储引擎
存储引擎影响的是表的类型。创建新表的时候,如果不指定存储引擎,那么系统会使用默认的。可以通过增加ENGINE关键字来设置新表的存储引擎。MySQL5.5之前默认的是MyISAM,之后默认InnoDB。为了提高MySQL的使用效率和灵活性。存储引擎指定了表的类型,即如何存储和索引数据、是否支持事务等,也决定了表在计算机中的存储方式。
InnoDB
事务型数据库的首选。MySQL5.6之后,为默认存储引擎。它为MySQL 的表提供了外键、事务处理、提交、回滚、崩溃恢复能力和多版本并发控制的事务安全。优势为:良好的事务管理、崩溃恢复能力和并发控制。缺点是读写效率略差,占用的数据空间相对较大。InnoDB支持自动增长列auto_increment,支持外键。如果需要事务处理、并发控制的或频繁进行更新、删除操作的,选InnoDB。
- InnoDB 是为处理巨大数据量提供最大性能而设计的。
- InnoDB将表和索引存放在一个逻辑表空间中。表中存储的记录是按照主键顺序存放的(主键比较大小,从小到大)。如果没有显示指定主键,InnoDB 会为每一行生成一个6字节的ROWID,作为主键。
InnoDB表在使用过程中的特点有:
①自动增长列。InnoDB表的自动增长列可以手动插入,但如果插入的值为空,则实际插入的将是自动增长后的值。
②外键约束。创建外键时,可以指定在删除、更新父表时,对子表进行相应的操作。关键字restrict和no action 相同,是指限制在子表有关联记录的情况下父表不能更新;cascade表示父表在更新、删除时,更新、删除子表中对应记录。set null表示父表在更新或删除时,子表的对应字段被set null。导入多个表时,可以通过暂时关闭外键约束来加快处理速度,关闭命令是“set foreign_key_checks = 0;”;改回原状态用“set foreign_key_checks = 1;”。
③主键和索引。InnoDB的数据文件本身是以聚簇索引的形式保存的。聚簇索引被称为主索引,也是InnoDB表的主键。InnoDB表的每行数据都保存在主索引的叶子节点上。因此,所有InnoDB表都必须包含主键,如果创建表时候,没有显示指定主键,那么InnoDB存储引擎会自动创建一个长度为6个字节的long类型隐藏字段作为主键。推荐所有InnoDB表都显示指定主键。在InnoDB表上出主键外的其他索引都叫二级索引。
④存储方式。InnoDB存表和索引的方式有两种:
一、使用共享表空间存储。
二、使用多表空间存储。
MyISAM
MyISAM的表存储为三个文件,扩展名为.frm、.MYD、MYI。frm存储表的结构,MYD(mydata)存储数据,MYI(myindex)存储索引。优势为:占用空间小,处理速度快。缺点是不支持事务完整性和并发性。如果应用以读操作和插入操作为主,只有极少的更新和删除,并且对事务的完整性没有要求、没有并发写操作,那么选MyISAM。
MEMORY
使用存在内存中的数据来创建表,将数据保存在RAM中,可提供极快的访问速度。每个表对应一个磁盘文件。.frm存储表的结构,数据存在内存中。有利于数据的快速处理。默认使用hash索引。但一旦服务关闭,表中的数据就会丢失。表的大小取决于max_rows(可以在创建表时指定)和max_heap_table_size(默认为16MB)。优势是:数据处理速度快。缺点是数据易丢失,生命周期短,安全性不高,对表的大小有限制,不能建太大的表。如果要求数据处理速度快,但安全性不高,选它。MEMORY表通常用于更新不太频繁的小表,用于快速访问。
- 不支持TEXT、BLOB。
- 表在所有客户端之间共享。当不需要表中的数据时,需要释放内存,执行delete from或truncate table或drop table。
Archive:适合存储归档数据,如记录日志信息。如果只有插入和查询操作,选它。支持高并发的插入,但不是事务安全的。
一个数据库中不同表可以使用不同的存储引擎来满足需求和性能。如果一个表要求较高的事务处理,InnoDB。如果会被频繁查询,MYISAM。如果是用于查询的临时表,MEMORY。
范式
函数依赖:若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。
传递函数依赖:在R(U)中,如果X->Y, Y->Z, 则称Z对X传递函数依赖。
元组:表中的一行就是一个元组。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
全码:如果一个码包含了所有的属性,这个码就是全码。
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
第一范式(1NF),确保每列保持原子性。每一列都是不可分割的原子项。属性不可分。只要是关系数据库就是第一范式。
第二范式(2NF),确保每列都和主键相关。实体的属性要完全依赖主键。如果不完全依赖,则应该分离出一个新的实体。符合1NF,并且,非主属性完全依赖于码。
第三范式(3NF),确保每列都和主键列直接相关,而不是间接相关。要求每一个表都不包含其他表已经包含的非主键信息。符合2NF,并且,消除传递依赖。
BC范式,BCNF,在函数依赖范围内,它已经实现了彻底的分离,已消除了插入和删除的异常。3NF的“不彻底”性表现在可能存在主属性对码的部分依赖和传递依赖。
若一个关系达到了第三范式,并且它只有一个候选码,或者它的每个候选码都是单属性,则该关系自然达到BC范式。非BCNF可以分解为BCNF。
第四范式:要求把同一表内的多对多关系删除。
常用命令
SQL语句分三类:
①DDL(Data Definition Language)语句:数据定义语言。DDL定义了不同数据字段、数据库、表等数据库对象。常用关键字有create、drop、alter等。
②DML(Data Manipulation Language)语句:数据操作语句。DML用于增删改查数据库记录,并检查数据完整性。常用关键字有insert、delete、update、select等。
③DCL(Data Control Language)语句:数据控制语言。DCL用于控制不同数据段直接的许可和访问级别。DCL定义了数据库、表、用户、字段的访问权限和安全级别。常用关键字有grant、revoke等。
DDL与DML的区别:DDL是对数据库内部的对象进行增删改等操作。DML只是操作表内部的数据,不涉及表的定义、结构的修改,不涉及其他对象。
数据的完整性是:为了防止数据库中存在不符合语义的数据,就是防止数据库中存在不正确的数据。数据的安全性是:保护数据库,防止恶意破坏和非法存取。
show engines;
show variables like 'default_storage_engine';查看默认存储引擎
set default_storage_engine=XXX;
1、创建表
create table 表名1
(
字段名1 类型,
字段名2 类型,
primary key(字段名1,字段名2)
);
定义类型的时候,要加上长度。
主键,也叫主码。主键约束要求主键列的数据唯一,且不能为空。主键能够唯一标识表中的一条记录,可以结合外键来定义表之间的关系,加快查询速度。
外键,参照完整性,保证数据的完整性。一个表的外键要么是空值,要么等于另一个表中主键的某个值。主表(父表):关联字段中主键所在的表。从表(子表):关联字段中外键所在的表。关联字段的类型必须一致。
create table 表名2
(
字段名1 类型,
字段名2 类型,
constraint 外键约束名1 foreign key(表名2的字段名1) references 主键表(主键列名1)
);
2、非空约束,列值非空。
字段名 类型 not null
3、唯一性约束,要求该列值唯一,允许空,但只能出现一个空值。
字段名 类型 unique
unique和primary key 的区别是一个表中可以有多个字段声明为unique,但只能有一个primary key 。primary key列不能有空值,unique可以有空值。
4、默认约束,指定列的默认值。
字段名 类型 dafault 默认值
5、属性值自动增加
auto_increment的初始值为1,用来约束整数类型。
字段名 类型 auto_increment
6、查看表结构
查看表基本结构
desc 表名;
查看表详细结构
show create table 表名;
7、修改表
alter table 旧表名 rename 新表名;
alter table 表名 modify 字段名 新的数据类型;
alter table 表名 change 旧字段名 新字段名 新数据类型;
alter table 表名 add 新字段名 数据类型 [约束条件] [first|after 已存在的字段名];
alter table 表名 drop 字段名;
alter table 表名 engine=引擎名;
alter table 表名 drop foreign key 外键约束名;
8、插入
insert into 表名(字段名1,字段名2...) values(字段值1,字段值2,...);
insert into 表名 values(字段值1,字段值2,...);
insert into 表名(字段名1,字段名2...) select语句; 两个表的结构要一致,包括主键。
insert into 表名(字段名1,字段名2...)
values(字段值1,字段值2,...),
(字段值1,字段值2,...),
...
(字段值1,字段值2,...);
9、更新数据
update 表名 set 字段名1=值1,字段名2=值2 where 子句;
10、删除数据
delete from 表名 where 子句;
11、设置数据显示的格式。
select concat(name, '学生的总分是:', Chinese+English+Math) from score;
12、between minvalue and maxvalue 。判断字段的数值是否在指定范围内。只针对数字类型。
13、like的模糊查询
select name from score where name like '_A%';
_:只能匹配单个字符。%:可以匹配任意长度的字符串,比如0个字符、1个字符、很多个字符。
like '%%':代表查询所有记录。
14、is null is not null
15、order by 字段名 [ASC|DESC]。asc代表升序,desc代表降序。默认是asc。
16、正则表达式
select * from teacher where name regexp '^R';
17、连接
内连接:查询左右表同时满足条件的记录,两边都不能为null。
左外连接:以左表为主表,整合两个表的记录,提取满足条件的记录。如果某些记录在左表中有,而右表中没有,则该记录右表部分填null。
右外连接:以右表为主表,整合两个表的记录,提取满足条件的记录。如果某些记录在右表中有,而左表中没有,则该记录左表部分填null。
select * from A inner join B on A.id=B.id;
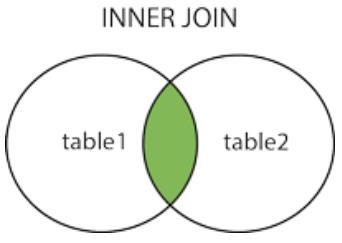
select * from A left join B on A.id=B.id;
MySQL LEFT JOIN 会读取左边数据表的全部数据,即便右边表无对应数据。
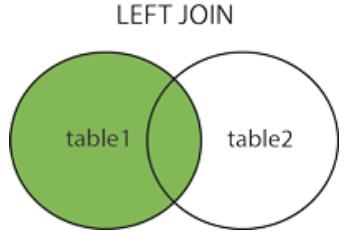
select * from A right join B on A.id=B.id;
MySQL RIGHT JOIN 会读取右边数据表的全部数据,即便左边边表无对应数据。
18、union
MySQL UNION 操作符用于连接两个 SELECT 语句,将其结果组合到一个结果集合中。
select country from websites union select country from apps order by country;
默认情况下 UNION 操作符已经删除了重复数据。
UNION ALL 会显示重复数据。
select country from websites union all select country from apps order by country;
SELECT country, name FROM Websites
WHERE country='CN'
UNION ALL
SELECT country, app_name FROM apps
WHERE country='CN'
ORDER BY country;
19、子查询
select * from employee where deptno not in (select deptno from dept);
子查询就是指在一个select语句中嵌套另一个select语句。
20、ANY关键字
假设any内部的查询语句返回的结果个数是三个,如:result1,result2,result3,那么,
select ...from ... where a > any(...);
->
select ...from ... where a > result1 or a > result2 or a > result3;
示例:
select st.stuid, st.name, sc.Chinese+sc.English+sc.Math total
from student st, score sc where st.stuid=sc.stuid
and st.stuid in (select stuid from score
where Chinese+English+Math>=any
(select score from scholarship));
any,all关键字必须与一个比较操作符一起使用。
21、ALL关键字
ALL关键字与any关键字类似,只不过上面的or改成and。即:
select ...from ... where a > all(...);
->
select ...from ... where a > result1 and a > result2 and a > result3;
数据类型
TINYINT:1字节,0~255,-128~127
SMALLINT:2字节,0~65535,-32768~32767
INT:4字节,0~4294967295,-2147483648~2147483647
BIGINT:8字节,0~18446744073709551615,-9223372036854775808~9223372036854775807
FLOAT:4字节
DOUBLE:8字节
YEAR:1字节,1901~2155,0000
DATE:4字节,1000-01~9999-12-31,0000:00:00
TIME:3字节,XXXX~838:59:59,00:00:00
DATEYEAR:8字节,1000-01 00:00:00~9999-12-21 23:59:59,0000-00-00 00:00:00
TIMESTAMP:4字节,19700101080001~2038011911407,00000000000000
Date:用来表示年月日。
TIME:只用来表示时分秒。
YEAR:只表示年份。
DATETIME:表示年月日时分秒。
TIMESTAMP:表示年月日时分秒。
DATETIME和TIMESTAMP的主要区别:
①TIMESTAMP支持的时间范围较小。DATETIME的范围更大。
②TIMESTAMP的插入、查询都受当地时区的影响,更能反映出实际的日期。如果需要给不同时区的用户使用,最好用timestamp。DATETIME则只能反映出插入时当地的时区,其他时区的人查看数据必然会有误差。
char和varchar的主要区别是:
①存储方式不同:char列的长度固定为创建表时声明的长度,范围是0到255。
varchar列中的值是可变长字符串,长度可以指定0到65535之间的值。
②在操作时,char列会删除尾部的空格。varchar保留了这些空格。两个字段:char(4)、varchar(4)。插入字符串”ab ”。char(4)字段中保存的是“ab”。varchar(4)字段中保存的是“ab ”。
text和blog
二者的差别在于blog能保存二进制数据,比如照片。text只能保存字符数据,比如日记。建议把blog或text列分离到单独的表中。
二者缺陷是:删除操作会在表中留下很大的“空洞”,产生内存碎片,影响插入性能。建议定期使用optimize table功能进行碎片整理。
浮点数和定点数
浮点数用于表示含有小数部分的数值。如果插入数据的精度超过定义精度,则会四舍五入。用float、double来表示。
定点数实际上是以字符串的形式存放的,所以定点数可以更精确地保存数据。
运算符
=和<=>比较运算符可以判断数值、字符串(依据字符的ACSII码)、表达式是否相等,如果相等,就返回1,否则返回0。=不能操作NULL,<=>可以操作NULL。
NULL=NULL结果为NULL,NULL<=>NULL结果为1。
<>和!=都不能操作NULL。
| 正则表达式的模式字符 | 含义 | 例子 | 匹配值示例 |
| ^ | 匹配字符串的开始字符 | '^b' | bread |
| $ | 匹配字符串的结束字符 | 'st$' | first,just |
| . | 匹配任意一个字符 | 'b.t' | but、bit |
| 字符串 | 匹配含有指定字符串的文本 | 'fa' | fat、fan、aaaafag |
| [字符集合] | 匹配字符集合中的任意一个字符 | '[xz]' | zero、x-ray、zebra |
| [^字符集合] | 匹配字符集合外的任意一个字符 | '[^abc]' | night、good、run、fish |
| str1|str2|str3 | 匹配str1、str2、str3中的任意一个字符串 | ||
| * | 匹配前面的字符出现0次或多次。zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 | 'f*n' | fn、fan、faen、fffffn |
| + | 匹配前面的字符出现1次或多次,+ 等价于 {1,} | ‘ba+’ | ba、bat |
| 字符串{N} | 匹配前面的字符串至少出现N次 | 'b{2}' | bbb、bbbbbb |
| 字符串{M,N} | 匹配前面的字符串至少出现M次,最多出现N次 | 'a{2,5}' | aa、aaa |
| [a-z]表示从a~z的所有字母;[0-9]表示从0~9的所有数字;[a~z0~9]表示包含所有小写的字母和数字。[3-5]、[0-9u-z] |
AND
OR
NOT 非
XOR 异或
索引
概述
所有列类型都可以用索引。对相关列用索引可以提高select操作性能。MyISAM和InnoDB的表默认用btree索引。
索引的优点:①提高数据的检索速度;缺点是:①创建和维护索引需要额外的开销。索引本身占用物理空间,增删改时需要动态维护索引。索引会影响插入记录的速度。
插入大量记录时,我们可以先删除索引,然后插入,插完后,再建索引。
创建索引有三种方式:①创建表的时候创建索引;②在已经存在的表上创建索引;③使用alter table创建索引。
分类
(1)普通索引
普通索引是指在创建索引时不附加如何限制条件(唯一、非空等限制)。可以创建在任何数据类型的字段上。
create table 表名(
字段名1 类型1,
字段名2 类型2,
index 索引名(所需要关联的这个表中的字段名)
);
create index 索引名 on 表名(这个表中的字段名);
alter table 表名 add index 索引名(索引所关联的这个表的字段名);
(2)唯一性索引
唯一索引就是在创建索引时,限定索引的值是唯一的。通过唯一索引,可以更快地查询某条记录。主键是一种特殊的唯一性索引。
zcreate table 表名(
字段名1 类型1,
字段名2 类型2,
unique index 索引名(所需要关联的这个表中的字段名)
);
create unique index 索引名 on 表名(这个表中的字段名);
alter table 表名 add unique index 索引名(索引所关联的这个表的字段名);
(3)全文索引
全文索引主要关联在char、varchar、text的字段上,以便更快地查询数据量比较大的字符串字段。
create table 表名(
字段名1 类型1,
字段名2 类型2,
fulltext index 索引名(所需要关联的这个表中的字段名)
);
create fulltext index 索引名 on 表名(这个表中的字段名);
alter table 表名 add fulltext index 索引名(索引所关联的这个表的字段名);
(4)单列索引
这种索引只对应一个字段。
(5)多列索引
多列索引是指在创建索引时所关联的是多个字段。只有在查询条件(where子句)中使用了所关联的字段中的第一个字段,多列索引才会被使用。
create table 表名(
字段名1 类型1,
字段名2 类型2,
index 索引名(字段名1, 字段名2)
);
create index 索引名 on 表名(字段名1, 字段名2);
alter table 表名 add index 索引名(字段名1, 字段名2);
(6)空间索引
(7)隐藏索引
隐藏索引就是不可见索引,不会被优化器使用。隐藏索引可以用来测试索引的性能。
create table 表名(
字段名1 类型1,
字段名2 类型2,
index 索引名(字段名1, 字段名2) invisible
);
create index 索引名 on 表名(字段名1, 字段名2) invisible;
alter table 表名 add index 索引名(字段名1, 字段名2) invisible;
(8)降序索引
降序索引以降序存储键值。如果一个查询需要对多个列进行排序,且每个列的顺序要求不一致,那就可以使用降序索引来提高性能。
create table 表名(
字段名1 类型1,
字段名2 类型2,
index 索引名(字段名1 asc, 字段名2 desc)
);
create index 索引名 on 表名(字段名1 asc, 字段名2 desc);
alter table 表名 add index 索引名(字段名1 asc, 字段名2 desc);
设计原则
--------------------
1、要在条件列上创建索引,即出现在where子句中的列、连接子句中指定的列。
2、尽量使用高选择度索引。索引列的数据不同值的基数越大,索引效果越好。
3、使用短索引。如果对字符串列进行索引,应该指定一个前缀长度。这样能大量减少索引空间,查询更快。
4、利用最左前缀。多列索引起到几个索引的作用。可利用索引中最左边的列集来匹配行。这样的列集叫最左前缀。
5、对于InnoDB表,尽量手工指定主键。主键尽量选择短的数据类型。
--------------------
1、使用唯一性索引。
2、为经常需要排序、分组和联合操作的字段建立索引。
3、为经常作为查询条件的字段建立索引。
4、限制索引的数目。索引越多,占用的磁盘空间越多。修改表时,会增加维护索引的开销。
5、尽量使用数据量少的索引。如果索引所关联字段的值很长,会影响查询速度。例如,char(100)关联的索引肯定比char(10)的索引要慢。
6、尽量使用前缀来索引。如果索引所关联字段的值很长,尽量使用值的前缀来索引。例如,TEXT、blog字段,如果能只检索字段前面的若干个字符,肯定会比全文检索要快。
7、删除不再使用或很少使用的索引。当表中的数据大量更新时,定期检查索引,看看有没有无用的索引。利用隐藏索引测试一下。
索引设计误区
1、不是所有表都需要创建索引。小表不需要创建索引。大表的查询、更新、删除操作则尽可能通过索引。
2、不要过度使用索引。每个额外的索引都需要占用磁盘空间,并降低写操作性能。修改表的内容时,必须更新索引。索引越多,所花时间越长,有可能会使mysql选择不到最好索引。
3、谨慎创建低选择度索引。因为过滤集太大,效果不好。
索引设计一般步骤
(1)整理表上的SQL,重点是看select、delete、update的where子句、关联查询的关联条件等。
(2)整理所有查询SQL的预期执行频率。
(3)整理所有涉及的列的选择度,列的不同值占总非空行数的比例越大,选择度越好。
(4)给表找合适的主键。如果没有特别合适的,就用自增列为主键。
(5)优先给执行频率最高的SQL创建索引。按执行频率排序,根据需求,是否需要为每个SQL创建索引,可以复用索引。
(6)索引合并。利用复合索引来降低索引的总数,利用最左前缀原则,尽可能复用索引。
(7)上线后,通过慢查询分析、执行计划分析、索引使用统计,来确定索引实际使用情况,再做调整。
视图
概述
视图是一种虚拟存在的表,对用户来说,基本是透明的。视图不实际存在于数据库中。它的数据来自表,并且是在使用视图时动态生成。视图的建立和删除不影响基本表。对视图的更新(增删改)会直接影响基本表,都转化为对基本表的更新。视图的列可以来自不同的表。当视图来自多个基本表时,不允许添加和删除数据。
create [or replace] [algotithm=[undefined|merge|template]]
view viewname [columnlist]
as select statement
[with [cascaded|local] check option]
replace是替换已经创建的视图,algorithm是视图选择的算法。undefined是MySQL自动选择算法。merge可以看看这个URL。temptable 表示将视图的结果存入临时表,然后用临时表来执行语句。
cascade为默认值,表示更新视图时需要满足所有相关视图和表的条件。local表示更新视图时满足该视图本身定义的条件即可。
create view XXX
as
select…
修改视图的SQL语句
create view tt as select ip,interfaceName from interfaces;创建视图
create or replace view tt as select id,ip,interfaceName from interfaces;修改视图
修改视图
alter [or replace] [algotithm=[undefined|merge|template]]
view viewname [columnlist]
as select statement
[with [cascaded|local] check option]
以下几种情况是不能更新视图的:
①定义视图时,含有sum()、count()、max()、min()等函数。
②定义视图时,含有union、union all、distinct、group by、having等关键字。
③常量视图。
④定义视图时,含有子查询。
⑤基于不可更新的视图创建的视图。
create view view_3 as select * from view_2;
⑥定义视图时,algorithm为temptable类型的视图
⑦视图对应的表存在没有默认值的列,且该列没有包含在视图里。
删除视图
drop view viewname1[,viewname2];
优点
视图相对于普通表的优点有三个:
①简单:视图对于用户来说已经是过滤好的复合条件的结果集。
②安全:使用视图的用户只能访问他们被允许查询的结果集,权限管理可以限制到某行某列。
③数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响。
存储过程和函数
存储过程,这个本人目前还没用过,请需要的同学自行百度。
create procedure procedure_name([proc_param[,...]])
[characteristic...] routine_body
存储函数,这个本人目前还没用过,请需要的同学自行百度。
create function fun_name ([func_param[,...]])
[characteristic...] routine_body
存储过程和函数是事先经过编译并存储在数据库中的一段SQL语句的集合。
用他们的好处是:简化开发工作,减少数据在数据库和应用服务器之间的传输。提高数据处理的效率。
二者的区别:
①函数必须有返回值,而存储过程没有。
②函数的参数只能是IN类型。存储过程的参数可以使用IN、OUT、INOUT类型。
调用存储过程和直接执行SQL效果相同,但存储过程的好处在于处理逻辑都封装在数据库端。一旦处理逻辑发生变化,只需要修改存储过程,对调用程序没有影响。
触发器
触发器是与表相关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。它的作用是:协助应用在数据库端确保数据的完整性。触发器是行触发的,每次增删改记录都会触发。过多或过复杂的触发器会对性能造成影响。触发器是一个特殊的存储过程。不同的是,执行存储过程需要用call来调用,而触发器是由事件触发的,被MySQL自动调用。
触发器是由事件来触发某个操作,这些事件包括insert、update、delete。
使用触发器的实际场景:
①新员工入职,添加一条员工记录,员工的总数必须同时改变。
②学生毕业后,学校删除该学生的记录,同时希望能删除该同学的借书记录。
共同点:表发生更改时自动作一些处理操作。触发器可以加强数据库表中数据的完整性约束和业务规则。
创建有一条执行语句的触发器
create trigger trigger_name before|after trigger_event
on table_name for each row trigger_STMT;
before|after:前者是在触发器事件之前执行触发器语句;后者是触发器事件之后执行触发语句。
trigger_event :触发事件,触发器执行的条件。
for each row:表示任何一条记录上的操作满足触发事件都会执行触发器。
trigger_STMT:激活触发器后被执行的语句。
create trigger loggertime
before insert on dept for each row
insert into logger values(null, 'dept', now());
创建有多条执行语句的触发器
create trigger trigger_name
before|after trigger_event
on table_name for each row
begin
trigger_STMT
end
delimiter $$
create trigger tri_loggertime2
after insert
on dept for each row
begin
insert into logger values(null, 'dept', now());
insert into logger values(null, 'dept', now());
end;
$$
delimiter ;
查看触发器
show triggers;
desc triggers;
select * from triggers where trigger_name='触发器的名字';
删除触发器
drop trigger trigger_name;
事务
概述
事务是由一组SQL语句组成的逻辑处理单元。
事务的ACID属性:
①原子性(Atomicity):事务是一个原子操作单元,对数据的修改,要么全都成功执行,要么全都不执行。
②一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。就是说所有相关的数据规则都必须应用于事务的修改,保持数据的完整性。
③隔离性(Isolation):数据库系统提供隔离机制,保证事务的执行不受外部并发操作的影响。就是说事务处理过程中的中间状态对外部是不可见的。
④持久性(Durable):事务完成之后,对数据的修改是永久性的。
事务控制
MySQL通过set autocommit、start transaction、commit、rollback等语句支持本地事务。
begin开始事务。commit结束事务。rollback回滚事务。
事务的具体SQL样例,请同学自行百度吧!
查看MySQL默认隔离级别
mysql> show variables like 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
并发事务处理带来的问题
并发事务处理能加大数据库资源的利用率。提高事务吞吐量。但有些问题:
(1)更新丢失:当两个或多个事务选择同一行,基于最初选定的值更改该行时,由于每个事务不知道其他事务的存在,最后的更新覆盖了由其他事务所做的更新。
(2)脏读:一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态。这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务就读了“脏”数据。
(3)不可重复读:一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现它读出的数据已经发生了改变。
(4)幻读:一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据。
事务的隔离级别
更新丢失应该完全避免。防止更新丢失应该是应用的责任。脏读、不可重复读、幻读,都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。
数据库实现事务隔离的方式有2种:①在读数据前,对其加锁,阻止其他事务对数据进行修改。②利用数据多版本并发控制技术,也叫多版本数据库。不用加如何锁,通过一定机制生成一个数据请求时间点的一致性数据快照,并用这个快照来提供(语句级或事务级的)一致性读取。从用户角度看,数据库可以提供同一数据的多个版本。
事务隔离越严格,并发副作用越小,但代价也越大。因为事务隔离实质上就是让事务在一定程度上“串行化”进行。这显然与并发矛盾。
为了解决“隔离”和“并发”的矛盾,有了4个级别的事务隔离。
行锁
InnoDB有2种行锁:
①共享锁(S):允许一个事务读一行,阻止其他事务获得相同数据集的排他锁。
②排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务获得相同数据集的共享读锁和排他写锁。
表锁
什么时候使用表锁?对于InnoDB表,大部分情况下都应该使用行锁,因为我们选择InnoDB表的理由往往是事务和行锁。特殊情况,考虑表锁:
①事务需要更新大部分或全部数据,表又比较大,就用表锁来提高事务的执行速度。
②事务涉及多个表,比较复杂,很可能会引起死锁,造成大量事务回滚。这时,就考虑表锁,减少数据库因回滚带来的开销。
在InnoDB下,使用表锁,需要注意:
①要将autocommit设为0,否则MySQL不会给表加锁;事务结束前,不要用unlock tables释放表锁,因为unlock tables会隐含地提交事务。要用unlock tables才能释放lock tables加的表锁。
②lock tables加的表锁是由MySQL Server负责的。
MySQL用户管理
权限表放在数据库mysql中表名为:user、db、tables_priv、procs_priv。
cmd中登录MySQL的命令
mysql -h hostname|hostIP -P port -u username -p password DatabaseName
示例:mysql -hlocalhost -P3306 -uroot -p123456 test
退出:quit
root修改密码可以看看这篇
①mysqladmin -uroot -p123456 password 121212
②
用root用户登录后,
Type 'help;' or '\\h' for help. Type '\\c' to clear the current input statement.
mysql> alter user user() identified by '111';
Query OK, 0 rows affected (0.03 sec)
日志管理
MySQL的日志主要分为6类:
- 二进制日志(变更日志):记录所有更改数据的语句,可用于用户数据复制。记录数据库的变化。
- 错误日志:记录MySQL服务启动、运行、关闭时出现的错误。
- 通用查询日志:记录用户所有的操作,包括启动和关闭MySQL服务、更新语句、查询语句等。
- 慢查询日志:记录执行时间超过long_query_time的所有查询语句。通过它,找出哪些查询语句执行的时间较长、执行效率低,进行优化。
- 中继日志
- 数据定义语句日志
以上是关于MySQL笔记基础篇的主要内容,如果未能解决你的问题,请参考以下文章