MySQL笔记SQL经典实例(上)
Posted 可持续化发展
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL笔记SQL经典实例(上)相关的知识,希望对你有一定的参考价值。
小明写这篇文章的目的是为了记录阅读《SQL经典实例》(安东尼-莫利纳罗著,刘春辉译)中的收获。这本书里面有mysql、Oracle、Postgresql的语法实例。但本人目前用的是MySQL,所以,只摘录了MySQL的相关内容。样例SQL都在Navicat+MySQL8中测试过。我的文章只会收录我觉得有用的东西。对于一些特别基础的知识点和百度能解决的工具类知识点,我会略过或简单提一下。由于篇幅太长了,分为上下两部。
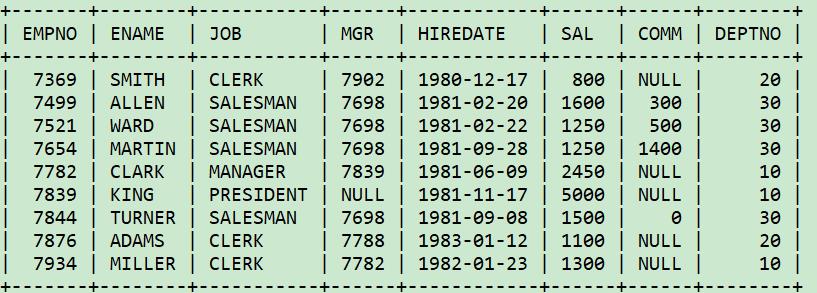
表的结构和数据
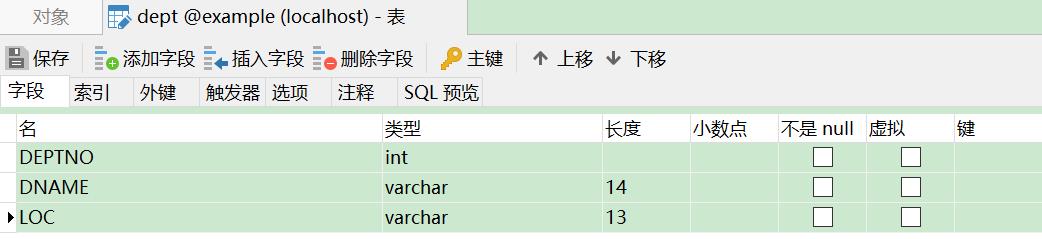
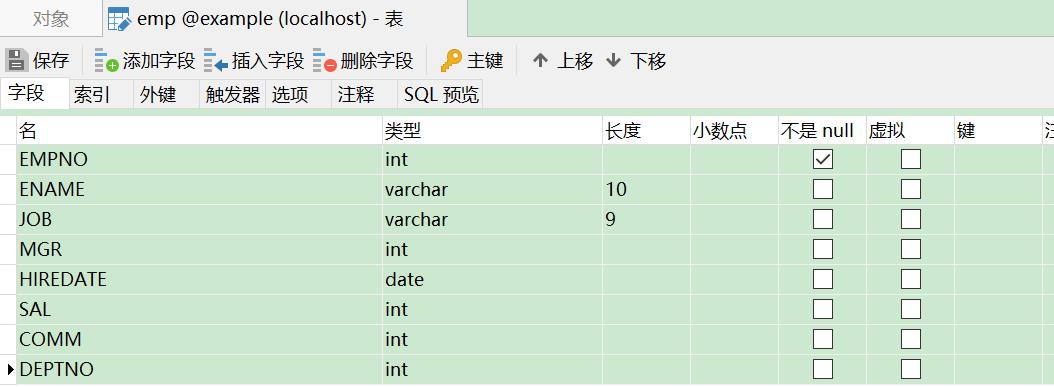



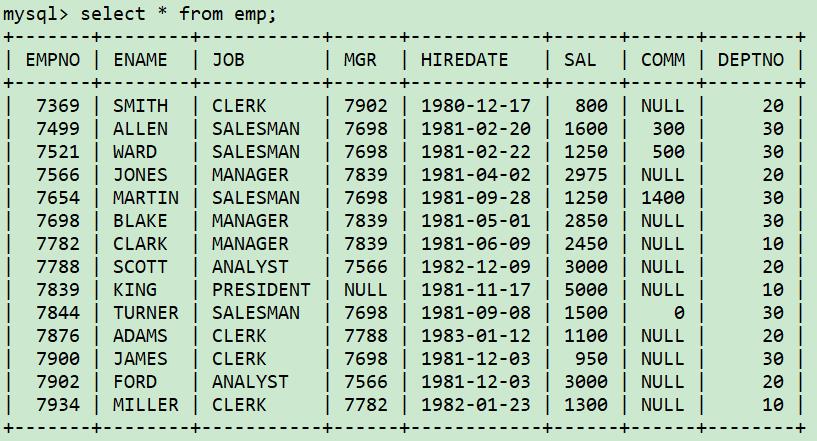
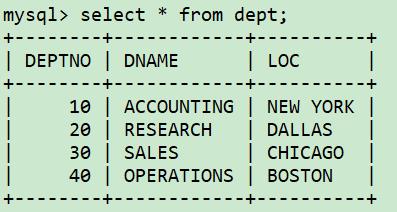


检索记录
1、实际开发中,不推荐select *,为了可读性,请指明select的每一列。(我这里是为了方便才写select * 的)
2、
select * from emp
-> where deptno=10 or comm is not null or sal <= 2000 and deptno=20;
- deptno等于10,或
- comm不空,或
- deptno等于20,并且,工资不高于2000的员工
select * from emp
-> where (deptno=10 or comm is not null or sal <= 2000) and deptno=20;
- deptno=10,或,comm不空,或,工资小于等于2000
- 并且,deptno=20

3、select指定特定的列名,可以过滤无关的数据。避免将时间浪费在检索不需要的数据上。
4、创建有意义的列名,别名
select sal as salary, comm as commission
from emp;
5、在where子句中引用别名列
例如,
select sal as salary, comm as commission from emp where salary < 5000;【1】
这样会报错。
select * from
(select sal as salary, comm as commission from emp) x
where salary < 5000;【2】
OK了!将查询包装为一个内嵌视图。where子句会比select子句先执行。所以【1】报错。因为from子句比where子句先执行,所以【2】OK。当表里的某些列命名不规范的时候,可以用这个技巧。
6、串联多列的值
将多列值合并为一列。
select concat(ename, ' works as a ', job) as msg
from emp
where deptno=10;
7、在select语句中使用条件逻辑
在select语句中针对查询结果值执行if-else操作。
select ename, sal,
case when sal <= 2000 then 'underpaid'
when sal >= 4000 then 'overpaid'
else 'OK'
end as status
from emp;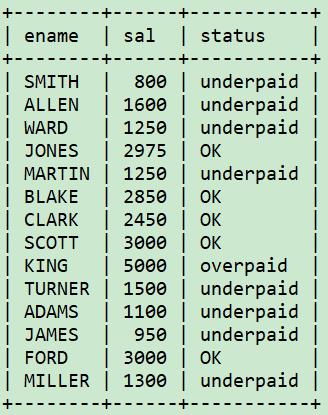
8、限定返回行数
限定查询结果的行数,不关心排序
select * from emp limit 5;9、随机返回若干行记录
select ename, job from emp
order by rand() limit 5;10、将null值转换为实际值
有一些行里面有null,但想在返回结果中将其替换为非null值。
select empno,coalesce(comm, 0) from emp limit 5;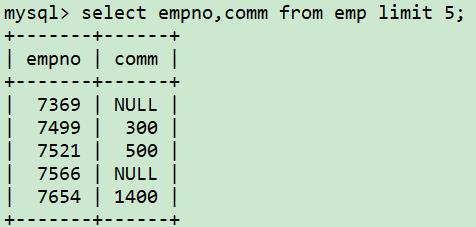

11、查找匹配项
select ename, job from emp
where deptno in (10,20);
select ename, job from emp
where deptno in (10,20) and
(ename like '%I%' or job like '%ER');查询结果排序
1、以指定顺序返回查询结果
可以不指定用于排序的列名,而用一个数值来代替该列。数值从1开始,从左到右匹配select列表里的列。
select ename, job, sal
from emp where deptno=10
order by sal desc;
等价于
select ename,job,sal
from emp where deptno=10
order by 3 desc;
2、多字段排序
select empno, deptno, sal, ename, job
from emp
order by deptno asc, sal desc;3、依据子串排序
想按照一个字符串的特定部分排序查询结果。例如,从emp表中检索员工的名字和职位,并按照职位字段的最后3个字符对查询结果进行排序。
利用数据库中的子串函数,substr截取从指定起始位置开始到字符串结束的所有字符。
select ename, job
from emp
order by substr(job, length(job)-2);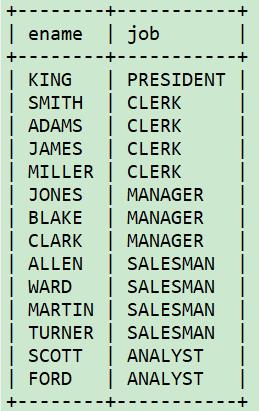
4、排序时对null值的处理
emp表的comm列进行排序,但comm可能为null。想把null的行放在后面。
/*非null的comm升序,null的comm放在最后面*/
select ename, sal, comm
from
(select ename, sal, comm,
case when comm is null then 0 else 1 end as is_null
from emp) x
order by is_null desc, comm asc;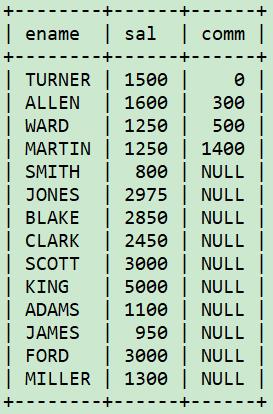
5、依据条件逻辑动态调整排序项
希望按照某个条件逻辑来排序,例如,如果job=salesman,就按照comm来排序,否则,就按照sal排序。
select ename, sal, job, comm
from emp
order by case when job = 'SALESMAN' then comm else sal end;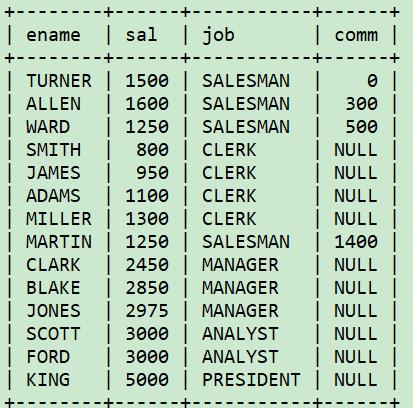
select ename, sal, job, comm,
case when job='SALESMAN' then comm else sal end as ordered
from emp order by 5;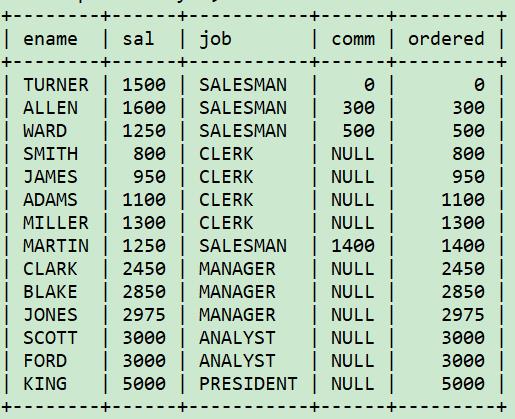
select ename, sal, job, comm from emp;
多表查询
1、叠加两个行集
想返回多个表的数据,这些表可以没有相同的键,但它们的列的数据类型必须相同。union all,将多个表的行并入一个结果集中。但此时select列表中的列必须保持数目相同且类型相同。union all会纳入重复项,如果希望过滤重复项,可以用union。大体而言,union等同于针对union all的输出结果再执行一次distinct。除非有必要,否则不要在查询中使用distinct,除非有必要,否则不要用union替代union all。如下:
select distinct deptno
from(
select deptno from emp
union all
select deptno from dept
);
select ename as ename_and_dname, deptno
from emp
where deptno=10
union all
select '--------',null
from t1
union all
select dname, deptno
from dept;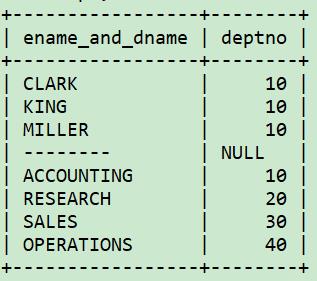
2、合并相关行
想根据一个共同的列或具有相同值的列做连接查询,并返回多个表中的行。可以用内连接中的相等连接。连接查询是一种把来自两个表的行合并起来的操作。相等连接,其连接条件依赖于某个相等条件(例如,一个表的部门编号和另一个表的部门编号相等)。
select e.ename, d.loc
from emp e, dept d
where e.deptno = d.deptno and e.deptno=10;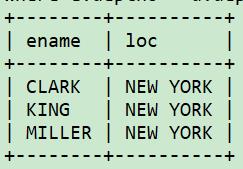
理论上,连接操作首先会依据from子句里列出的表生成笛卡尔积(列出所有可能的行组合),如下:
select e.ename, d.loc, e.deptno as emp_deptno, d.deptno as dept_deptno
from emp e, dept d
where e.deptno=10;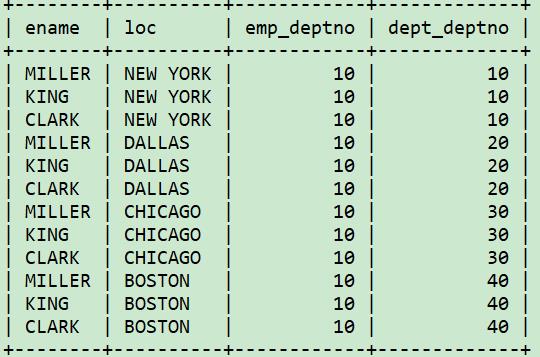
然后再通过where子句里e.deptno和d.deptno做连接操作,限定了只有emp,.deptno和dept.deptno相等的行才会返回。
select e.ename, d.loc, e.deptno as emp_deptno, d.deptno as dept_deptno
from emp e, dept d
where e.deptno=d.deptno and e.deptno=10;
另一种写法是inner join。inner join = join。inner是可选项关键字。
select e.ename, d.loc
from emp e inner join dept d
on e.deptno=d.deptno
where e.deptno=10;3、查询只存在于一个表中的数据
想从一个表(源表)中找出那些在某个目标表里不存在的值。例如,想找出在dept表中存在但在emp表中不存在的部门编号。
select deptno
from dept
where deptno not in (select deptno from emp);
使用这种方式时,需要考虑排除结果集的重复项。这里的示例中deptno是dept表的主键,所以可以不加distinct。如果deptno不是dept表的主键,可以使用distinct。
select distinct deptno
from dept
where deptno not in (select deptno from emp);
使用not in 时要注意null值问题。例如,
create table new_dept(deptno integer);
insert into new_dept values (10);
insert into new_dept values (50);
insert into new_dept values (null);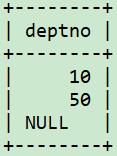 如果试着用not in子查询来检索存在于dept表但不存在于new_dept表中的deptno,会发现查不到如何值。
如果试着用not in子查询来检索存在于dept表但不存在于new_dept表中的deptno,会发现查不到如何值。
select * from dept
where deptno not in (select deptno from new_dept);
原因在于:new_dept表里有null值。in和 not in本质上是 or 运算,由于null值参与or逻辑运算的方式不同,in 和 not in 将会产生不同的结果。
select deptno
from dept
where deptno in (10,50, null);

select deptno
from dept
where deptno=10 or deptno=50 or deptno=null;

select deptno
from dept
where deptno not in (10,50,null);
select deptno
from dept
where not (deptno=10 or deptno=50 or deptno=null);![]()
deptno not in (10,50,null)等价于 not (deptno=10 or deptno=50 or deptno=null)
当deptno是50的情况时,
not (deptno=10 or deptno=50 or deptno=null)
== (false or false or null)
== (false or null)
==null
在SQL中,TRUE or null的运算结果为TRUE,但FALSE or null 的运算结果是null!必须谨记,当使用 in 以及 执行 or 的时候,考虑 null 值问题。
为了避免 not in 和null值带来的问题,需要结合使用 not exists 和关联子查询。关联子查询是指外层查询执行后的结果集会被内层子查询引用。下面是一个免受 null 值影响的替代方案。
select d.deptno
from dept d
where not exists
(select null from emp e where d.deptno=e.deptno);
SQL过程:
上述查询会遍历并评估dept表的每一行。针对每一行,会有如下操作:
(1)执行子查询并检查当前的部门编号是否存在于emp表。注意关联条件 d.deptno = e.deptno ,它通过部门编号把两个表连接起来。
(2)如果子查询有结果返回给外层查询,那么 exists (...) 的评估结果是TRUE,这样 not exists (...) 就是false,如此外层查询就会舍弃当前行。
(3)如果子查询没有返回如何结果,那么not exists(...)的评估结果就是TRUE,由此外层查询就会返回当前行(因为它是一个不存在于emp表中的部门编号)。
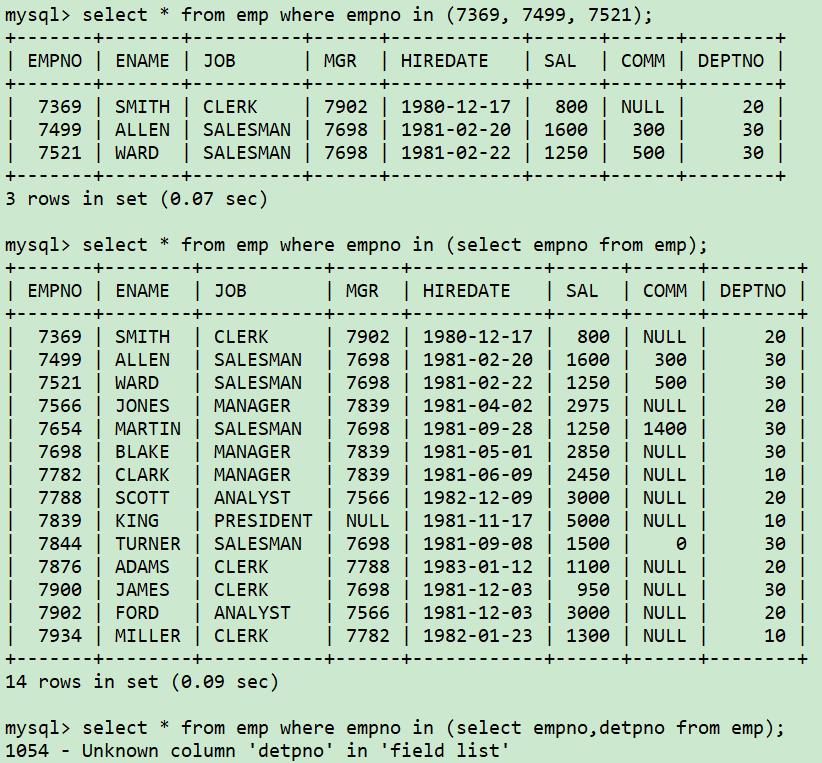
exists子句不在乎返回的是什么,而是在乎有没有结果集返回, 比如:
select name from student where sex = 'm' and mark exists(select 1 from grade where ...) ,只要
exists引导的子句有结果集返回,那么exists这个条件就算成立了,大家注意返回的字段始终为1,如果改成“select 2 from grade where ...”,那么返回的字段就是2,这个数字没有意义。
not exists 和not in 分别是exists 和 in 的 对立面。
如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in;参考链接
exists (sql 返回结果集为真)
not exists (sql 不返回结果集为真)
in 或 not in 后面的结果集只能是对应一个字段的结果集,否则报错。
关联子查询和普通子查询的区别在于参考链接【可以看看《SQL基础教程》(第2版)[日] MICK著;孙淼,罗勇译》】如何正确理解SQL关联子查询:
1,关联子查询引用了外部查询的列。2,执行顺序不同。对于普通子查询,先执行普通子查询,再执行外层查询;而对于关联子查询,先执行外层查询,然后对所有通过过滤条件的记录执行内层查询。
在关联子查询中,对于外部查询返回的每一行数据,内部查询都要执行一次。另外,在关联子查询中是信息流是双向的,外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。
关联子查询的用途:
①在细分的组内进行比较
例子:查询各个商品种类中高于该商品种类平均销售价格的商品信息
SELECT *
FROM t_commodity AS t1
WHERE sell_unit_price > (
SELECT AVG(sell_unit_price)
FROM t_commodity
WHERE category = t1.category
)②和EXISTS或NOT EXISTS配合使用,查询存在或不存在的记录
例子:查询没有下过订单的所有顾客的信息
SELECT customer_id
FROM customers AS c
WHERE NOT EXISTS (
SELECT customer_id
FROM orders
WHERE customer_id = c.customer_id
)
5、从一个表检索与另一个表不相关的行
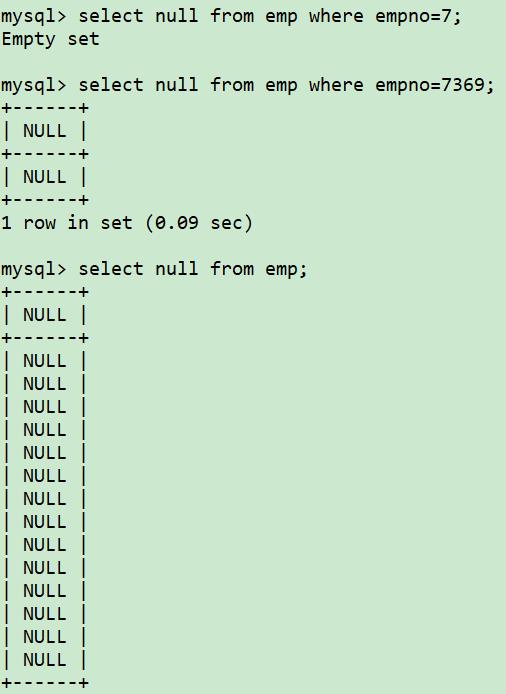
问题:两个表有相同的列,想在一个表里查找与另一个表不匹配的行。例如,想找出哪些部门没有员工。
如果想找到每一个员工的就职部门,需要基于emp表和dept表的deptno列进行inner join 。
select d.*
from dept d left join emp e
on d.deptno=e.deptno
where e.deptno is null;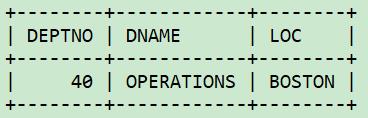
这里使用了外连接,并且只保留了不匹配的行。这种操作有时候被称为反连接。为了更好地理解反连接,我们先来看看没有过滤null的结果集。
select e.ename, e.deptno as emp_deptno, d.*
from dept d left join emp e
on d.deptno = e.deptno;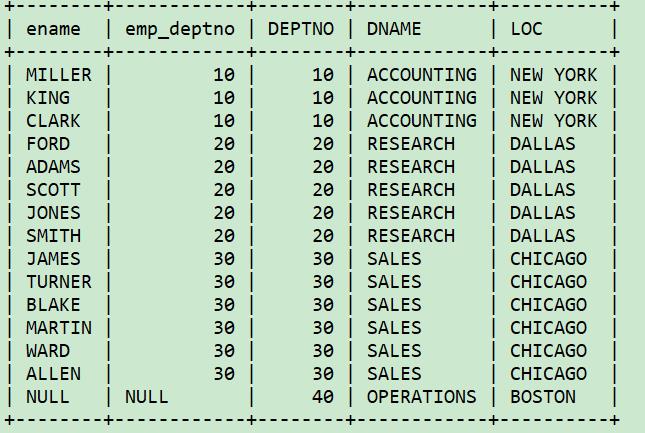
6、新增连接查询而不影响其他的连接查询

已有查询
select e.ename, d.loc
from emp e, dept d
where e.deptno=d.deptno;
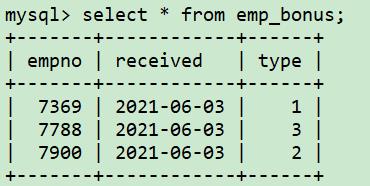
想将奖金信息合并到一起。使用外连接既能得到额外信息,又不会丢失原有的信息。外连接会返回一个表中的所有行,以及另一个表中与之匹配的行。
select e.ename, d.loc, eb.received
from emp e join dept d
on e.deptno=d.deptno
left join emp_bonus eb
on e.empno=eb.empno
order by 2;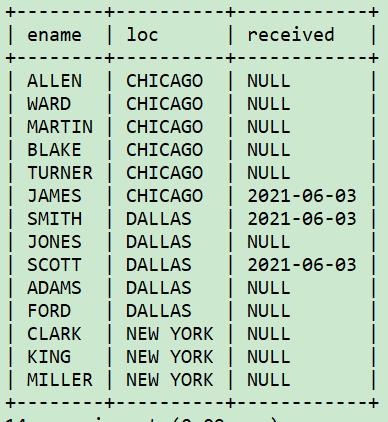
7、确定两个表是否有相同的数据
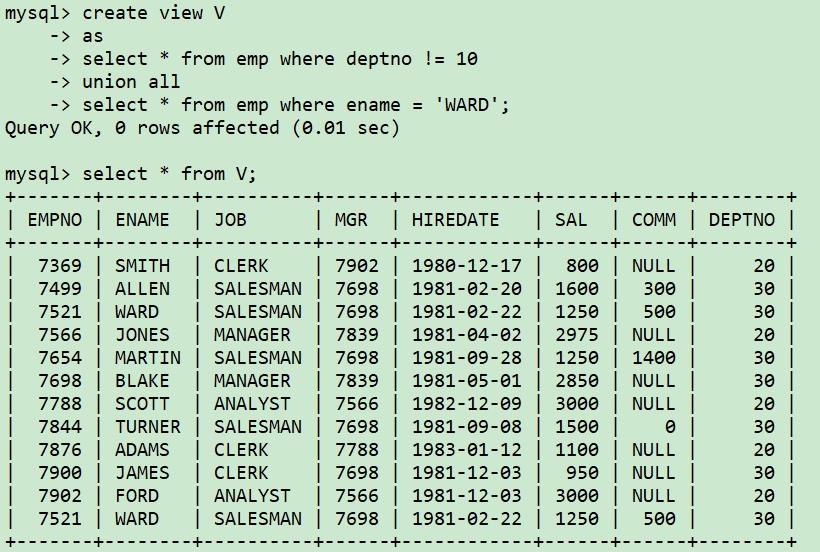
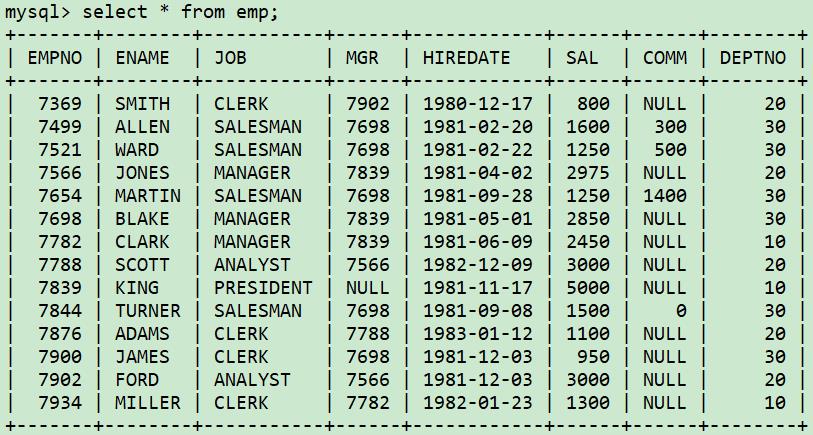
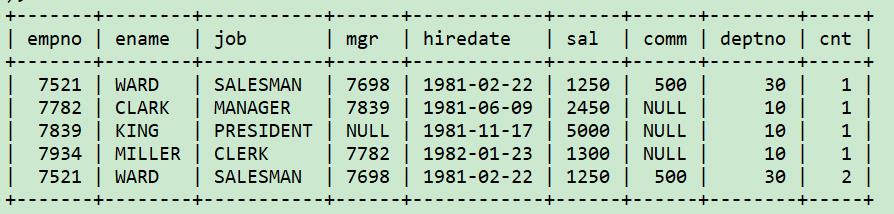
想确定V视图中是否和emp表有完全相同的数据?如果有不同的记录,请找出不同的数据,以及重复的数据。
原理:
(1)先找出存在于emp表而不存在于视图v的行
(2)然后与存在于视图v而不存在于emp表的行合并 (union all)
如果两个表完全相同,则不会返回任何数据。如果两个表有不同之处,将返回哪些不同的行。比较两个表是否完全相同,我们在比较数据之前,可以单独比较一下行数。
select count(*) from emp
union
select count(*) from dept;
select * from (
select e.empno, e.ename,e.job, e.mgr,e.hiredate,e.sal,e.comm, e.deptno,count(*) as cnt
from emp e
group by e.empno, e.ename,e.job, e.mgr,e.hiredate,e.sal,e.comm, e.deptno
) e
where not exists(
select null from
(
select v.empno, v.ename,v.job, v.mgr,v.hiredate,v.sal,v.comm, v.deptno,count(*) as cnt
from v
group by v.empno, v.ename,v.job, v.mgr,v.hiredate,v.sal,v.comm, v.deptno
)v
where v.empno = e.empno
and v.ename = e.ename
and v.job= e.job
and v.mgr= e.mgr
and v.hiredate= e.hiredate
and v.sal= e.sal
and v.deptno= e.deptno
and v.cnt= e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
)
union all
select * from (
select v.empno, v.ename,v.job, v.mgr,v.hiredate,v.sal,v.comm, v.deptno,count(*) as cnt
from v
group by empno, ename,job, mgr,hiredate,sal,comm, deptno
) v
where not exists(
select null from
(
select e.empno, e.ename,e.job, e.mgr,e.hiredate,e.sal,e.comm, e.deptno,count(*) as cnt
from emp e
group by empno, ename,job, mgr,hiredate,sal,comm, deptno
)e
where v.empno = e.empno
and v.ename = e.ename
and v.job= e.job
and v.mgr= e.mgr
and v.hiredate= e.hiredate
and v.sal= e.sal
and v.deptno= e.deptno
and v.cnt= e.cnt
and coalesce(v.comm,0)=coalesce(e.comm,0)
);
8、识别并消除笛卡尔积
想找出部门编号为10的所有员工的名字及其部门所在的城市。
错误的SQL是这样的:
select e.ename, d.loc
from emp e, dept d
where e.deptno = 10;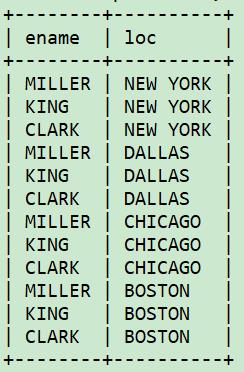
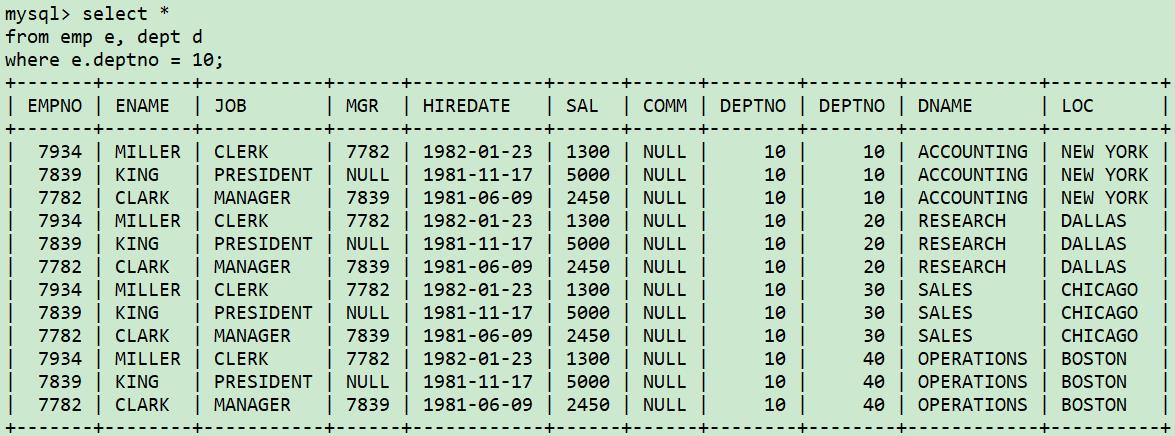
应该这么写:
select e.ename, d.loc
from emp e, dept d
where e.deptno=10 and d.deptno=e.deptno;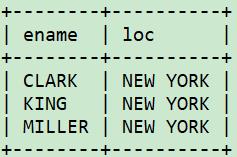
9、组合使用连接查询与聚合函数
想执行一个聚合操作,但查询语句涉及多个表。希望确保表之间的连接查询不会干扰聚合操作。例如,希望计算部门编号为10的员工的工资总额以及奖金总和。因为有部门员工多次获得奖金,所以在emp表和emp_bonus表连接之后再执行聚合函数sum,就会出错。
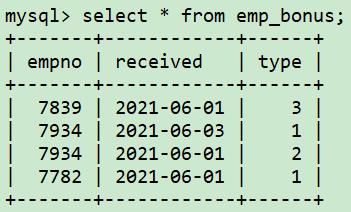
错误示例,奖金总额(total_bonus)是正确的,但工资总额(total_sal)是错误的,错误原因是连接查询导致某些行的 sal 列出现了两次:
select deptno, sum(sal) as total_sal, sum(bonus) as total_bonus
from (
select e.empno, e.ename, e.sal, e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
group by deptno;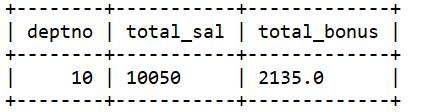
错误原因:MILLER的工资被加了两次。
select *
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10;
解决方案:
在连接查询里进行聚合运算时,必须十分小心。如果连接查询产生了重复行,通常有两种方法来使用聚合函数,避免计算结果出错。
①调用聚合函数时直接使用 distinct ,这样每个值都会先去掉重复项再参加计算。
②在进行连接查询之前,先执行聚合运算(以内嵌视图的方式),这样可以避免错误的结果。因为聚合运算发生在连接查询之前。
distinct的方式,解决办法:只计算不同的emp.sal。
select deptno, sum(distinct sal) as total_sal, sum(bonus) as total_bonus
from(
select e.empno, e.ename, e.sal, e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
group by deptno;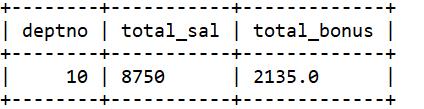
另一种解决方法:先计算部门编号为10的全部员工的工资总额,然后连接emp表和emp_bonus表。
select d.deptno, d.total_sal,
sum(e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end) as total_bonus
from emp e, emp_bonus eb,(
select deptno, sum(sal) as total_sal
from emp
where deptno = 10
group by deptno
) d
where e.deptno = d.deptno
and e.empno = eb.empno
group by d.deptno, d.total_sal;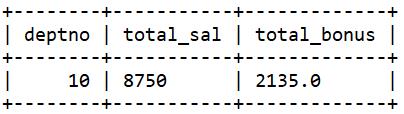
10、组合使用外连接查询和聚合函数
部门编号为10的员工中只有部分人获得了奖金。想计算部门编号为10的员工的工资总额和奖金总额。

错误示例:
select deptno, sum(sal) as total_sal, sum(bonus) as total_bonus
from(
select e.empno, e.ename, e.sal, e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
group by deptno;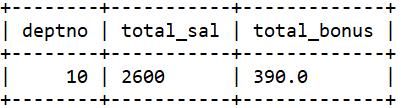
错误原因,奖金总额对了,但工资总额错误。因为没有计算部门编号为10 的所有员工的工资总额,实际上只有MILLER的工资被加入总和,而且被错误计算了两次:
select e.empno, e.ename, e.sal, e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10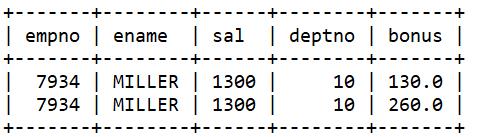
解决方法:
本示例“问题部分”第二个查询语句连接了emp和emp_bonus表,却只返回了员工MILLER的两行数据,这导致emp表的工资总额计算出错(部门编号为10的其他员工没有奖金,他们的工资没有被计入总和)。解决方法:把emp表外连接到emp_bonus表,这样哪些没有奖金的员工也会被计算进来。
①外连接emp_bonus表,然后去掉部门编号为10的员工的重复项,再计算工资总和。
select deptno, sum(distinct sal) as total_sal, sum(bonus) as total_bonus
from(
select e.empno, e.ename, e.sal, e.deptno,
e.sal*case when eb.type is null then 0
when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end as bonus
from emp e left join emp_bonus eb
on e.empno = eb.empno
where e.deptno = 10
) x
group by deptno;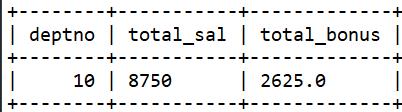
②先计算部门编号为10的员工的工资总额,然后再连接emp表和emp_bonus 表(这样就避免了使用外连接)。
select d.deptno, d.total_sal,
sum(e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end) as total_bonus
from emp e, emp_bonus eb,(
select deptno, sum(sal) as total_sal
from emp
where deptno = 10
group by deptno
) d
where e.deptno = d.deptno
and e.empno = eb.empno
group by d.deptno, d.total_sal;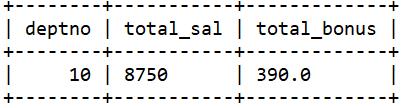
11、从多个表中返回缺失值
找到存在于dept表而不存在于emp表的数据(即没有员工的部门)需要使用外连接。
select d.deptno, d.dname, e.ename
from dept d left outer join emp e
on d.deptno = e.deptno;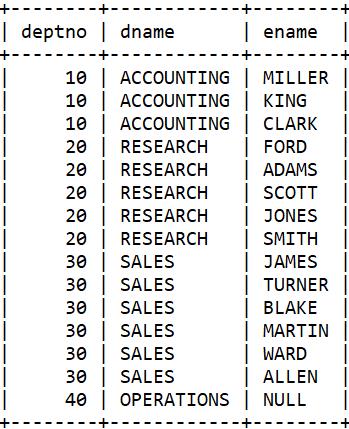
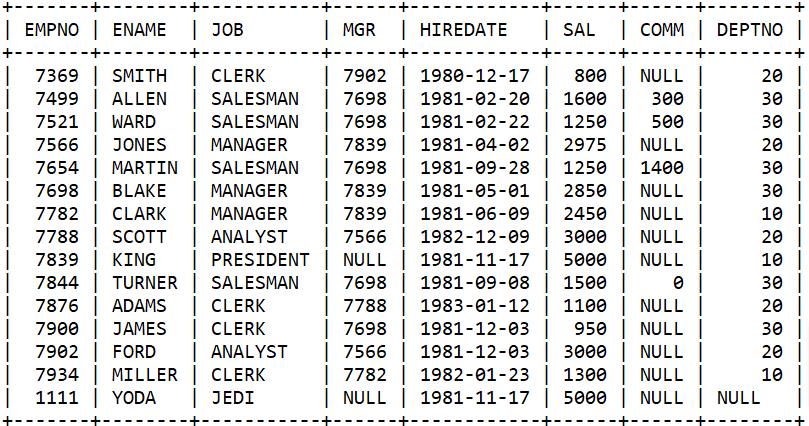
插入一个新的员工
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
select 1111, 'YODA', 'JEDI', null, hiredate, sal, comm, null
from emp
where ename = 'KING';
select d.deptno, d.dname, e.ename
from dept d right outer join emp e
on d.deptno = e.deptno;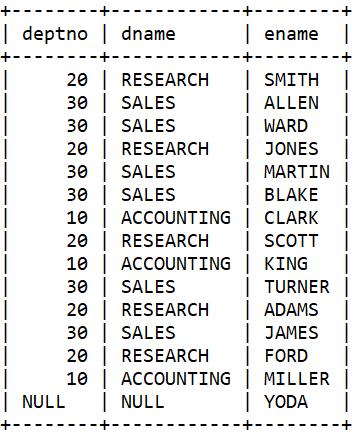
但我想要的是在同一个查询语句中,既外连接到emp表又外连接到dept表。
解决方法:使用全外连接(full outer join),基于一个共同值从两个表中返回缺失值。全外连接查询的本质是合并两个表的外连接查询的结果集。
select d.deptno, d.dname, e.ename
from dept d full outer join emp e
on d.deptno = e.deptno;
但是MySQL居然不支持全连接。
select d.deptno, d.dname, e.ename
from dept d right outer join emp e
on d.deptno = e.deptno
union
select d.deptno, d.dname, e.ename
from dept d left outer join emp e
on d.deptno = e.deptno;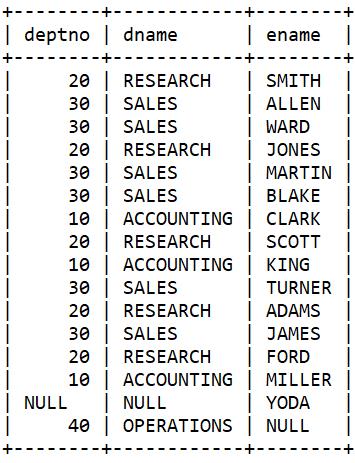
12、在运算和比较中使用null
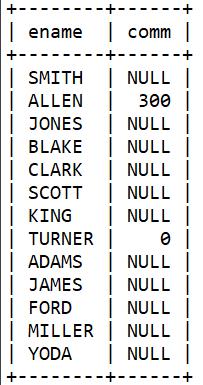
null不会等于或不等于任何值,甚至不能与自身进行比较。但想找出emp表中comm列比员工WARD低的所有员工。检索结果应该包含comm列为null的员工。
select ename, comm
from emp
where coalesce(comm, 0) < (
select comm from emp where ename = 'WARD'
);
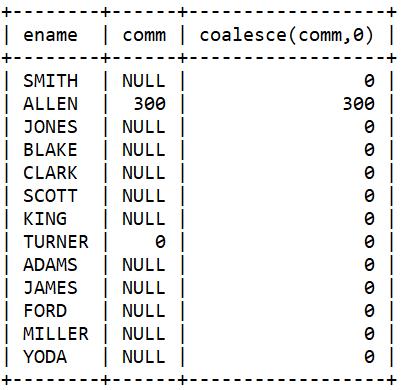
select ename, comm, coalesce(comm,0)
from emp
where coalesce(comm, 0) < (
select comm from emp where ename = 'WARD'
);
插入、更新、删除
1、插入
插入默认值
create table D (id integer default 0, foo varchar(10));
insert into D (foo) values ('Bar');
使用null覆盖默认值
create table D (id integer default 0, foo varchar(10));
insert into D (id, foo) values (null, 'Brighten');
2、复制数据到另一个表
例如,想把dept表的部分数据复制到dept_east表中,现在dept_east表已经建好了,结构和dept表相同(列名,数据类型),现在该表中没有数据。
insert into dept_east (deptno, dname, loc)
select deptno, dname, loc
from dept
where loc in ('NEW YORK', 'BOSTON');3、复制表定义
想创建一个新表,该表和当前已存在的表保持相同的结构定义。例如,为dept表创建一个副本,dept_2,但我只想复制它的表结构,而不复制数据。
create table dept_2
as
select * from dept
where 1=0;4、禁止插入特定的列
想阻止用户或软件应用程序在某些列中插入数据。例如,一个程序将数据插入emp表中,但只允许它插入empno、ename、job列。
解决方法:创建一个视图,只暴露那些你希望暴露的列。然后,强制所有insert语句都来操作这个视图。
5、更新记录
想更新一个表的部分记录或全部记录。
update emp
set sal = sal*1.10
where deptno = 20;6、当相关行存在时更新记录
想更新一个表的部分行,但更新条件取决于另一个表中是否有与之相关的行。例如,如果一个员工出现在emp_bonus表中,你希望把他的工资(在emp表中)上涨20%。
解决方法:
update emp
set sal = sal*1.20
where empno in (select empno from emp_bonus);
或者
update emp
set sal = sal*1.20
where exists (
select null from emp_bonus
where emp.empno = emp_bonus.empno
);7、使用另一个表的数据更新记录
想使用另一个表的值来更新当前的表。new_sal表存储了部分员工调整后的工资。
update emp e
set (e.sal, e.comm) = (
select ns.sal, ns.sal/2
from new_sal ns
where ns.deptno = e.deptno
)
where exists (
select null from new_sal ns
where ns.deptno = e.deptno
);8、删除全表记录
delete from emp;9、删除违反参照完整性的记录
想从表中删除一些记录,因为在另一个表里不存在与这些记录相匹配的数据。例如,一些员工所属的部门其实并不存在。我希望删除这些员工。
delete from emp
where not exists(
select * from dept
where dept.deptno = emp.deptno
);
或者
delete from emp
where deptno not in (select deptno from dept);10、删除重复记录
name列有重复值,想让name列的值不重复。
delete from dupes
where id not in (
select min(id) from dupes group by name
);11、删除被其他表参照的记录
delete from emp
where deptno in (
select deptno from dept_accidents
group by deptno
having count(*) >= 3
);
以上是关于MySQL笔记SQL经典实例(上)的主要内容,如果未能解决你的问题,请参考以下文章