HBASE中HFile结构-你真的知道Hbase怎么查数据?
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBASE中HFile结构-你真的知道Hbase怎么查数据?相关的知识,希望对你有一定的参考价值。
HBASE 中 HFile结构
序
since: 2021年4月14日 22:45
auth: Hadi
Hfile
Hbase 的数据以HFile的形式存在HDFS,以下则是HBase的数据存储逻辑结构:
NameSpace > Table > Region > CF > HFile
而HFile则是:
Hfile > Trailer > Load-on-open > bloom Index > Block Data >Root Index > Mediatile Index > Leaf Index > Data Block > KV
HFile存储路径为:
/hbase/data/
可以使用hbase命令来读取HFile文件:
hbase org.apache.hadoop.hbase.io.hfile.HFile -f /上面的路径指定某个HFile -p
// 这个命令还不太行。
逻辑结构
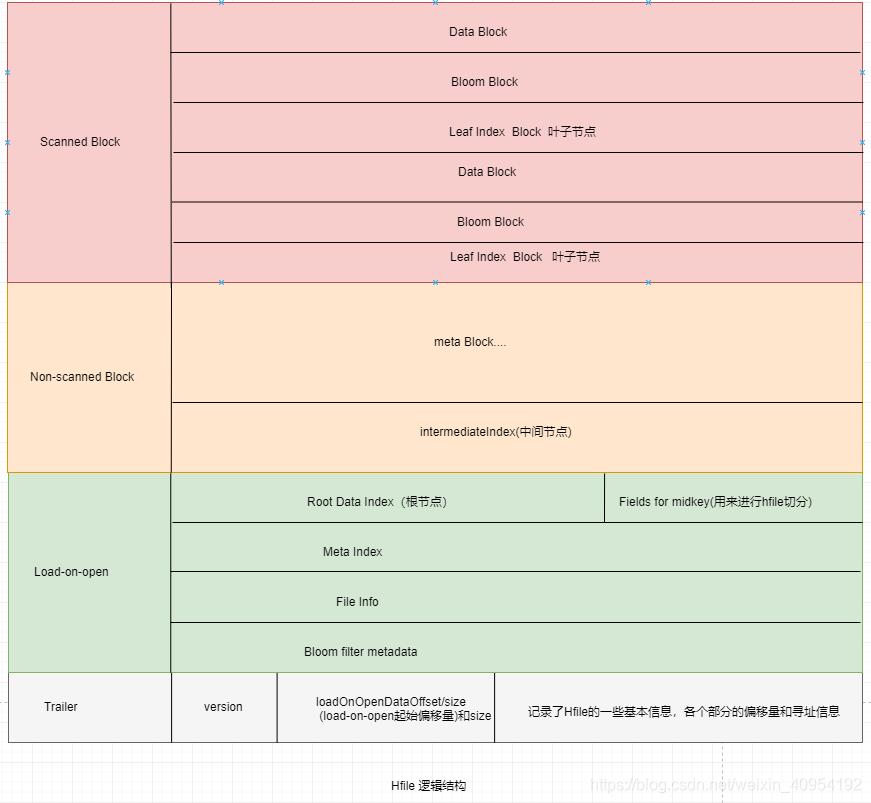
在逻辑结构中,主要为4部分:
-
Scanned Block
DataBlock 存储用户KV数据 LeafIndexBlock 存储所索引树的叶子节点数据 BloomBlock 布隆过滤器相关数据 -
Non-scanned Block
MetaBlock 中间节点数据 扫描Block不会扫描这块 -
Load-on-open
会在RegionServer打开HFile时直接加载到内存中 在Trailer之后 -
Trailer
记录了HFile的版本信息,和其他各个部分的offset。 优先被加载到内存中,然后计算出Load-on-open的长度。 version 最先加载到内存的部分,根据version确定Trailer长度,再加载整个Trailer block LoadOnOpenDataOffset load-on-open区的偏移量(便于将其加载到内存) FirstDataBlockOffset HFile中第一个Block的偏移量 LastDataBlockOffset HFile中最后一个Block的偏移量 numEntries HFile中kv总数
物理结构
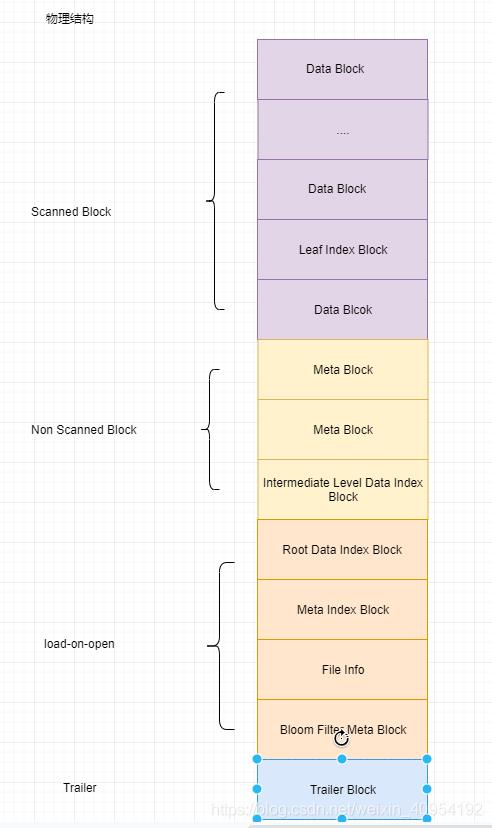
Block块
HFile文件由各种Block组成。Block默认为64KB,所有的Block都拥有相同的数据结构。
每个Block都包含了BlockHeader和BlockData
Header 元数据信息
核心为BlockType,标识这个Block的类型
onDiskType
UncompressedSize
PrevBlockOffset
Data 具体的数据
BlockType包含八种:
-
Trailer Block
-
Meta Block
存储布隆过滤器相关的元数据信息
用户自定义的KV对,可以被压缩 -
Data Block
-
Root Index
根索引 -
Intermediate Level Index
树索引 -
Leaf Level Index
叶子索引 -
Bloom Meta Block
-
Bloom Block
File info 用户在这一部分添加自己的元信息
DataBlock
存储的KV数据
- KeyLength
- ValueLength
- Key
rowKey、ColumnFamily、Column Qualifier、TimeStamp、KeyTpe
KeyType种类包含:put、delete、deleteColumn、deleteFamily
- Value
实际写入数据
以上可以看到,在HBASE中存储的不仅仅是数据,而是每一次的操作。(KeyType的操作类型)
Bloom Block 和 Bloom Index Block
对于给定的key,经过布隆过滤器处理就可以知道HFile中是否存在待检索key。布隆过滤器可以通过计算来获取对应值是否在某个集合中,实现方法是Hash+BitMap实现,具体请参考布隆实现。
不存在的话,就不需要遍历查找该文件,降低IO次数。 布隆过滤器一般会存储在内存中,所以一般整个过程处理耗时基本可以忽略。
在HBase中,为每个HFile都分配了对应的位数组,来存储HFile中K的映射。一旦数据太大就不适合存储在内存中了。因此V2版本将位数组拆分成为了多个位数组。一部分连续的key使用一个数组。这样,一个HFile就会有多个位数组,针对每个key数组有对应的索引,来定位到具体的位数组。
Bloom Index Block 位于Load-on-open部分,在regionServer读取HFile时候,会直接加载到内存中。
所以一个get请求根据布隆过滤器大概分为3步:
- 根据key在Bloom Index Block 所有的索引项中根据BlockKey进行二分查找,定位到对应的Bloom Index Entry
- 根据Bloom index Entry中的BlockIffset以及BlockOndiskSize加载key对应的位数组
- 对key进行hash映射,根据结果判断所在位是1or0
HFlie关于索引的Block
根据索引层级不同,HFlie的索引结构分为
- single-level
- multi-level
一般2-3级
随着HFile文件越来越大,DataBlock越来越多,索引的数据也就越来越大,无法全部加载到内存。索引使用多级索引,只加载部分索引,从而降低内存使用空间。
索引类型
root Index Block
位于load-ono-open部分
会在regionServer打开HFile时加载到内存中
记录了MidKey相关信息,用于Split操作时,快速定位HFile的切分点位置。
intermediate Index Block
位于Non-Scanned-Block
Leaf Index Block
位于Scanned Block
直接指向时间Data Block
HBase 随机读写
首先使用MemStoreScanner搜索MemStore里面是否含有所查的rowKey,内存中。
同时使用Bloom Block通过一定算法过滤掉大部分一定不包含所查rowKey的HFile。
RegionServer启动的时候就会把Trailer 和Load-on-open-section里的block先后加载到内存// todo 哪里,
所以接下来会查Trailer,因为它记录了每个HFile的偏移量,可以快速排出剩下部分HFile。
读取HFile,根据index Block索引快速查找rowkey所在block位置。
找到block后,查找是否在blockCache中,如果没有就会将其加载到blockCache中。
然后根据查找条件将结果进行放回。
BlockCache
BlockCache会单独发表文章进行讲解,请参考其他blog
以上是关于HBASE中HFile结构-你真的知道Hbase怎么查数据?的主要内容,如果未能解决你的问题,请参考以下文章