NiFi ListSFTP精讲
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NiFi ListSFTP精讲相关的知识,希望对你有一定的参考价值。
序
since: 2021年5月20日 22:29
auth :Hadi
前言
从去年年末开始接触使用到NiFi,到现在为止已经将近半年,这里将一下关于ListSFTP类相关组件的使用。NiFi可以当做Flink进行使用,但不是很推荐进行复杂计算的使用,对于我的使用场景来说主要是做数据采集和预处理相关的工作,负责数据流程的第一步,同时也做数据的转换操作比如流式转文件,文件转流式等等。
那么获取数据是整个数据预处理的第一步,一般我们都是采用List & Fetch的操作进行数据预处理,比如:
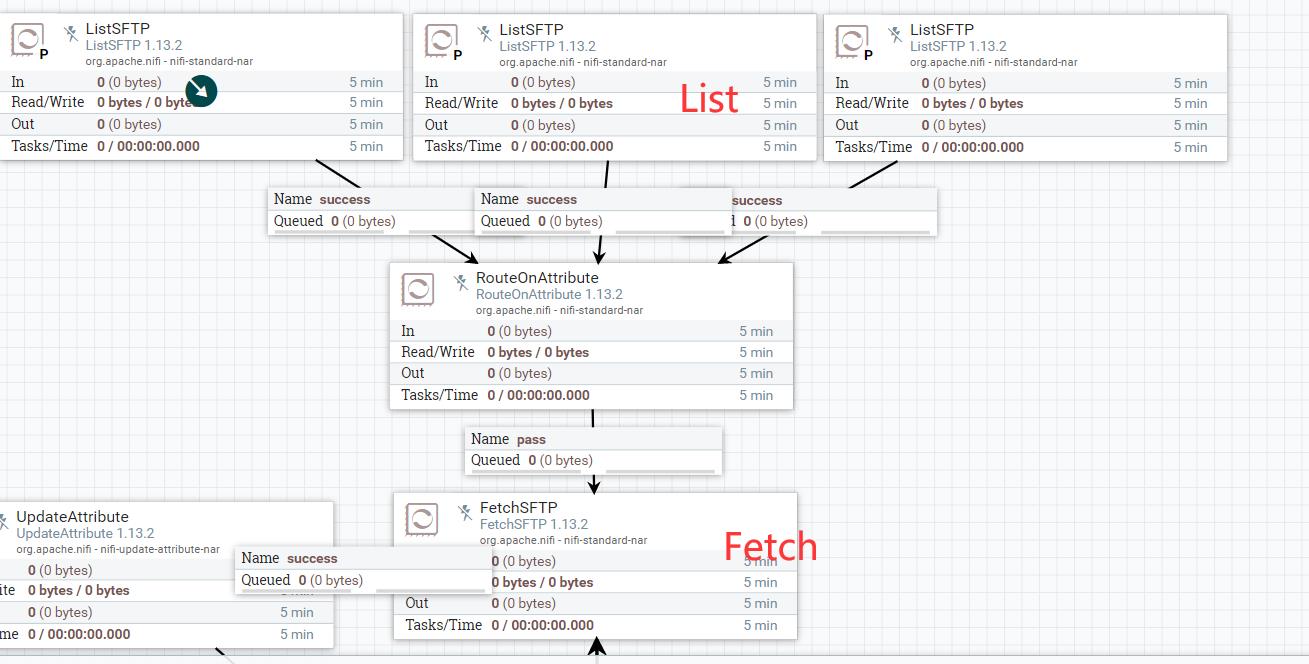
预先通过List进行数据列表的扫描,然后通过Fetch进行数据的拉取形成带真正带有数据的FlowFile(FlowFile为NiFi的最小处理单位,代表一个文件,数据集,message等)。List只会进行列表的输出,比如XXX服务器上的一个文件清单,交给Fetch,根据FlowFile上的Attributes进行文件的拉取。
这篇Blog主要讲解ListSFTP为模板,进行各类List的讲解。
ListSFTP配置
直接上图:
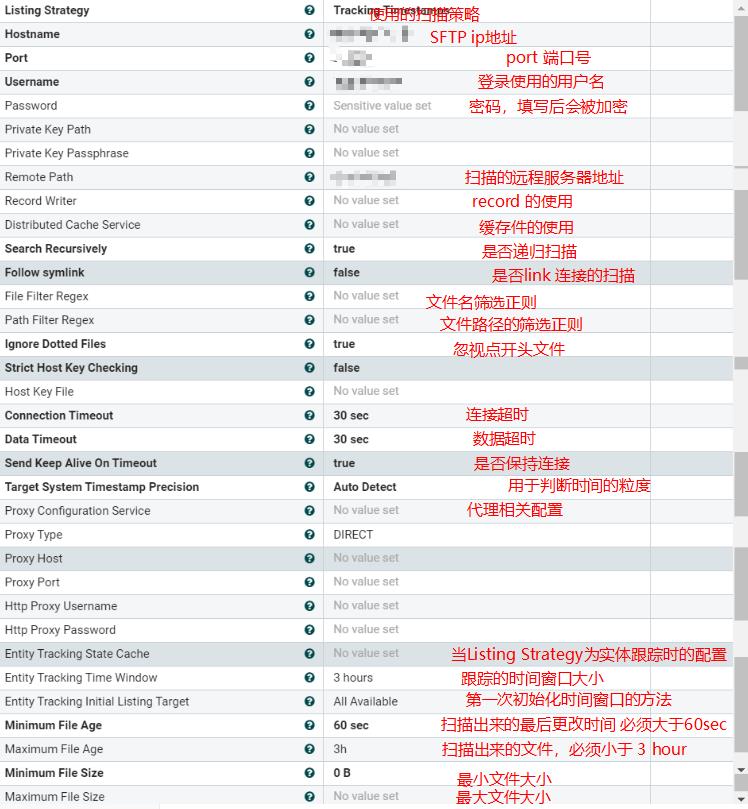
列表策略
在进行扫描的时候,List的任务都是想要扫描出最新的文件,或者是被修改过的文件,不然就没有任何扫描的意义。那么在这个前提下,诞生了四种策略:
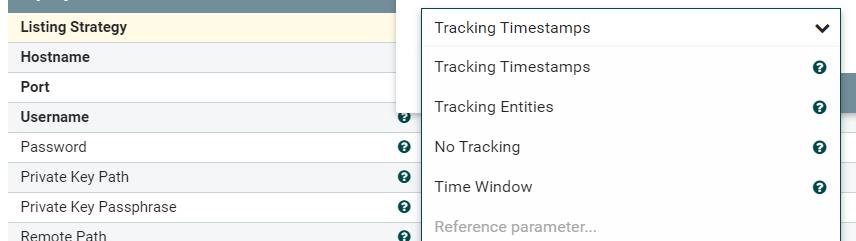
Tracking Timestamps
根据时间戳对文件的筛选过滤,简单的说就是通过上一次扫描出来的文件的最后修改时间T作为下一次扫描的标准,判断是否是最新的文件的标准为:只要文件的最后修改时间大于等于上个时间T,并且大于上一次生成的最大文件的时间,那么我就认为是新的文件。
一个为扫描出来的最大时间listing.timestamp,另一个为输出的文件最大时间processed.timestamp。
那么如果我们配置好List后,第一次扫描,是无法将扫描对象中的所有符合条件的数据都扫描出来;在没有新的文件出来的时候,必须在第二次才会将最后一个时间戳(并不准确,最小单位受到 Target System TimeStamp Precision的影响)的文件列出来。
这里需要注意的是,一般我们常用的Listing Strategy为Tracking Timestamps的话,可能导致以下一些问题:
当生成文件被更改了最后修改时间,那么List很可能是无法进行数据的拉取。1. 比如被刻意进行的 touch -t 202105205200 文件,那么这个办法完全无法进行数据的拉取。这种情况可能并不多见,但是在生产环境下会有极大的概率导致文件缺失。2. 在所有List相关的组件里面,如果某个目录无法进行递归,那么就会报错并跳过该目录;遇到这种情况时,可能会导致其他文件夹将时间限定往前推了,导致这个文件夹的一段时间数据丢失。
所以在生产环境下极力不推荐使用Tracjing Timestamps,除非你有神人帮助,或者数据种类少,方便维护,偷个懒。
No Tracking
更简单了,就直接不进行跟踪,直接进行全量列表的输出,那么就不用管到底数据是新是旧,直接拿走。
Tracking Entities
根据每个实体进行跟踪。这个配置起来就比较麻烦,需要配置一个缓存器,然后配置连接缓存器的线程池。
在Listing Strategy中选择Tracking Entities,然后在Entity Tacking State Cache中选择使用的缓存方法包含:
CassandraDistributed、CouchBase、DistributedMapCacheClientService(NiFi自带)、HBase、Hazelcast、Redis,共计六种。
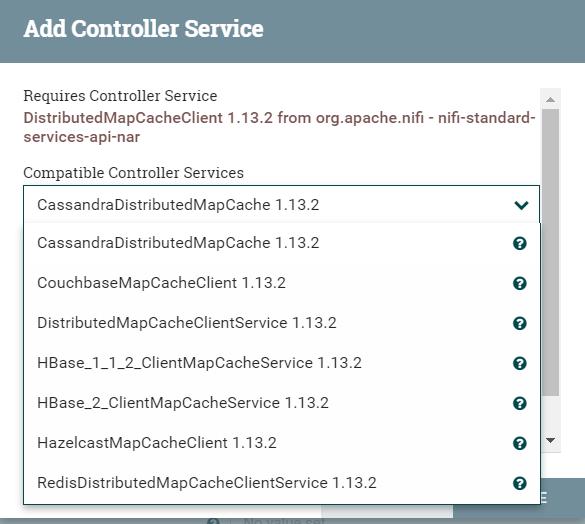
使用上来说NiFi自带的当然最简单,但是也越不可靠,推荐使用Cassandra和Hbase和Redis。由于大数据系统一般至少有Hbase,那么就以Hbase为列进行讲解:
创建了Hbase_XX_ClientMapCacheService后,还需要进行这个Service的配置,点击这里进行下一步的配置操作:

跳转后,点击后面的小齿轮进行配置:
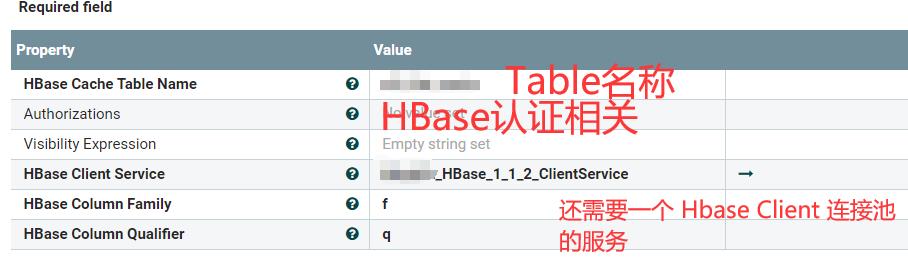
继续配置HbaseClientService:
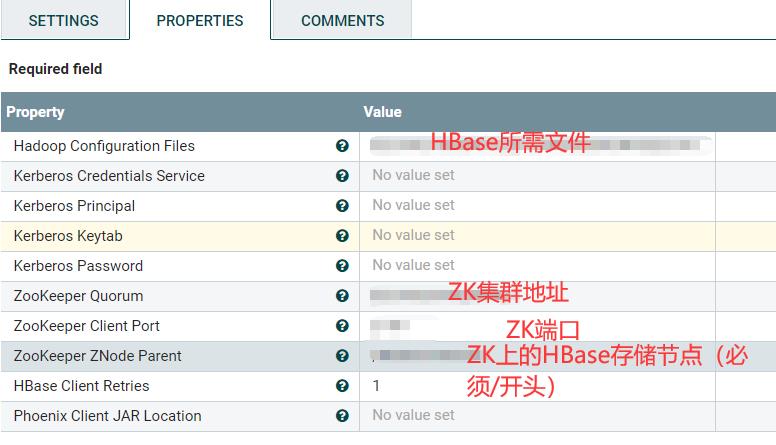
上面HBase所需的文件为CoreSite.Xml,HbaseSite.Xml,HdfsSite.Xml三个文件,需要放在NiFi集群的所有服务器节点上同一个路径下,三个文件的路径使用“,”来进行拼接即可。
配置成功后,然后可以看见:

可以看到有两个Service,一个是HBaseCache服务,一个是连接HBase集群的服务,前者依赖于后者。
这个时候我们运行List,就会将缓存存储到HBase表中,然后每次List都会进行前后两次List的对比,来获取文件。这个好处在于在时间窗口中的数据也会被比较,如果这部分数据被漏采,那么就会被List出来,而不是直接被抛弃;如果文件时间戳被更改,还在时间窗口内,那么数据文件也不会被更改。坏处在于:配置麻烦;性能降低;而且在HBase中存储时是一个List Component为一条数据,这Component List出来的数据为Value保存,所以这个value可能特别特别大。
Time Window
抓取最近一段时间的文件,这个意义也不太大,一般用于更新数据的时候使用。
List BUG和改造
List任务只能单个线程进行,为了保证这个任务的单线程进行,直到1.13.2版本的NiFi只能配置这些任务在主节点进行,那么过多的List任务会占用主节点过多的CPU和内存。并且由于NiFi的机制,在这个节点上的数据,后续如果没有balance那么就只会在这个节点进行运行,所以要注意的是:1.不能list过多的数据,防止主节点GG。2.必须在List后续进行balance操作然后Fetch,将主节点的数据分配到各个节点上。
NiFi是开源的,所以很容易就能找到NiFi的源码,在ListSFTP/FTP这块,NiFi貌似并没有准备将其打造成一个可以扫描大数据场景的组件,而是假设了NiFi不会扫描上50w,100w,1000w的文件系统。当扫描这么多数据的时候,JVM堆直接撑爆GC,导致Stop The Word,更会导致与ZooKeeper断开连接,导致主节点切换,导致所有主节点任务脑裂的问题出现。
这个问题主要是这个原因导致的:使用ArrayList进行全量的数据存储。
在 org.apache.nifi.processor.util.list.AbstractListProcessor 中的代码,大家可以好好读一下,基本逻辑就搞清楚了。
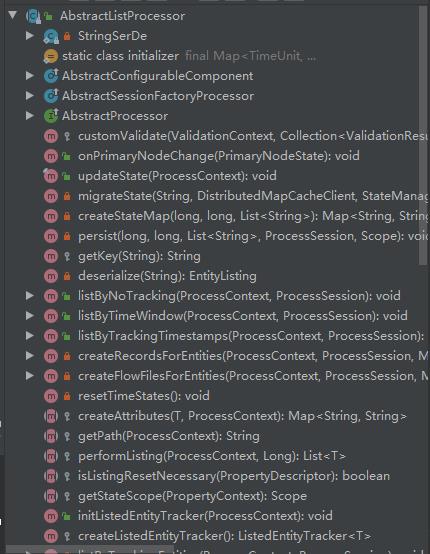
主要问题可以直接聚焦org.apache.nifi.processors.standard.util.SFTPTransfer#getListing()中,我们主要看SFTP的实现:
红线中主listing主要用于 SFTPClient进行扫描时,扫出来的全量数据,再根据这个listing进行后续的时间戳、实体之类的进行判断,但这个是个ArrayList,当数据量大的时候,需要进行扩容,导致内存中必须一直开连续的空间给他。第二,为什么要进行全量的数据扫描呢?本来就会根据文件的时间戳进行筛选过滤的。这个逻辑也不太对,导致多塞入了很多数据。
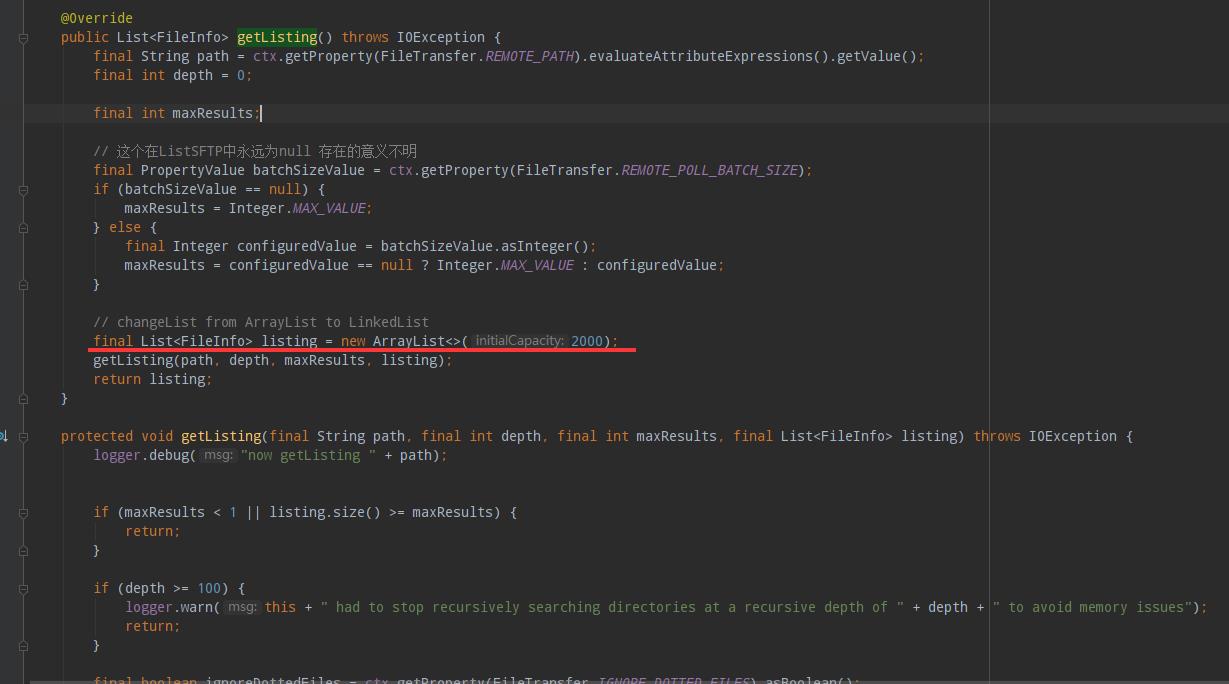
然后聚焦于下面的getListing递归方法:
在后续定义了一个filter,用于递归筛选后续的文件和文件夹;文件放入listing中,文件夹放入subDirs中,但可以看到如果是文件夹那么就直接放入递归队列中,这种也是匪夷所思的,因为我们配置路径的时候已经有正则进行筛选了。(Path Filter Regex)。所以,如果需要进行优化的同学可以自己优化,我这边优化过了,但是是公司代码,所以现在还不能公布。
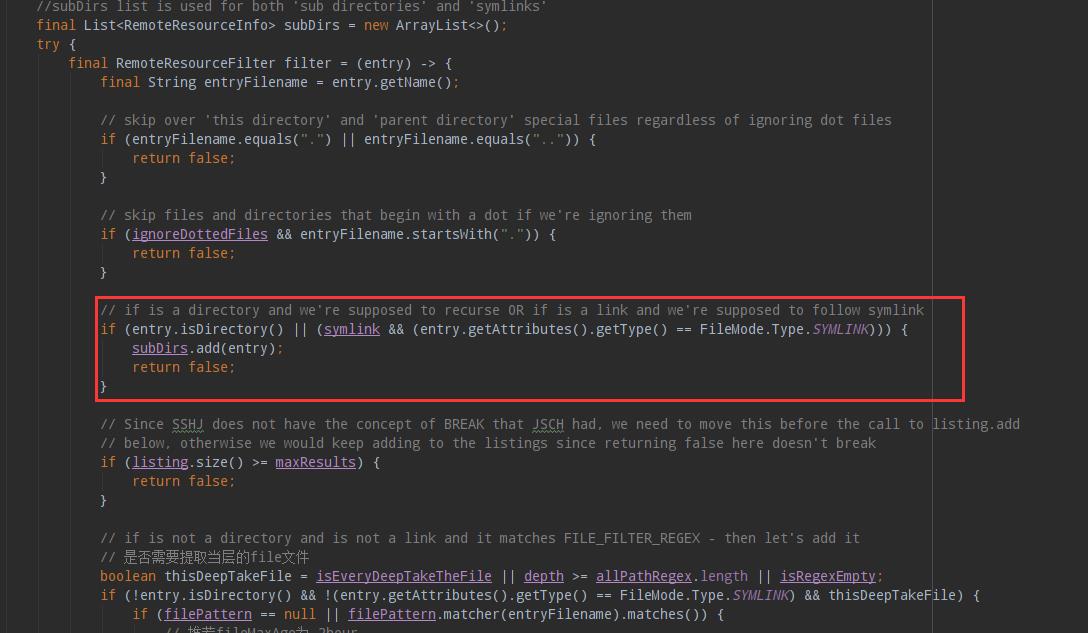
优化:对于我们大多数来说,一般来说都是扫相同等级的目录,必须/XXX数据大类/XXX数据小类/XXX标识/20210520/数据,这样进行累加,那么必然我每次都会扫描时间那一层及的所有数据,但是根据时间戳的时候,我们可以扫描到时间文件夹这层的时候,对这个时间文件夹进行判断,看里面时候有新的数据。如果在一段时间内有我们才进入进行扫描等等。
同类List
对于SFTP是这样的,同比FTP、HDFS、File等文件系统的List,NiFi组件都有这个毛病,没有将时间戳用到极致,浪费了挺多的资源进行扫描。各位在进行组件优化的时候,还是根据公司的业务情况进行实际组件的开发时最合理的。
比如对Hive离线表的扫描,如果使用原生的ListHDFS那么对于SQL任务,很可能是无法进行扫描的。(SQL是先生成.Hive-staging文件,然后将整个文件夹迁移过来;并不是直接生成在表的分区中)很可能导致数据的缺失。
后记
在大数据场景下,我也一直在怀疑NiFi是否能支撑主我的想象,从目前发展来看,有好有坏。
我想表达一点,NiFi这样的可视化界面操作,让整个开发流程变得很简单,同样的会导致整个门槛的降低。良莠不齐,不思进取,贪图享受,在有了工具之后,我们需要想象的是将工具用的更好,多多去社区上提issue,改善代码环境才是真。
以上是关于NiFi ListSFTP精讲的主要内容,如果未能解决你的问题,请参考以下文章