Quorum Journal Manager QJM实现高可用HA文件同步原理
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Quorum Journal Manager QJM实现高可用HA文件同步原理相关的知识,希望对你有一定的参考价值。
序
since: 2021年5月23日 16:13
auth: Hadi
参考:
https://blog.csdn.net/breakout_alex/article/details/88171114
https://blog.csdn.net/weixin_42782897/article/details/89335674
https://blog.csdn.net/zuotengseven/article/details/108216736
前言
上次我们讲了Hadoop 高可用原理主要是分为两大块,1.数据文件的同步共享;2.热备切换机制。详细可以参考这里。在数据文件同步共享中,我们讲解了再Hadoop2.X的版本中使用了QJM进行文件的数据同步,那么为什么选择了QJM,那么QJM到底是什么,怎么进行的文件同步,怎么保证文件的一致性呢?
历程
在HDFS-1623 和其他相关的JIRA在现有HDFS的NameNode基础上增加了HA的支持,但是还是需要一个存放EditLog文件的共享存储目录,这个共享存目录的要求也必须是高可用的,可以被集群中所有的NameNodes同时访问。
目前对于共享的EditLog存储目录,一个推荐的做法是通过NAS (Network-attached storege,网络关联的存储)设备,然后挂载到NFS上。那么这个挂在好的目录允许Active NameNode写EditLog到上面,同时Standby NameNode可以通过tail的方式去读这些文件。
但以上的假设在某些场合下是不满足要求的:
- 需要定制硬件,一个NAS设备和远程控制单元PDU的价格是很昂贵的。
- 复杂的部署。需要额外的步骤来配置NFS挂载目录,自定义的fencing限制脚本等等,导致HA的复杂化。
- NFS Client实现简陋,不够健壮。
那么对此新生的方案有以下的追求:
- 不需要对特定的硬件有什么要求。
- 没有对fencing限制脚本的要求。所有需要fencing的操作应该只需要发生在软件层面,封装到系统中实现。
- 没有单节点故障问题。
QJM
Quorum Journal Manager由 Cloudera工程师 ToddLipcon主导设计。最初的思想来源于Paxos协议,摒弃了AvatarNode方案中的共享存储设备,改用多个JournalNode节点组成集群来管理和共享EditLog。与Paxos协议类似,当NameNode向JournalNode请求读写时,要求至少大多数成功返回才认为本次请求成功。所以最多可以容忍N台JournalNode节点挂掉(总量2N+1)。
QJM中主要包含了 JournalNode Cluster 简称JNs,是一个一致性存储系统,是HDFS NameNode高可用的核心组件。借助JournalNode集群,Active NameNode可以将元数据及时的同步到StandBy NameNode中。同步的数据为EditLog。
此过程是Active NameNode主动进行推送,StandByNameNode主动拉取数据,整个过程JournalNode不会主动进行数据的交换。
EditLog文件写入流程
JournalNode中存什么
Active NameNode 只会往JournalNode中写入EditLog文件,并不会写入Fsimage。
而StandBy NameNode 也只会拉取Edit 文件,并进行回放,此文件并不会进行落盘。
Active NameNode 写入Edit文件流程
在Client端发起了某项操作命令后,Active NameNode将其操作写入EditLog中,此时的流程如下:
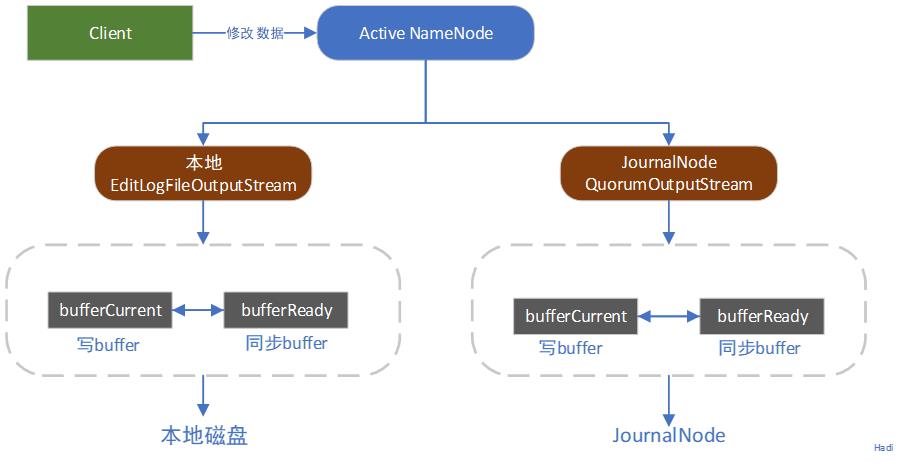
Active NameNode会将产生的Edit Log文件同时写到本地和JournalNode中。本地配置由参数中的dfs.namenode.name.dir进行控制;而写入JournalNode由参数dfs.namenode.shared.edits.dir进行控制,所以如上图所示,会有两个流进行同时输出。并且值得注意的是,EditLog并不是直接写入本地侧畔,而是有大小512KB的写Buffer和一个同步Buffer。这样就可以实现一边写一边同步。所以EditLog是一个异步写过程,同时也是一个批量同步的过程,避免每一次的操作引起一次写操作。
边写边同步的实现:其实就是缓冲区交换。当两个缓冲区,到达条件时就会触发交换操作,如bufferCurrent在达到阈值时同时bufferRead的数据同步完成时,就会交换两者的指针。那么这个操作是怎么解决数据不丢失的呢?其实就是真的写入logSync同步成功后才会返回到成功码。(其实就是避免在同步到磁盘的时候造成无法数据的提交)
JournalNode 的文件写入流程
在写入数据的时候会执行logSync过程,Acitive NameNode将数据放入缓存队列中。然后将缓存队列中的数据同步到JournalNode中,其有相应的线程来处理logEdits请求。在JournalNode接收到数据后,会判断跟随的EpochNumber是否合法,再判断日志事务ID是否合法,然后返回是否成功。
EpochNumber和日志事务ID在后面有所讲解。
EditLog怎么在多个JN上保持一致
隔离双写
在Active NameNode 每次同步EditLog到JournalNode时,首先要保证不会有多个NameNode同时向JournalNode同步日志。这里使用到了Epoch Numbers。
每当NameNode成为Active节点时,会得到一个唯一有序的EpochNumber,在每次切换NameNode的时候都会自增1(是NameNode中的QuorumJournalManager赋予的)。这个EpochNumber类似于了paxos中的版本号。当QuorumJournalManager获得了EpochNumber之后,会通过newEpoch(N)的方式将值发送到所有JournalNode节点。
每个JournalNode只会接受最大的EpochNumber的消息,并且将其保存在lastPromisedEpoch变量中,并持久化到本地磁盘。
恢复in-process日志
在NameNode成为Active,需要开始写JournalNode的Edit文件时,如果各个上的EditLog长度都不一样长,则需要在开始写之前将不一致的部分恢复。新的Active NameNode需要尽快将自己和各个JournalNode上的Edit数据信息同步到最新的地方。
- QuorumJournalManager先会对所有的JournalNode发送getJournalState请求
- JournalNode返回最新的lastPromisedEpoch
- QuorumJournalManager收到大多数JournalNode的Epoch后,选择最大的+1作为自己的Epoch(存疑),然后开始向JournalNode发送新的newEpoch请求。
- JournalNode接收到新的Epoch后,进行lastPromisedEpoch对比,如果比自己的更大,则返回自己最新的EditLogSegment起始事务id;如果更小则返回错误。
- 这个时候Active NameNode会选择最高的EditLogSegment事务ID为依据进行数据恢复。向JournalNode发送prepareRecovery RPC请求,若阁多数JournalNode响应,则prepareRecovery成功。(Paxos Phase 1A)
- Active NameNode选择进行同步的数据源,向JournalNode 发送acceptRecovery RPC请求,并将数据源作为参数进行传递。
- JournalNode接收到acceptRecovery请求后,会从JournalNodeHttpServer下载EditLogSegement并替换到本地报错的EditLogSegment中,完成后返回成功。(Paxos Phase 1B)
- Active NameNode中收到大多数JournalNode的响应成功请求后,向JournalNode发送FinalizedLogSegment请求,标识数据已经回复完成,这个时候保证JournalNode上的日志保持一致。这个时候也会将自己的in-process状态的日志更新为finalized。(形式如edits[start-txid][stop-txid])
存疑点
上面整个过程其实就是一个变相的Paxos的过程,准备阶段和执行阶段几乎一模一样。有任何问题还是推荐查看专门写的Paxos篇幅进行讲解的内容。
为什么“大多数”就是正确的,从“大多数”中选择最大的+1作为自己的Epoch就永远不会重复呢?数学推理法,假设当前最大的为N,则必定有一半以上的JournalNode的lastPromisedEpoch最大也为N(定义)。那么从全部中选择一半以上进行最大数的挑选,必定为N。所以N+1必定唯一且最大。
基于Quorum最低法定人数的方案
基于Quorum commit的设计:Quorum Commit 来自于集群中的守护进程程序,在QJM中就是JournalNode。每个JournalNode都会暴露一个简单的RPC杰阔,允许NameNodes去读写存在各个磁盘上的EditLog日志。当一个Active NameNode要写一个Edit文件时,他将发送此Edit到集群中所有的JournalNode,然后等待大多数的JournalNode的返回。一旦超过一半的JournalNode回应成功,那么Edit被认为提交成果。
整个过程类似于Simple-Paxos。
JournalNode Cluster
上面提到了NameNode 与 JournalNode Cluster进行数据读写时核心点是需要大多数JN成功返回才可认为本次请求有效。所以与ZooKeeper一样,部署的节点也请采用奇数节点进行部署(如果采用了偶数节点,那么在极端的场景下会产生活锁 【Paxos made simple [2]中有讲解,可参考这】)。
同其他的集群节点一样,JournalNode Cluster中所有的JN之间完全对等,不存在 Primary/Secondary之间的区别;从功能上来看也是极其简单的,在Hadoop 2.7.1中总共只花费了2.5K行代码实现了完整的journalNode功能,功能架构如下图所示:

JournalNode 对外提供RPC 和 HTTP 两类数据服务接口,分别由两类服务进行提供。除了这样常规暴露Metrics信息外,同时提供了被动EditLog数据同步功能。
JournalNodeRPCServer
提供了RPC Server,为NameNode想JournalNode数据的读写和状态获取请求准备了完备的RPC接口,这个采用QJournalProtocol.proto实现,主要提供的模块就是Journal模块对外服务。
JournalNodeHttpServer
提供HTTP数据结构,暴露常规的数据接口与HTTP状态服务等。
Journal
简单维护JournalNode状态信息,核心是实现抽象底层存储介质的读写操作。
Metrics
度量统计,分别包括了客户端和服务端的。
落后统计:对于每个HournalNode,跟踪此节点相比于Quorum值已经落后了多少,包括时间值和事务数。
延时空寂:包含客户端写Edit时的PRC调用的往返延时,以及调用写磁盘相关方法Fsync()时的延时
队列大小:因为Client在队列中会不断累积数据,所以这需要提供一些指标能够观察里面队列的长度,包括原始数据的大小以及事务数量。
JournalNode 整体
为了降低读写操作互相影响,Journal 采用了DoubleBuffer技术管理实时过来的EditLog数据,通过DoubleBuffer可以为高速设备(MEM) 与 低速设备(磁盘/SSD) 之间建立缓存区和管道,避免数据写入被低速设备阻塞影响性能(相同的地方比如HBase写操作)。
NameNode到JournalNode的所有数据写入请求都会直接落盘,当然写入请求的数据可以是批量数据,只有数据持久化完成才能认为本次请求有效和成功。
与Paxos类似,所有到达JournalNode的读写请求,第一件事就是合法性的校验,包括EpochNum,CommitTxid等在内的状态信息,只有校验通过才能被处理,状态校验是强一致性的保证基础。
所以 JournalNode 为Hadoop提供了一套读写服务,强一致性的有状态性的系统。
JournalNode 性质
在QJM中,它本身就是一种简化Paxos协议的实现,按照分布式CAP进行评估,其也是一种强一致性、高可用的去中心化分布式协议。
高可用
Paxos本身就是针对节点脱离、数据丢失等等情况发生的分布式一致性协议。其可以容忍至多小于一般的节点运行。但是为了实现强一致性,QJM方法了故障范围(只要出现一次请求响应失败或者超时即标记JournalNode在当前Segment范围内失效 outOfSync),而且对于故障完全没有回复能力。
高度去中心化
在JournalNode整个生命周期,每个Node之间没有任何差异性,完全对等,完全无中心化节点,这样也就比存在什么SPOF问题,具备Partition Tolerance特性。
强一致性
Paxos的思想就是为了得出分布式的共识也设定的协议,但QJM为了达到更好的性能,在此之上又减轻了很多的限制条件。比如Paxos主要是服务一次数据共识的达成,在快速写入的场景下,这个方案并不是最好的(比如Multi-Paxos选出主节点进行代理节点);而且一般我们只会存在两个Qjournal Client(2个NameNode),竞争发生的条件也非常的苛刻,即使极端及情况下产生竞争也能够在一轮竞选完成。
延后读 保证数据强一致性。 StandBy NameNode当前仅读取和回放Finalized状态Segment,可以保证Finalized数据强一致。借鉴Paxos思想,在数据恢复阶段就可以做到Inprogress状态数据强一致性,同时QJM采用了一种尽力而为的恢复机制,对不确定状态定义了统一的恢复策略。
全局有序和递增的Epoch序号,任意时间只一个竞争者生出,保证写入端的唯一性和合法性。
后记
QJM其实内容真的挺多的,后续还有很多故障恢复呀(跟Hbase一样嘛),什么联机故障等等,但道理看多了这个架构还是很清晰了。
写完睡觉。
以上是关于Quorum Journal Manager QJM实现高可用HA文件同步原理的主要内容,如果未能解决你的问题,请参考以下文章