Hadoop高可用HA原理-全流程讲解
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop高可用HA原理-全流程讲解相关的知识,希望对你有一定的参考价值。
序
Hadoop高可用全流程讲解
since:2021年5月22日 21:36
auth:Hadi
参考:
https://blog.csdn.net/weixin_40652340/article/details/78557775
https://blog.csdn.net/weixin_42782897/article/details/89335674
https://blog.csdn.net/qq_24852439/article/details/104185496
前言
玩hadoop玩了这么久,又快忘记hadoop到底是个啥了,所以继续以写代回忆,重新梳理一下Hadoop高可用的原理以及实现原理。
背景
在Hadoop 2.0之前,在HDFS集群中时存在NameNode的单点故障的,当NameNode由于各种原因出现故障的时候,将会导致整个集群无法使用,直到这个NameNode重新启动。当时是有Secondary NameNode,但是这个只是与NameNode进行分担工作,主要处理日志合并等数据,并不是实时同步所有数据的。
所以在Hadoop 1.X的时候,机器需要进行升级、迁移等时,集群是无法进行正常使用的。
在Hadoop 2.X后,HDFS实现了高可用的架构模式,由两个NameNode进行共同管理集群,一个Active 一个StandBy。当Activity NameNode 宕机或其他情况出现时,StandBy NameNode将会通过一系列的变化成为Active状态,开始进行集群各类请求处理。
高可用HA
上述已经讲明,Hadoop 2.X实现高可用的方法就是两个NameNode,一个正常处理请求,一个进行类似Secondary NameNode节点的工作,帮助将edits文件合并到fsimage中,属于一个热备 Hot Standby NameNode。如下图所示:
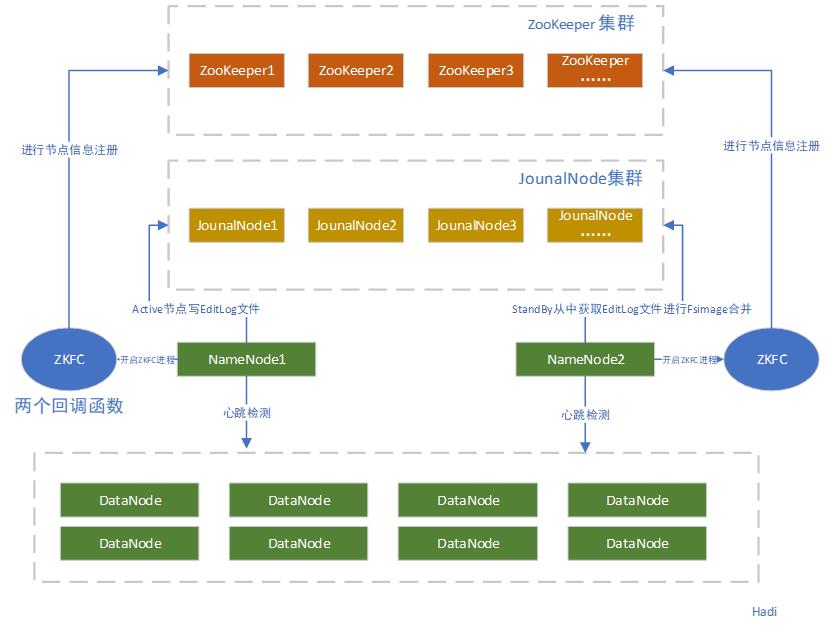
引入了双NameNode架构,同时借助数据共享存储系统来进行元数据的同步,共享存储系统类型一般有几类:比如Shared NAS+NFS、BookKeeper、Quorum Journal Manager和BackupNode,上图使用的就是 QJM 作为数据文件的共享存储组件,通过搭建的奇数台实现主备NameNode元数据的操作信息同步。
NameNode通过ZKFC进程选举Active,监控状态,自动备援,后续会进行ZKFC的单独讲解。
DataNode们会向ActiveNN和StandByNN发送心跳,汇报信息情况。
工作职责
Active NameNode
接受Client端的RPC请求,并进行处理,同时写自己的EditLog和共享存储上的EditLog,接受DataNode的Block report、Block Location Updates、 Heartbeat。
StandBy NameNode
接受到的RPC请求会转发给Active NameNode。同样会接受到DataNode的相关信息汇报。会将共享存储上的EditLog读取出来并执行Log操作,使得自己的元数据(NameSpace Information & Block Locations Map)都是与Active NameNode中相同。所以说StandBy NameNode是一个热备,一旦需要就可以马上提供服务。
JounalNode
用于Active NameNode 和StandBy NameNode之间的数据同步,本身是由一组JounnalNode奇数节点组成,支持Paxos协议(可参看Paxos讲解),保证高可用,是CDH5唯一支持的共享方式。
ZKFC
一个单独的进程,用于监控本地的NameNode健康状态;代替NameNode定期向ZK发送心跳是自己被选举;告知NameNode进程自己被ZooKeeper选中,通过回调函数 active FailoverController通过RPC调用使相应的NameNode转换为Acitve;提供自动备援的能力。
竞选流程
既然有了两个NameNode,那么势必也扯到NameNode在进行选举。在NameNode的选举机制主要为抢占式,在启动了NameNode进程后,各个节点的ZKFC进程就会向ZooKeeper进行抢占式的注册,如果注册成功,那么就会将成功的消息回调给NameNode,那么这个NameNode就成为了Active状态;如果没有注册成功,那么就会持续成为StandBy状态,干StandBy的活。
具体如下图:
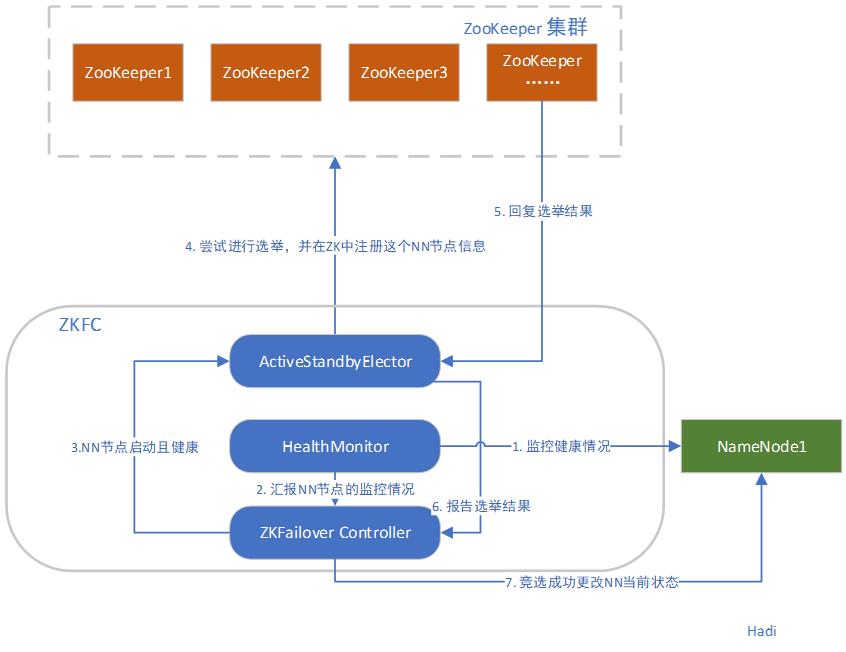
所以,只要谁进行前四步的过程快,谁就会成为Acitive 节点。
主备切换
刚刚说了高可用主要实现需要两个步骤,1.数据同步,保证备份节点与主节点两者的信息数据相同。 2.完整的主备切换机制。当主节点发生故障时,需要启动该机制,来维护整个集群的任务不受影响。
Active NameNode操作
在竞选流程中也说明了,选举相关主要还是依赖于ZooKeeper,那么主备切换相关的也会围绕着ZooKeeper进行,主节点相关的操作如下图:
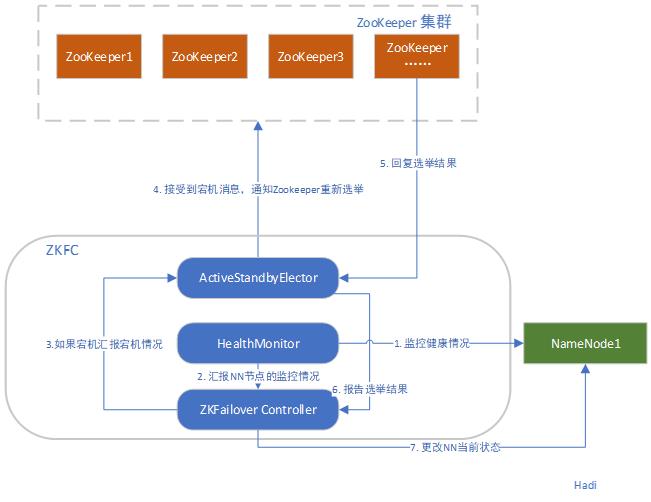
这个步骤是比较理想化的操作,可能只是NameNode进程挂掉,或者长时间Full GC无法对外提供服务,那么 HealthMonitor就将会捕捉到异常,对ZK进行主节点注销操作。并且对NN进程进行状态修改。
但其他情况也会很多种,比如说整个节点物理服务器挂掉,那么NN和ZKFC就会同时挂掉,没有人对ZooKeeper上的信息进行修改,也不会通知ZooKeeper需要重新进行选举。这个时候怎么办?就要使用到ZooKeeper上的节点类型原理,在ZooKeeper上,有四种节点。当我们采用临时节点对数据进行注册的时候,如果与ZooKeeper失去了心跳,那么ZooKeeper会自动删除节点。而且对应watch这个节点数据的线程就会接受到信息(如上图的第5步就是一个回调),这个时候StandBy NameNode就获取到Acitive NameNode的丢失,尝试进行转正的操作。
StandBy NameNode操作
相同的,StandBy NameNode在ZooKeeper上watch住节点,当注册节点有任何的变化的时候,就会去抢占式注册,注册成功就可以开启Acitive模式。但是为了防止脑裂,必须向之前的NameNode发送切换指令,让其更改状态。
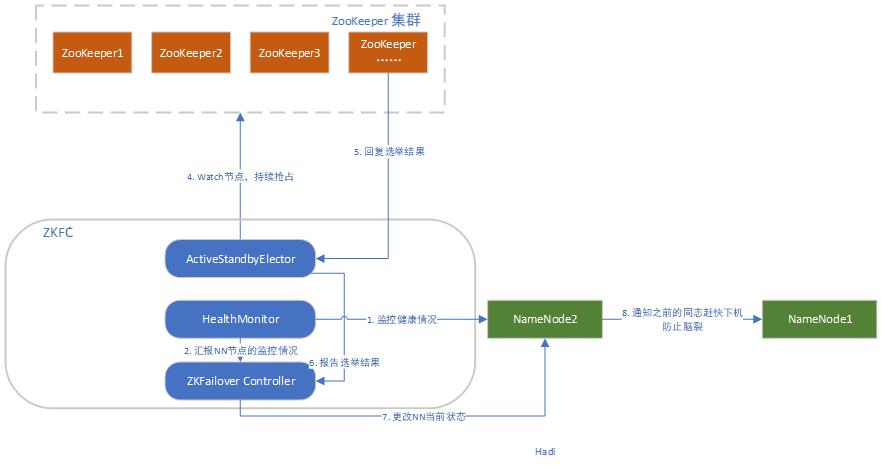
ZooKeeper充当的作用
失败保护机制,刚刚也说了,如果整个物理机或者ZKFC也宕机的话,那么没有人通知ZooKeeper当前节点挂了。只有ZooKeeper来清理失去心跳的节点信息,触发故障迁移。
提供给StandbyNameNode一个回调机制,只需要他们Watch住节点,当节点发生改变时由ZooKeeper进行通知。
防止脑裂,多各节点都是Active状态。由于ZooKeeper本身的强一致性和高可用,可以用它来保证同一时刻只有一个活动的节点。
故障切换场景
ActiveNN JVM奔溃:ANN上HealthMonitor状态上报会有连接超时异常,HealthMonitor会触发状态迁移至SERVICE_NOT_RESPONDING, 然后ANN上的ZKFC会退出选举,SNN上的ZKFC会获得Active Lock, 作相应隔离后成为Active结点。
ActiveNN JVM冻结:这个是JVM没奔溃,但也无法响应,同奔溃一样,会触发自动切换。
ActiveNN 机器宕机:此时ActiveStandbyElector会失去同ZK的心跳,会话超时,SNN上的ZKFC会通知ZK删除ANN的活动锁,作相应隔离后完成主备切换。
ActiveNN 健康状态异常: 此时HealthMonitor会收到一个HealthCheckFailedException,并触发自动切换。
Active ZKFC奔溃:虽然ZKFC是一个独立的进程,但因设计简单也容易出问题,一旦ZKFC进程挂掉,虽然此时NameNode是OK的,但系统也认为需要切换,此时SNN会发一个请求到ANN要求ANN放弃主结点位置,ANN收到请求后,会触发完成自动切换。
ZooKeeper奔溃:如果ZK奔溃了,主备NN上的ZKFC都会感知断连,此时主备NN会进入一个NeutralMode模式,同时不改变主备NN的状态,继续发挥作用,只不过此时,如果ANN也故障了,那集群无法发挥Failover, 也就不可用了,所以对于此种场景,ZK一般是不允许挂掉到多台,至少要有N/2+1台保持服务才算是安全的。
规避脑裂
脑裂是啥
当存在两个Active NameNodee同时向外进行服务的提供,那么就会造成两个NameNode之间的元数据有不同,形成脑裂的状态。
脑裂的原因
如果ZooKeeper的服务器进入了JVM Full GC,那么可能会导致ZooKeeper客户端到服务端的心跳不能正常发出,超过了配置的ZookeeperSession Timeout参数,那么ZooKeeper会认为注册的临时节点失效,关闭Client Session,造成当前节点的假死,然后StandBy NameNode进行注册,造成脑裂。
规避脑裂
在ZKFC中有实现fencing的点,会在Zookeeper上创建临时节点 hadoop-ha/${dfs.nameservices}/ActiveStandByElectorLock,这个ZooKeeper节点标识着Active的NameNode是当前的值的物理节点。同时还会常见另外一个路径为hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb的持续化节点,标识当前Active节点的物理地址信息等。
当正常退役Active的时候,临时节点随着Session关闭会被自动删除,而持久化的节点在正常退出的时候删除。如果遇到了不正常的时候,那么持久化的节点不会删除,下一个竞选上来的节点,注册了临时节点后,会查看持久化节点的信息并对其进行fencing。
Fencing机制
- sshFence 通过SSH到目标物理机器上,执行命令将其对应的进程杀死。
- 执行用户自定义的shell脚本来进行进程隔离
只有正确的执行完fencing之后,ZKFC中的ActiveStandByElector才会回调ZKFailoverController的becomActive方法将NameNode转换为Active状态,对外进行服务提供。
后记
高可用分为两个部分,1.为数据同步,实现热备。2.热备转正的流程。
后续学习方向为QJM的原理,或者NFS数据同步方式。
以上是关于Hadoop高可用HA原理-全流程讲解的主要内容,如果未能解决你的问题,请参考以下文章