十大常用机器学习算法总结(持续完善)
Posted 二哥不像程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十大常用机器学习算法总结(持续完善)相关的知识,希望对你有一定的参考价值。
前言
之前二哥连载了各类常用的机器学习算法的原理与具体推倒过程,本文我们对常用的十大机器学习算法进行总结。
记得收藏+点赞+评论呦!
目录
一、线性回归
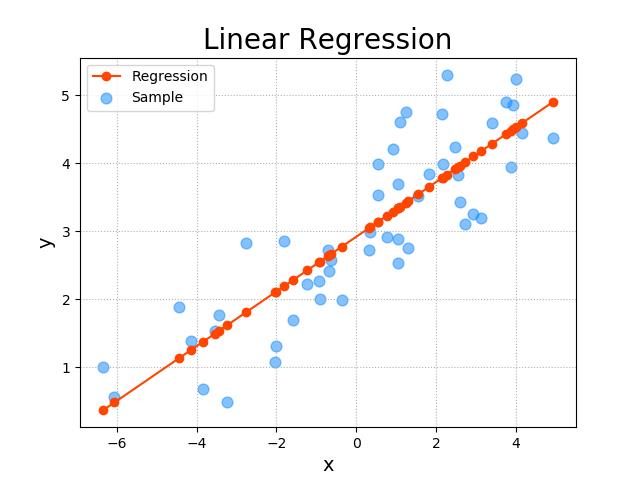
- 思路:线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数w和b。
- 优点:
1.模型简单,容易实现
2.许多非线性模型的基础
3.机器学习的基石
- 缺点:
1.对于非线性数据或者数据特征间具有相关性多项式回归难以建模
2.难以很好地表达高度复杂的数据
- 适用场景:线性回归作为最基础的模型,一般需要一个简单的回归模型的时候,通常使用线性回归,同时线性回归也是很多模型的基石。
二、K近邻算法(KNN)
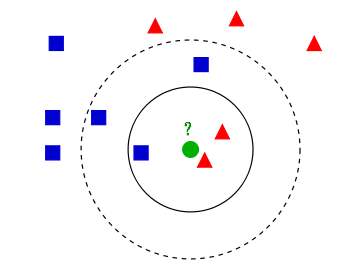
- 思路:对于待判断的点,找到离他最近的几个数据点,根据他们的类型决定待判断点的类型。
- 特点:完全跟着数据走,没有什么数学模型。
- 优点:
1.理论成熟,思想简单;
2.可用于非线性;
3.准确度高;
4.对异常值不敏感。
- 缺点:
1.计算量大;
2.样本不均衡的问题;
3.需要大量的内存。
- 适用场景:需要一个好解释的模型的时候。
三、朴素贝叶斯(NB)
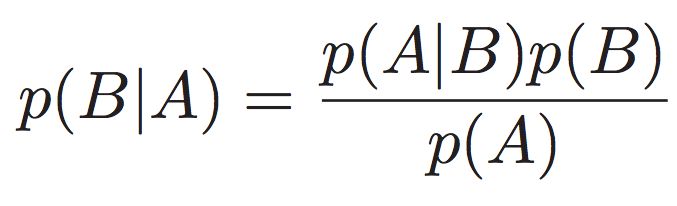
-
条件概率:
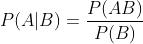
-
全概率:
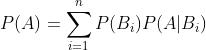
-
贝叶斯公式:

-
优点:
1.朴素贝叶斯起源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率;
2.对小规模的数据表现很好,能进行多分类;
3.对缺失值不敏感,算法简单。
- 缺点:
1.需要计算先验概率;
2.对特征间强相关的模型分类效果不好。
- 适用场景:容易解释,不同维度之间相关性小的模型,不计后果的前提下可以处理高维数据。
四、逻辑回归(LR)
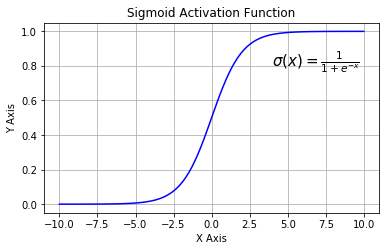
-
核心:

- 优点:
1.实现简单,广泛应用于工业上;
2.分类时计算量非常小,速度很快,存储资源少;
3.可观测样本的概率分数。
- 缺点:
1.特征空间很大时,性能不是很好;
2.容易前拟合,一般准确度不高;
3.只能处理二分类线性可分问题。
- 适用场景:很多分类算法的基础组件;用于分析单一因素对某一事件发生的影响因素;用于预测事件发生的概率。
五、支持向量机(SVM)
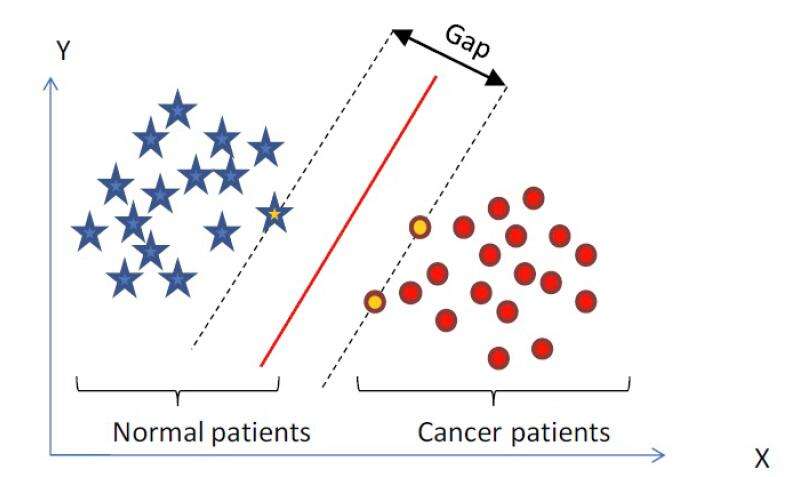
- 核心:找到不同类别之间的分类面,使得两类样本尽量落在面的两边,且离分类面尽量远。
- 优点:
1.可以解决高维问题,即大型特征空间;
2.能够处理非线性特征的相互作用;
3.无需依赖整个数据。
- 缺点:
1.当观测样本很多的时候,效率不是很高;
2.对非线性问题没有通用的解决方案,很难找到一个合适的核函数;
3.对缺失数据敏感。
- 适用场景:在很多数据集上都有优秀的表现,拿到数据就可以尝试一下SVM(高维数据注意核函数的选择)。
六、决策树(DT)
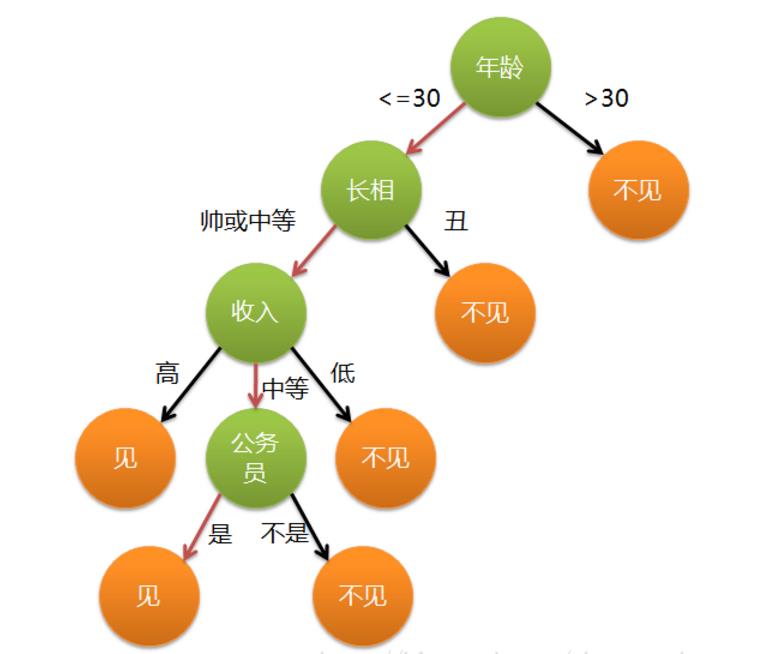
- 核心:信息增益;信息增益比;Gini系数。
- 优点:
1.计算简单,易于理解,可解释行强;
2.比较适合有缺失属性的样本;
3.能够处理不相关的特征;
4.在短时间内可以对大型数据做出好的结果。
- 缺点:
1.容易发生过拟合;
2.易被攻击;
3.忽略了数据之间的相关性;
4.各个类别样本数量不一致的数据,信息增益偏向具有更多数值的特征。
- 适用场景:常作为一些算法的基石;它能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
七、随机森林(RF)
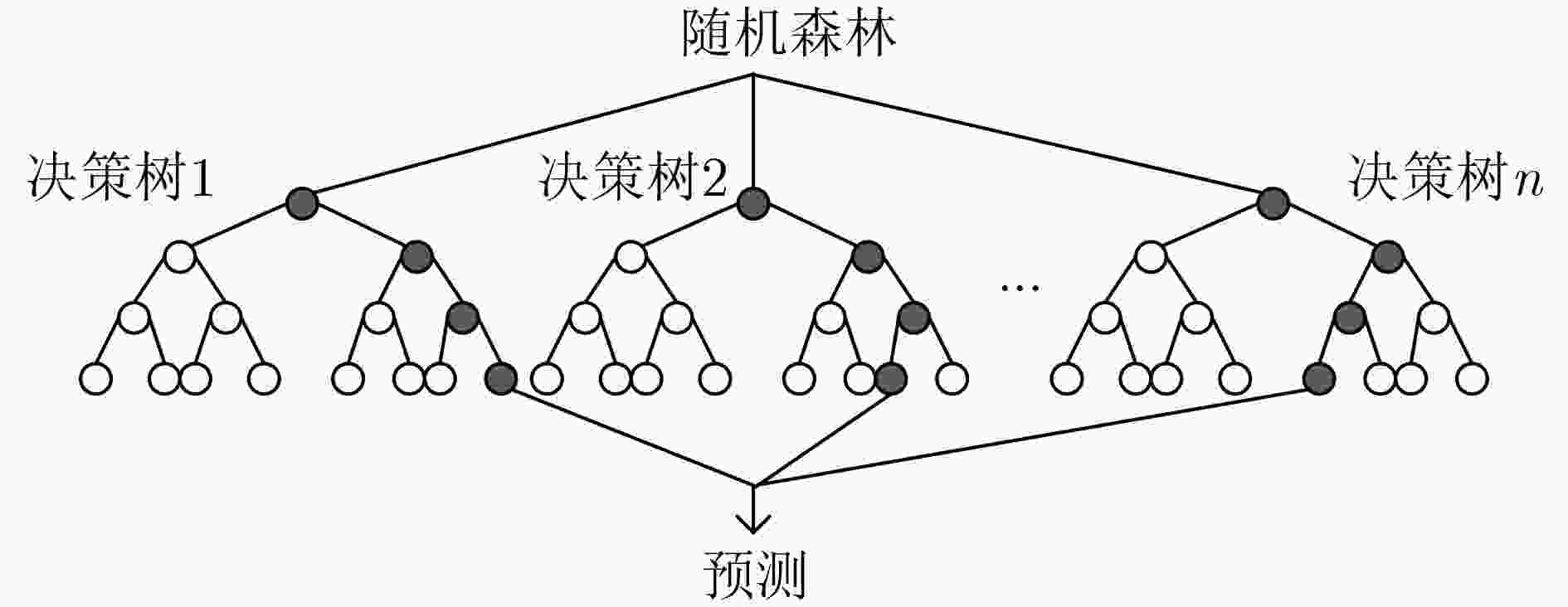
- 核心:两个随机(随机选取训练样本,随机选取特征),由决策树形成。
- 优点:
1.可以解决分类和回归问题;
2.抗过拟合能力强;
3.稳定性强。
- 缺点:
1.模型复杂;
2.计算成本高;
3.计算时间长。
- 适用场景:数据维度相对低(几十维),同时对准确性有较高的要求;使用随机森林时,不需要调节很多的参数就可以达到很好的效果,所以不知道用什么方法时可以尝试一下。
八、GBDT
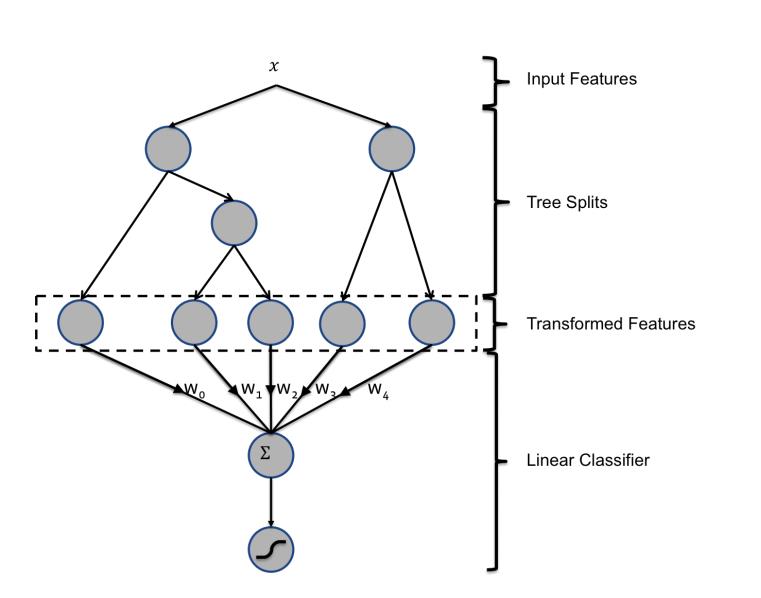
- 原理:计算树的伪残差,通过前一棵树的残差拟合下一棵树,最终进行残差的加和。
- 优点:
1.预测精度高;
2.适合低维数据;
3.能处理非线性数据;
4.可以灵活处理各种类型的数据,包括连续值和离散值;
5.在相对少的调参时间情况下,预测的准备率也可以比较高。
- 缺点:
1.由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行;
2.如果数据维度较高时会加大算法的计算复杂度。
- 适用场景:不知道用什么模型时候可以使用的回归/分类模型
九、XGBoost
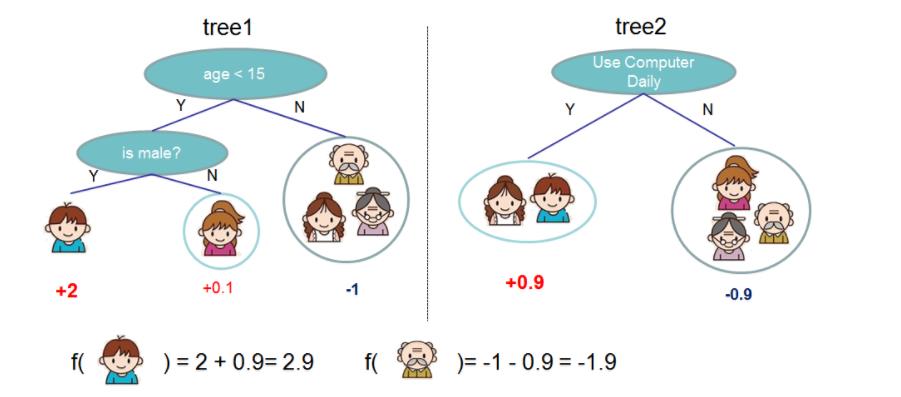
- 原理:通过计算伪残差,计算加和(同GBDT)。
- 对比GBDT的改进(优点继承):
1.传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑回归(分类问题)或者线性回归(回归问题)。
2.传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数(能自定义损失函数)。
3.gboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。正则项降低了模型的复杂度,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- 适用场景:各种比赛的大杀器,不知道用什么模型时候可以使用的回归/分类模型
十、K-Means
- 原理:物以类聚,人以群分
- 优点:
1. 原理简单,容易实现
2. 内存占用小
- 缺点:
1. K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的,对于像计算全部微信用 户的交往圈这样的场景就完全的没办法用K-Means进行。
2. K-Means算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同(K-Means++)。
3. K均值算法并不适合所有的数据类型。
4. 对离群点的数据进行聚类时,K均值也有问题,这种情况下,离群点检测和删除有很大的帮助。
- 适用场景:没有明确标签的情况下,我们经常用聚类模型来进行操作。
以上是关于十大常用机器学习算法总结(持续完善)的主要内容,如果未能解决你的问题,请参考以下文章