Java 集合深入理解 (十三) :ArrayDeque实现原理研究,及动态扩容双端队列和单队列和栈比较
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合深入理解 (十三) :ArrayDeque实现原理研究,及动态扩容双端队列和单队列和栈比较相关的知识,希望对你有一定的参考价值。
ArrayDeque、stack、linkedlist特性及为什么要推荐arraydeque实现栈
前言
ArrayDeque(数组实现的双端队列),是jdk推荐用来作栈使用,替代掉stack,底层仍是数组实现,实现是循环数组,这一特性区别开vector和linkedlist 因此被推荐作为栈使用 ;开发者是Josh Bloch 和Doug Lea,不用想一旦是doug lea写的源码,肯定有研究的价值;特别是并发包及hashmap,确实用不少好的算法学习,让我们慢慢来研究一下整个源码把。
应用实例
public static void main(String[] args) {
System.out.println("--------------ArrayDeque--------------");
ArrayDeque<String> ad=new ArrayDeque<String>();
ad.push("1");
ad.push("2");
ad.push("3");
ad.push("4");
ad.push("5");
ad.push("6");
ad.stream().forEach(e->{
System.out.println(e);
});
System.out.println("----------poll-----------");
System.out.println(ad.poll());
System.out.println(ad.poll());
System.out.println(ad.poll());
System.out.println(ad.poll());
System.out.println(ad.poll());
System.out.println(ad.poll());
System.out.println("----------offer-----------");
ArrayDeque<String> ads=new ArrayDeque<String>();
ads.offer("1");
ads.offer("2");
ads.offer("3");
ads.offer("4");
ads.offer("5");
ads.offer("6");
ads.stream().forEach(e->{
System.out.println(e);
});
}
//打印
--------------ArrayDeque push--------------
6
5
4
3
2
1
----------poll-----------
6
5
4
3
2
1
----------offer-----------
1
2
3
4
5
6
从上面示例进行看
- 第一次使用栈的push进行 添加数据,在使用 迭代器和 poll的数据是一样的,关键点在于,迭代器是用head指针往后遍历并返回数据,而 对于 poll也是取head的数据 也就是 (pollFirst)
- offer 进元素时,是offerLast ,这样迭代器去遍历数据时,看起来和添加数据时顺序一致了
ArrayDeque、stack、linkedlist
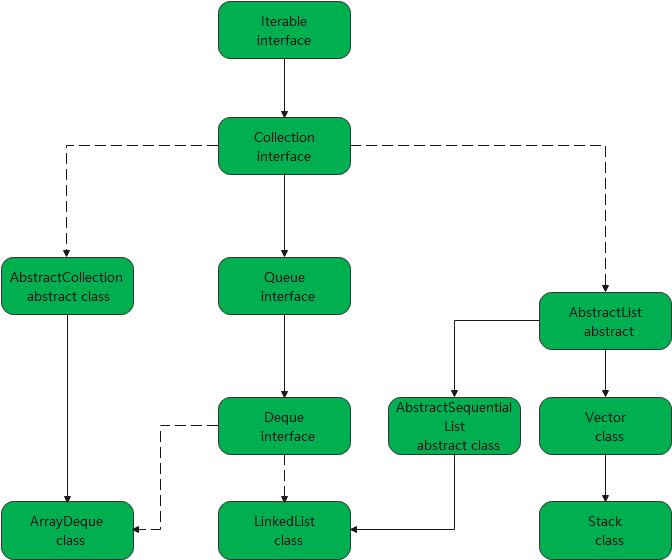
从上面的图可以看出三个类有很大的关系
Stack实现了Vector接口,LinkKist实现了Deque,List接口,ArrayDeque实现了Deque接口
ArrayDeque、stack、linkedlist特性及为什么要推荐arraydeque实现栈
ArrayDeque
- 循环数组
- 不支持null元素
- 无法确定数据量时,扩容会影响其添加速率
- 线程不安全
- 这个数组没有固定的开头或结尾,在头部插入数据,不需要大面积地移动数据。说明其性能很优秀的
stack
- 线性数组结构
- 支持添加空元素
- 无法确定数据量时,扩容会影响其添加速率
- 线程安全 使用synchronized关键字
- 完全依赖vector ,实现比较粗糙,
linkedlist
- 链表结构
- 支持添加空元素
- 不涉及扩容,原则上jvm堆内存没有满,就可以放多少元素
- 非连续的空间 ,随机访问效率低,访问时候不能充分利用cpu cache,每次插入节点 和删除节点 是很浪费内存的 ,内部节点都可以
LinkedList进行垃圾收集,这在幕后需要做更多工作。此外,由于链表节点被分配在这里和那里,CPU 缓存的使用不会提供太多好处。
为什么要推荐arraydeque实现栈
从上面的特性可知首先排除linkedlist实现栈
链表结构的特性;非连续的空间 ,随机访问效率低,访问时候不能充分利用cpu cache,每次插入节点 和删除节点 很浪费内存
在从ArrayDeque 和stack 中选择,jdk推荐使用arraydeque
虽然ArrayDeque不是线程安全的(而stack实现的线程安全直接用synchronized关键字),但并不影响它被推荐 首先arraydeque 是1.6实现的,循环数组,相对于传统的线性数组来说有自己的优势,虽然栈感觉用不到,其次 jdk实现线程的方式推荐的也是使用Collections.synchronizedList进行封装一次,频繁的随机访问操作数据比线性结构好;如果想用线性数组实现栈,我感觉直接用arraylist来实现也挺好的。
arraydeque实现原理

从上面的来看整个Doug Lea写的arraydeque设计的核心思想
循环数组在概念上没有左右边界,但是Java并没有这样的数组,Java只能提供固定大小的数组,但是可以通过算法让固定数组感觉运用的时候不固定,这里面使用了位运算操作,看起来并不直观,但并不妨碍我们去理解它;
全篇注释
/**
*{@link Deque}接口的可调整大小的数组实现。数组deques没有容量限制;它们会根据需要生长以支持
*用法。它们不是线程安全的;在没有外部同步,它们不支持多线程并发访问。
*禁止使用空元素。当该类替代{@link Stack}用作堆栈时,比{@link LinkedList}快
*当用作队列时。
*<p>大多数{@code ArrayDeque}操作都是在固定时间内运行的。例外情况包括{@link#remove(Object)remove}、{@link
*#removeFirstOccurrence removeFirstOccurrence},{@link#removeLastOccurrence
*removeLastOccurrence},{@link#contains},{@link#iteratoriterator.remove()}和批量操作,所有这些操作都以线性方式运行
*时间。
*<p>这个类的{@code iterator}方法返回的迭代器是<i>快速失败</i>:如果在迭代器之后的任何时间修改了deque
*以任何方式创建,除了通过迭代器自己的{@code remove}方法,迭代器通常会抛出一个{@link
*ConcurrentModificationException}。因此,面对修改后,迭代器会快速而干净地失败,而不是冒着
*在一个不确定的时间里的任意的,不确定的行为未来。
*<p>请注意,不能保证迭代器的快速失败行为一般说来,不可能在未来作出任何硬性保证
*存在未同步的并发修改。失败快速迭代器尽最大努力抛出{@code ConcurrentModificationException}。
*因此,编写依赖于此的程序是错误的
*其正确性例外:<i>迭代器的快速失败行为应仅用于检测错误。</i>
*<p>这个类及其迭代器实现了<em>可选的{@link集合}和{@link集合的方法迭代器}接口。
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @author Josh Bloch
* @see List
* @see ArrayList
* @since 1.2
* @param <E> the type of elements held in this collection
*/注释解析
- 该类是可调整大小的数组实现,并没有容量限制,也就是int的最大值
- 它们不是线程安全的;在没有外部同步,它们不支持多线程并发访问。采用快速失败机制保证数据安全
- 当该类替代{@link Stack}用作堆栈时,比{@link LinkedList}快
- 大多数{@code ArrayDeque}操作都是在固定时间内运行的,并且是线性事件操作的
成员属性解析
elements属性
/**
*存储数据块元素的数组。deque的容量是这个数组的长度,即总是二的幂。不允许数组变为已满,除了在addX方法中临时
*满负荷后立即调整大小(见doubleCapacity),这样就避免了头部和尾部缠绕在一起,使彼此相等其他。我们还保证所有数组单元
*deque元素总是空的。
*/
transient Object[] elements; // 非私有以简化嵌套类访问- 首先非私有以简化嵌套类访问这个关键字是为了优化 数据传输时,序列化,保证空间的合理利用,具体的我这里不详细说,在之前的arraylist等集合中详细分解过
Java 集合深入理解 (一):基于数组实现的集合( ArrayList)
- 数据数组(elements)我最开始有这个疑问在于,hashmap 容量采用2的幂,是降低hash碰撞,使元素均匀的分布,从而加快访问效率等;但为什么arraydeque也要是二的幂,这个不是太清楚,我搜了下网上说是允许环回 elements的容量,位操作,加快效率,我从下面的源码分析出,还是位运算,如果没有容量为2的幂次方,肯定没有之后的 添加数据位运算,这么简单就达成的
成员属性head tail 属性
/**
*deque头部元素的索引(即将由remove()或pop()删除的元素;或者一个如果deque为空,则等于tail 的任意数。
*/
transient int head;
/**
*将下一个元素添加到尾部的索引(通过addLast(E)、add(E)或push(E))。
*/
transient int tail;
/**
* 我们将用于新创建的deque的最小容量。必须是2的幂。
*/
private static final int MIN_INITIAL_CAPACITY = 8;- 从head 和tail属性解释 能看出 任何元素的操作,都是通过 两个指针进行操作, 并做判断的
- 我们会有个最小容量,当设置的容量小于这个值时,都会取这个值
构造方法
无参构造方法
/**
*构造一个具有初始容量的空数组deque足够容纳16个元素。
*/
public ArrayDeque() {
elements = new Object[16];
}初始化默认容量就是16,和我们的arraylist的10 vector 的10 还有PriorityQueue 的11都还是不太一样的,这个得取值还是和 hashmap一致得
有参构造方法
/**
*构造一个具有初始容量的空数组deque足够容纳指定数量的元素。
*@param numElements deque初始容量下限
*/
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
还有个 构建时添加集合得方法,这个方法调用得addall进行添加数据。然后这里的 主要还是调用allocateElements 进行调整容量为2的幂次方,这就很想hashmap了
数组分配和调整大小实用程序(公共重要的算法)
allocateElements方法(分配空数组以容纳给定数量的元素)
/**
* 分配空数组以容纳给定数量的元素
*
* @param 计算要保存的元素数
*/
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// 找出两个元素的最佳幂来容纳元素。
// 测试“<=”,因为数组没有保持满。
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // 太多的元素,必须后退
initialCapacity >>>= 1;// 好运分配2^30个元素
}
elements = new Object[initialCapacity];
}- 首先当给定容量 小于默认容量为8直接new 一个给定值的数组
- 如果当容量大于初始值时,这个时候就要做 右移位操作了
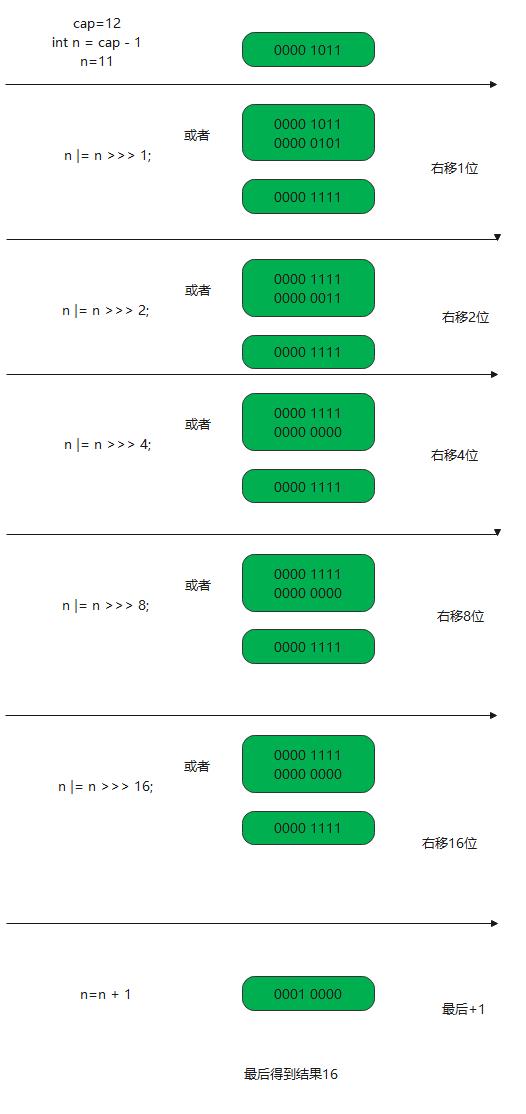
这个和hashmap中容量校对的一样,不断右移位进行或运算,一直右移到16位进行运算的原因都是为了取到最近的 2的整数次幂的值,在这里 容量为12,在右移两位时,已经计算出最近的 2的整数次幂 后面的不需要了,在继续移动16位进行对比的原因,也是判断容量的大小,并且最后对容量做了个校验
doubleCapacity方法(扩容核心方法)
/**
*使这个数组的容量增加一倍。只有满了才扩容,即当头部和尾部指针缠绕在一起变得相等时。
*/
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // 右侧的元素数
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
//Object src : 原数组 int srcPos : 从元数据的起始位置开始 Object dest : 目标数组
//int destPos : 目标数组的开始起始位置 int length : 要copy的数组的长度
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}assert关键字 的含义:assert <boolean表达式>

/**
*将元素从元素数组复制到指定的数组中,顺序(从deque中的第一个元素到最后一个元素)。这是假定的数组的大小足以容纳deque中的所有元素。
*@返回参数
*/
private <T> T[] copyElements(T[] a) {
if (head < tail) {
System.arraycopy(elements, head, a, 0, size());
} else if (head > tail) {
int headPortionLen = elements.length - head;
System.arraycopy(elements, head, a, 0, headPortionLen);
System.arraycopy(elements, 0, a, headPortionLen, tail);
}
return a;
}这里的分为两种 ,
- 当 head < tail 时,从上面的扩容我们就能看的出来,我们直接从 head截取到 tail给新数组就可以
- 其次 如果当 head 大于tail 我们则要采用 分段进行复制了 复制后半截,和前半截
双端队列和单队列 和栈比较
双端队列 :两端都可进出 具体方法
| 头部操作 | 尾部操作 | |||
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 删除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
Queue 接口:一端进另一端出
| Queue方法 |
| add add(e) |
| offer(e) |
| remove() |
| poll() |
| element() |
| peek() |
堆栈方法:一端操作先进先出
| 堆栈方法 |
| push(e) |
| pop() |
| peek() |
addLast,pollFirst,pollLast 主要的插入和提取方法
实现栈的 push 和pop 和peek方法
- addFirst 方法是 push 核心方法
- removeFirst 方法 是pop 的核心方法
addFirst方法
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}关键点在 elements[head = (head - 1) & (elements.length - 1)] = e; 方法 该方法进行 给头节点进行复制,
- 当head-1为-1时,实际上是11111111&00001111,结果是00001111,也就是物理数组的尾部15;
- 当head-1为较小的值如4时,实际上是00000100&00001111,结果是00000100,还是4。
- 当head增长如head+1超过物理数组长度如16时,实际上是00010000&00001111,结果是00000000,也就是0,这样就回到了物理数组的头部。
所以,位与运算可以很轻松地实现把数据控制在某个范围内。我感觉为什么要在容量控制在2的幂次方这应该也算很大的原因 (这个和使用Math.min 或者 Math.max 一对比感觉高大上了)

同理 addLast 方法也是用了位运算去操作
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
pollFirst方法 取出 头数据
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // 必须清空插槽
head = (h + 1) & (elements.length - 1);
return result;
}关键点也在 head = (h + 1) & (elements.length - 1); 这个位运算和添加头元素很像,只是往上走一位
其他的add方法等都基于该方法进行处理的,其他的无非是多了一次抛异常等
下降迭代器
自己实现了一个 DescendingIterator 迭代器(下降迭代器)
private class DescendingIterator implements Iterator<E> {
/*
*这个类几乎是DeqIterator的镜像,使用对于初始光标,尾部代替头部,头部代替头部用尾巴做栅栏。
*/
private int cursor = tail;
private int fence = head;
private int lastRet = -1;
public boolean hasNext() {
return cursor != fence;
}
public E next() {
if (cursor == fence)
throw new NoSuchElementException();
cursor = (cursor - 1) & (elements.length - 1);// tail是下个添加元素的位置,所以要减1才是尾节点的索引。
@SuppressWarnings("unchecked")
E result = (E) elements[cursor];
if (head != fence || result == null)
throw new ConcurrentModificationException();
lastRet = cursor;
return result;
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
if (!delete(lastRet)) {// 如果从左往右移,需要将游标加1。
cursor = (cursor + 1) & (elements.length - 1);
fence = head;
}
lastRet = -1;
}
}

整个迭代器
- 会用head 去检测 ,快速失败
- lastRet 防止多次删除数据
- cursor = (cursor - 1) & (elements.length - 1); 规整每次迭代的数据
总结
整个篇代码进行分析, Doug Lea 写的代码用位运算来做数据间操作,是相当精妙的,包括保证容量为2的幂次方,并且扩容机制等等,代码很少,但效果很好,非常值得我们深入研究,以及对于空元素会直接抛异常等等
以上是关于Java 集合深入理解 (十三) :ArrayDeque实现原理研究,及动态扩容双端队列和单队列和栈比较的主要内容,如果未能解决你的问题,请参考以下文章