Java 集合深入理解 (十五) :HashSet实现原理研究
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合深入理解 (十五) :HashSet实现原理研究相关的知识,希望对你有一定的参考价值。
前言
set集合:具体体现在不可重复的性质,该集合的特点在于:不会存储重复的元素,存储无序(存入和取出的顺序不一定相同)元素
hashset:是set的经典实现类,底层利用散列表的key值不能重复而实现,hashset具有下面的特性
- 可以存储空的数据
- 不能保证数据插入,和取出顺序是一致的
- 该集合是不同步的
实例
public static void main(String[] args) {
HashSet hs=new HashSet<>();
hs.add("c");
hs.add("a");
hs.add("d");
hs.add(null);
hs.stream().forEach(e->{
System.out.println(e);
});
}
//输出数据
null
a
c
d
- 从上面个例子是允许插入数据为空的
- 其次明显插入数据 和取出数据不一致,按照hash值往后得(没有hash碰撞)
- 在使用得时候,他没有实现get方法,在插入过后获取要么转换成 数组,或者使用迭代器进行迭代取出数据,不方便使用
实现原理
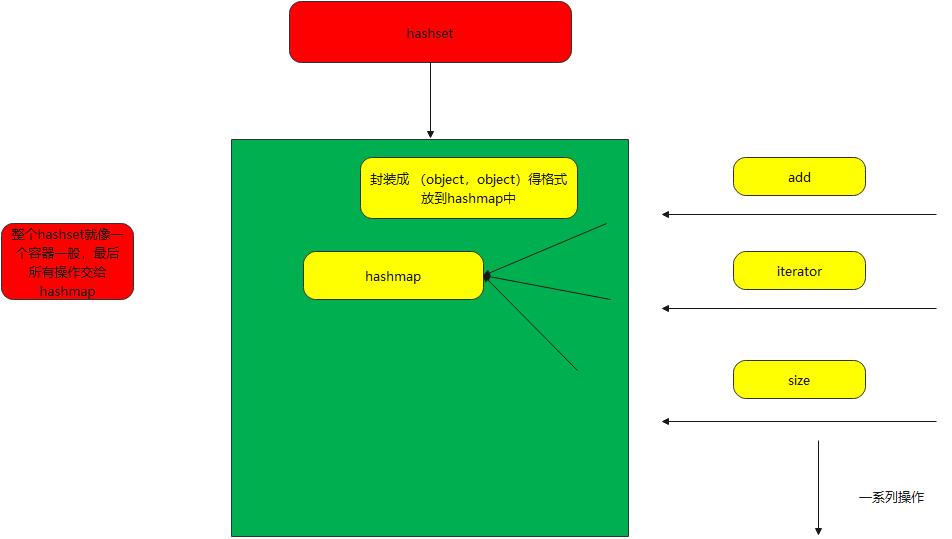
整个hashset就像一个容器一般把hashmap得操作操作做了一个封装,实际操作得是hashmap
整篇注释
/**
*这个类实现了<tt>Set</tt>接口,由一个哈希表支持(实际上是一个<tt>HashMap</tt>实例)。它不保证*集合的迭代次序;特别是,它不能保证
*随着时间的推移,秩序将保持不变。这个类允许<tt>null</tt>元素。
*<p>该类为基本操作提供恒定时间性能(<tt>添加</tt>、<tt>删除</tt>、<tt>包含</tt>和<tt>大小</tt>),*假设哈希函数将元素正确地分散在
*水桶。迭代这个集合需要的时间与<tt>哈希集</tt>实例的大小(元素数)加上backing<tt>HashMap</tt>实例的“容量”(桶)。因此,不设置初始容量非常重要
*如果迭代性能很重要,则为高(或负载系数太低)。<p><strong>请注意,此实现不同步。</strong>如果多个线程同时访问哈希集,则线程修改集合,它必须在外部同步。这通常是通过在某个自然地封装了集合。
*
*如果不存在这样的对象,则应使用{@link Collections#synchronizedSet Collections.synchronizedSet}方法。这最好在创建时完成,以防止意外对集合的非同步访问:<pre>Set s=Collections.synchronizedSet(新HashSet(…))</预处理>
*
*<p>这个类的<tt>迭代器<tt>方法返回的迭代器是<i>快速失败</i>:如果在迭代器运行后的任何时间修改集合以任何方式创建,除了通过迭代器自己的<tt>remove</tt>
*方法,迭代器抛出一个{@link ConcurrentModificationException}。因此,面对并发修改,迭代器很快就会失败而不是冒着武断的、不确定的行为的风险未来不确定的时刻。
*<p>请注意,不能保证迭代器的快速失败行为一般说来,不可能在未来作出任何硬性保证存在未同步的并发修改。失败快速迭代器尽最大努力抛出ConcurrentModificationException。
*因此,编写依赖于此的程序是错误的其正确性例外:<i>迭代器的快速失败行为应仅用于检测错误。</i>
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <E> the type of elements maintained by this set
*
* @author Josh Bloch
* @author Neal Gafter
* @see Collection
* @see Set
* @see TreeSet
* @see HashMap
* @since 1.2
*/整篇注释得理解
- 这个类实现了<tt>Set</tt>接口,由一个哈希表支持(实际上是一个<tt>HashMap</tt>实例),不能保证秩序将保持不变,并且允许为空得元素
- 哈希函数将元素正确地分散在 数组(桶里面) ,该类为基本操作提供恒定时间性能 ,初始容量非常重要 这是hashmap里面强调得一点
- 此实现不同步 ,需要在外面加同步,推荐得是Collections.synchronizedSet
- 迭代器中会有快速失败 保证数据得安全
成员属性
主要是两个成员属性
private transient HashMap<E,Object> map;
// 与背景图中的对象关联的虚拟值
private static final Object PRESENT = new Object();- 首先 需要持有得hashmap对象,然后进行各种操作
- 以及 hashmap中得value值 默认就是一个空得对象
构造函数
无参构造
给我们提供了一个默认容量 及负载因子得hashmap
public HashSet() {
map = new HashMap<>();
}有参构造
在注释得时候,也建议我们根据实际使用情况,进行设定容量
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}这里有个疑惑得地方,就是 他里面有个 可以创建LinkedHashMap 得类,可以记录上数据得插入顺序,但是又不是公共得方法,我们不能使用,这个可能是提供给内部使用得把,但又没实现获取顺序得方法,最后发现 linkedhashset中使用。
add remove方法
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
这里得add remove 方法,我相信大家都明白,如果需要深究,那可以看一下下面一篇文章
Java 集合深入理解 (十一) :HashMap之实现原理及hash碰撞
总结
整个hashset得实现是非常简单得,基本所有操作都在hashmap中实现,整个数据存储得关键点也在 hashmap中,至于 提供构造方法创建LinkedHashMap 是在LinkedHashSet中使用,来创建具有插入顺序的Set,具体我就不分析了,因为从整个源代码来看,很简单,我就不分析了
以上是关于Java 集合深入理解 (十五) :HashSet实现原理研究的主要内容,如果未能解决你的问题,请参考以下文章