Java 集合深入理解 (十六) :LinkedHashMap 实现原理深入 以及推荐使用建立lru缓存
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合深入理解 (十六) :LinkedHashMap 实现原理深入 以及推荐使用建立lru缓存相关的知识,希望对你有一定的参考价值。
目录
newTreeNode 和replacementTreeNode方法
前言
LinkedHashMap 是hashmap和双向链表结合的一种数据结构,用于记录插入顺序,并在迭代器进行取出数据时顺序和插入数据相同;LinkedHashMap可以很好的支持LRU算法
实现示例
LinkedHashMap map=new LinkedHashMap();
map.put("1", "1");
map.put("6", "6");
map.put("3", "3");
map.put("7", "7");
map.put("2", "2");
map.keySet().stream().forEach(m->{
System.out.println(map.get(m));
});
System.out.println("--------------hashmap--------------");
HashMap maps=new HashMap();
maps.put("1", "1");
maps.put("6", "6");
maps.put("3", "3");
maps.put("7", "7");
maps.put("2", "2");
maps.keySet().stream().forEach(m->{
System.out.println(map.get(m));
});
//打印值
1
6
3
7
2
--------------hashmap--------------
1
2
3
6
7从上面的示例 明显就能看出hashmap和 LinkedHashMap 的区别在于
- LinkedHashMap 取出的顺序和插入顺序是一致的
- hashmap则是按照hashcode 进行存储 ,在没有hash碰撞的情况下,看起来就是数组存储,链条式顺序存储的
实现原理分析
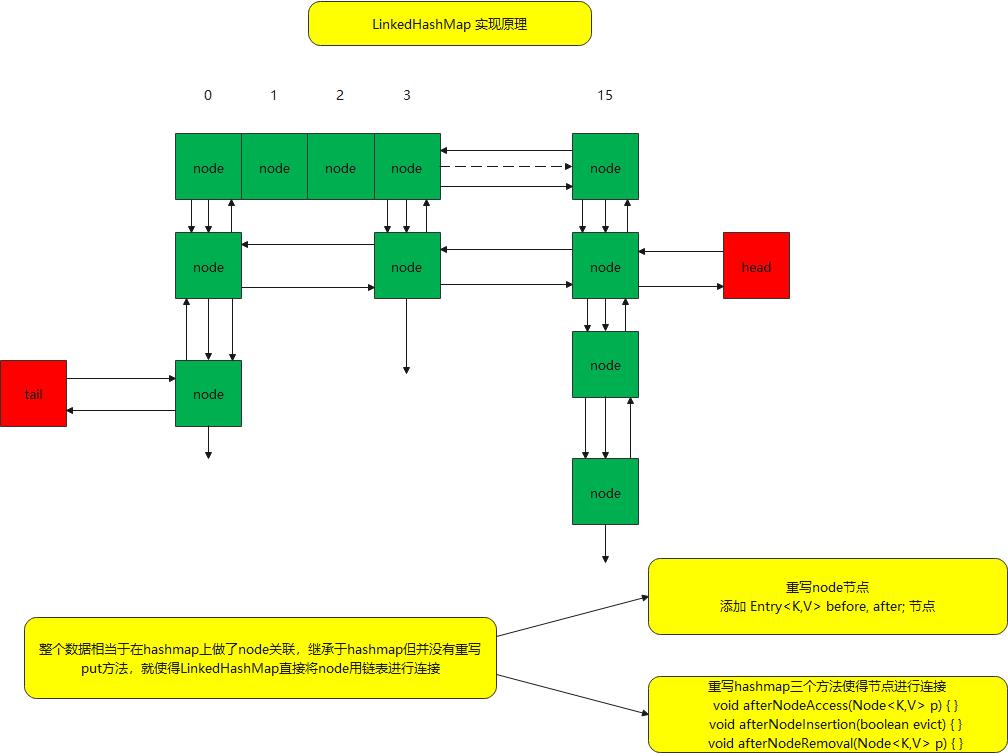
整个LinkedHashMap能实现更加高效得益于 hashmap中提前留给linkedhashmap重写几个关键方法,提高了扩展性
- 在添加数据 重写了afterNodeAccess方法将每个节点进行封装 ,后面会重点讲解这几个方法
- LinkedHashMap对hashmap进行扩展,保留了hashmap的所有操作,以及所有的优化的点,又增加了链表来记录插入顺序
- LinkedHashMap可以很好的支持LRU算法
源码解析
全篇注释
/**
*<p>映射接口的哈希表和链表实现,具有可预测的迭代顺序。此实现不同于<tt>HashMap</tt>因为它维护了一个贯穿它的所有条目。这个链表定义了迭代顺序,
*这通常是钥匙插入地图的顺序(<i>插入顺序</i>)。请注意,插入顺序不受影响如果一个键被重新插入地图(一个键<tt>k</tt>是
*如果<tt>m,则重新插入map<tt>m<tt>m.containsKey(k)</tt>将在紧接着调用。)
*
*<p>此实现通常使其客户机免受未指定的{@link HashMap}(和{@link Hashtable})提供的混沌排序,而不会增加与{@linktreemap}相关的成本。它
*可用于生成与原始的,不管原始地图的实现是什么:
* <pre>
* void foo(Map m) {
* Map copy = new LinkedHashMap(m);
* ...
* }
* </pre>
*如果模块在输入时获取映射,则此技术特别有用,复制它,然后返回结果,其顺序由复印件(客户通常都喜欢同样的东西被退回他们被呈现的顺序。)
*
*<p>一个特殊的{@link#LinkedHashMap(int,float,boolean)构造函数}是用于创建一个链接的哈希映射,其迭代顺序为
*最后一次访问它的条目的位置,从最近最少访问到最近(<i>访问顺序</i>)。这种地图很适合于
*建立LRU缓存。调用{@code put},{@code putIfAbsent},{@code get},{@code getOrDefault},{@code compute},{@code computeifastent},
*{@code computeIfPresent},或{@code merge}方法结果
*在对相应条目的访问中(假设它在调用完成)。{@code replace}方法只会导致如果值被替换,则为条目的。{@code putAll}方法生成一个
*指定映射中每个映射的条目访问权限,按键值映射由指定映射的入口集迭代器提供。<i>没有其他方法生成条目访问。</i>尤其是操作
*在集合视图上,不影响背景图。
*
*<p>可以将{@link#removeEldestEntry(Map.Entry)}方法重写为强制一个策略,以便在创建新映射时自动删除过时的映射添加到地图中。
*
*<p>此类提供所有可选的<tt>映射操作,以及允许空元素。像HashMap一样,它提供了常量时间基本操作的性能(<tt>添加</tt>,<tt>包含</tt>和
*<tt>remove</tt>),假设哈希函数分散元素在水桶之间。业绩可能只是略有下降低于<tt>HashMap</tt>,因为维护链表,只有一个例外:集合视图上的迭代
*一个<tt>LinkedHashMap</tt>需要与<i>大小成比例的时间不管它的容量有多大。在HashMap上迭代很可能会更贵,需要的时间与成本成比例<i>容量</i>。
*
*<p>链接哈希映射有两个影响其性能的参数:<i>初始容量</i>和<i>负载系数</i>。它们的定义很精确
*至于HashMap。但是,请注意,选择初始容量的过高值对于此类不太严重
*而不是HashMap,因为这个类的迭代时间不受影响按容量。
*
*<p><strong>请注意,此实现不同步。</strong>如果多个线程同时访问链接的哈希映射,并且至少其中一个线程从结构上修改映射,它必须
*外部同步。这通常是通过在自然封装地图的某个对象上进行同步。
*
*如果不存在这样的对象,则应该使用{@link Collections#synchronizedMap Collections.synchronizedMap}方法。这最好在创建时完成,以防止意外对地图的非同步访问:<pre>
* Map m = Collections.synchronizedMap(new LinkedHashMap(...));</pre>
*结构修改是添加或删除一个或多个映射,或者在访问有序链接哈希映射的情况下,影响迭代顺序。在插入有序的链接哈希映射中,只需更改
*与已包含在映射中的键关联的值无效结构上的修改<strong>在访问有序链接哈希映射中,仅仅用<tt>get</tt>查询map是一种结构修改。
*<p>集合的<tt>迭代器<tt>方法返回的迭代器所有此类的集合视图方法返回的<em>快速失败</em>:如果映射在
*迭代器是以任何方式创建的,除了通过迭代器自己的方法,迭代器将抛出一个{@linkConcurrentModificationException}。因此,面对
*修改后,迭代器会快速而干净地失败,而不是冒着在未来不确定的时间里任意的、不确定的行为。
*
*<p>请注意,不能保证迭代器的快速失败行为一般说来,不可能在未来作出任何硬性保证存在未同步的并发修改。失败快速迭代器
*尽最大努力抛出ConcurrentModificationException。
*因此,编写依赖于此的程序是错误的其正确性例外:<i>迭代器的快速失败行为应仅用于检测错误。</i>
*
*<p>集合的spliterator方法返回的spliterator所有此类的集合视图方法返回的后期绑定,<em>快速失败</em>,并另外报告{@link Spliterator#ORDERED}。
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @implNote
* The spliterators returned by the spliterator method of the collections
* returned by all of this class's collection view methods are created from
* the iterators of the corresponding collections.
*
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
*
* @author Josh Bloch
* @see Object#hashCode()
* @see Collection
* @see Map
* @see HashMap
* @see TreeMap
* @see Hashtable
* @since 1.4
*/整篇注释有点长,主要意思在于下面几点
- 映射接口的哈希表和链表实现,并且这个链表定义了迭代顺序,重新插入,将紧接着调用
- 在构造函数时,传入得map复制到元素中,返回结果顺序就是map得元素决定的
- 迭代顺序为最后一次访问它的条目的位置,从最近最少访问到最近,很适合建立lru缓存。调用 put 方法 putIfAbsent 一些列操作,也是推荐我们使用来创建 缓存,并且他提供了扩展,就是 removeEldestEntry 方法,当这个为true时,自动删除过时得节点
- 这个类供所有可选的映射操作,以及允许空元素。和hashmap一样,其次就是hashmap中有两个因子影响性能参数,不能设置得太高了。
- 此实现不同步,需要在外部进行同步 Collections.synchronizedMap
- 不能保证迭代器的快速失败行为,加入了快速失败机制
成员属性分析
Entry 节点信息
/**
* 普通LinkedHashMap条目的HashMap.Node子类。
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}- LinkedHashMap中的Entry增加了两个指针 before 和after,它们分别用于维护双向链接列表,它们分别用于维护双向链接列表;next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的
- 对hashmap做了扩展处理,并在 hashmap上添加了 前后节点 联调时,这样就看出来是双向的链表。接下来为什么不和hashmap一样 把名字改成node,而还保持着 entry拉,这个原因作者给我们答案
/*
*实现说明。此类的早期版本是内部结构有点不同。因为超类HashMap现在使用树作为它的一些节点,比如类条目现在被视为中间节点类也可以转换成树形。这个的名字
*类LinkedHashMap.Entry在其当前上下文,但无法更改。否则,即使它不会导出到这个包之外,一些现有的源代码
*已知该代码依赖于符号解析角情况removeEldestEntry调用中抑制编译的规则由于用法不明确而导致的错误。所以,我们保留这个名字
*保留未修改的可编译性。
*节点类中的更改还需要使用两个字段(head,tail)而不是指向要维护的头节点的指针双链接的前/后列表。这个班也以前在进入、插入和移除。
*/使用该节点的,以前已经有很多方法使用这个名称做了,如果一旦改动,防止我们使用时有歧义,因此不改动保留着;例如removeEldestEntry 等
head 和 tail 和 accessOrder
/**
* 双链表中的头(老大)。
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 双链表的尾部(最小的)。
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 此链接哈希映射的迭代排序方法:<tt>true</tt>
* 对于访问顺序,<tt>false</tt>对于插入顺序。
*
* @serial
*/
final boolean accessOrder;- 首先 头部和尾部属性 双向链表 ,并且使用transient修饰,序列化时保证数据占用等量的空间
-
accessOrder 解释 如果accessOrder为true的话,则会把访问过的元素放在链表后面,放置顺序是访问的顺序;如果accessOrder为flase的话,则按插入顺序来遍历 也就是说设置 accessorder为true时,就会使得访问过后的数据,放到末尾去,这在缓存中可以结合removeEldestEntry 使用,删除不经常访问的老旧的数据。
构造方法
无参构造方法
public LinkedHashMap() {
super();
accessOrder = false;
}该构造方法,主要设置 accessOrder 也就是访问顺序 设置为false,按插入顺序 进行遍历等;调用 hashmap的无参构造
有参构造
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
/**
* 构造一个空的<tt>LinkedHashMap</tt>实例
* 规定的初始容量、负载系数和订购模式。
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}在有参构造函数中,能设置订购模式的,只有设置好 容量 及 加载因子 和 订购模式的参数才能设置,否则都为 按插入顺序进行获得数据
内部公用方法
linkNodeLast 方法
// 链接在列表末尾
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}这个方法主要用于将节点设置为链表结尾,在newNode 方法中使用
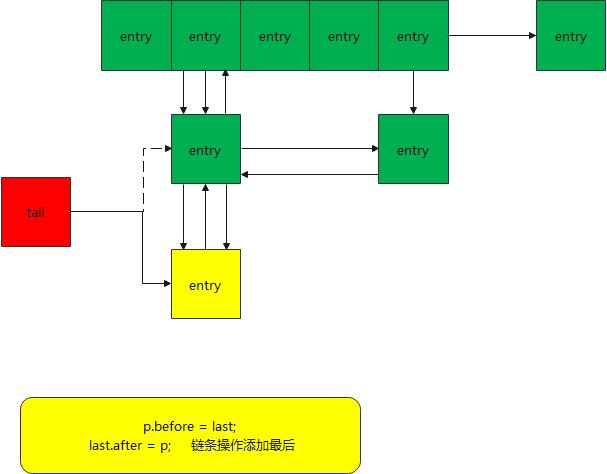
transferLinks方法
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
该方法主要用做将src的链接应用到dst,也就是用节点src 替换成dst节点在双向链表中的位置; 在替换节点 也就是插入相同的元素时,调用 transferLinks 来改变双向链表中的连接关系
- 先将 目标的 前面节点 等于 节点 的 前面节点 并获取到节点; 以及 目标的之后节点等于 src之后的节点
- 将 src替换成目标节点;就将整个节点进行替换掉了
HashMap钩子方法的重写
reinitialize方法
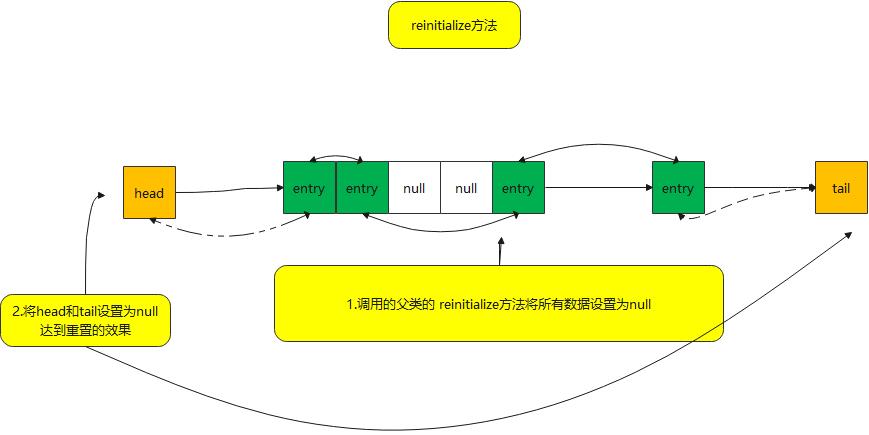
void reinitialize() {
super.reinitialize();
head = tail = null;
}- 该方法主要调用父类的reinitialize方法将数据设置为空
- 将本类中head 和tail 指针都设置为空
- 主要用于 hashmap中clone,readObject方法(该方法是反序列化调用该方法进行返回数据,以达到数据在传输过程中占用过多空间)
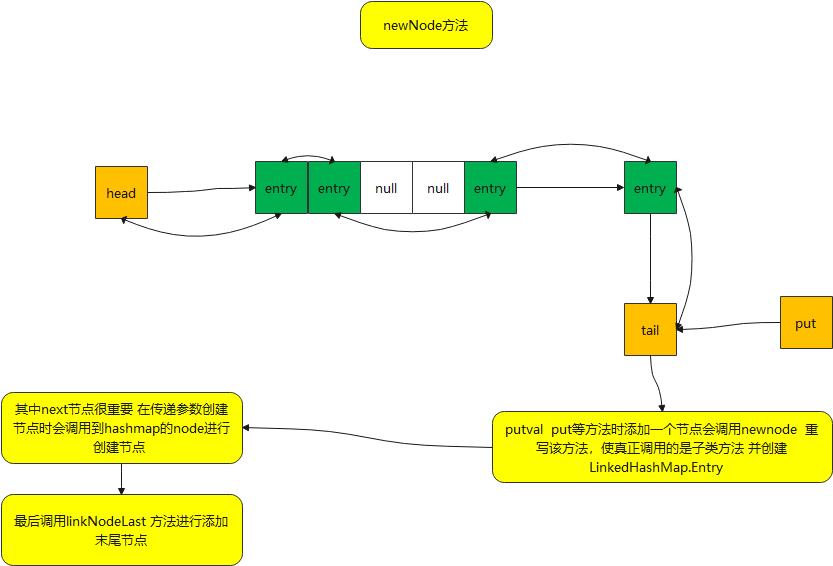
newNode方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}- 该方法从名字来看就是创建一个新节点,用于将节点给联系起来,建立起关系
- 利用重写方法,及参数间传递,和调用父类方法,达到数据关联起来
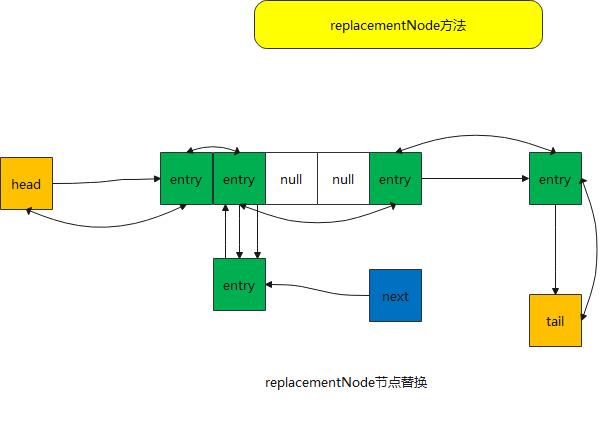
replacementNode方法
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}- 该方法从名字来看就是替换节点,首先转换成 linedhashmap.entry节点 ;整个数据中心的节点都是entry节点而不是node节点
- 将p 节点做一个替换节点,传入 方法中做替换节点 ,原有链条也需要做一个替换
newTreeNode 和replacementTreeNode方法
- 这两个方法是用作对树节点的操作
- TreeNode 节点是继承LinkedHashMap.Entry 因此可以公用的
- 方法内容和上面节点一致,不做另外解析
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
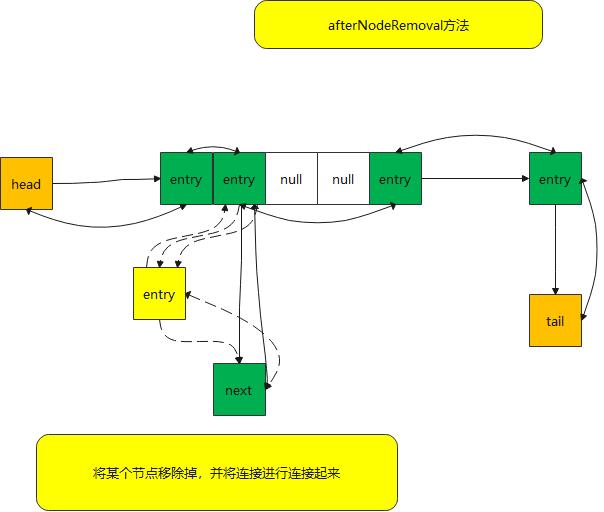
}afterNodeRemoval方法
取消链接方法 ,主要是在hashmap的remove 节点时,被调用;
- 在hashamp中将原有节点移除
- 调用到afterNodeRemoval方法进行链表移除节点
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
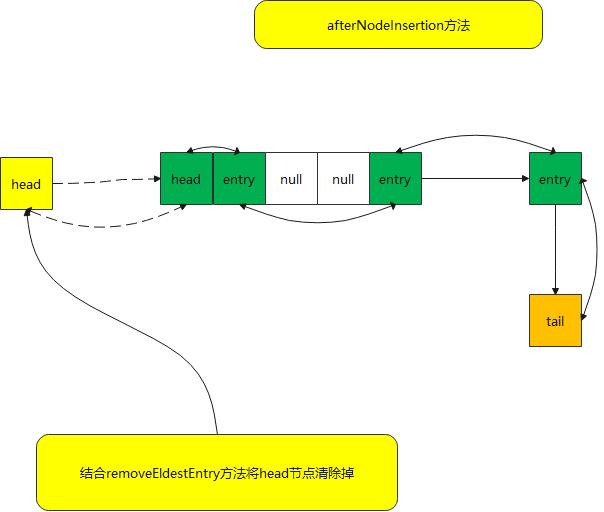
afterNodeInsertion方法
void afterNodeInsertion(boolean evict) { // 删除首节点
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}- evict 参数从hashmap中传入默认为ture 同一节点 包括put compute 方法等最后都会调用
- removeEldestEntry 方法重写 作者推荐结合起来使用,在 put方法 lru缓存中可以删除首节点,将不经常使用的节点清除掉
- removeNode 节点是直接调用hashmap中的节点
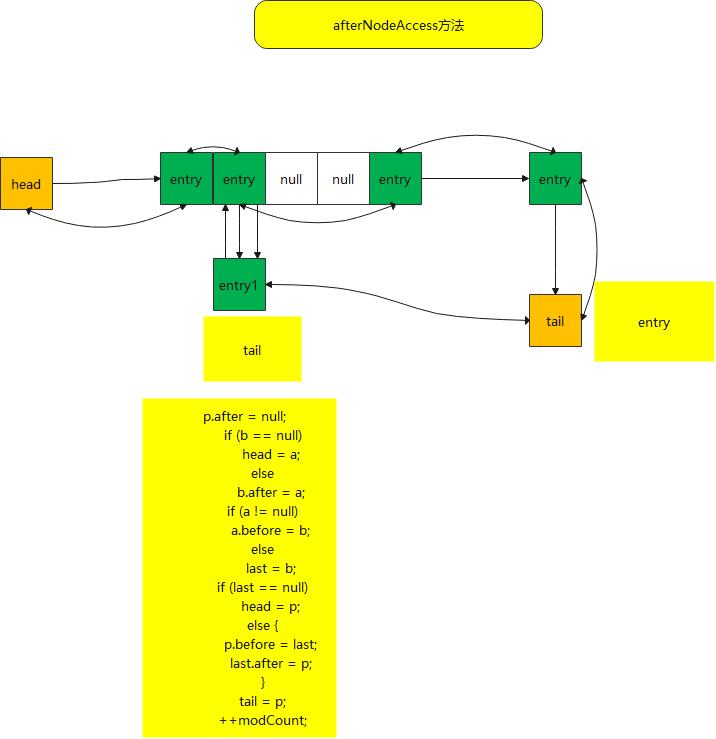
afterNodeAccess方法
void afterNodeAccess(Node<K,V> e) { // 将节点移到最后一个
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}- ·这个方法主要的作用就是将节点放到链表的最后,首先我们要在构造函数时,将accessOrder 参数设置为ture,不按插入顺序,而按访问顺序;这个方法很适合在lru建立缓存时使用
- hashmap在put元素时,存在相同的key值的情况 也会调用到这个方法来,就是说,put到相同元素时,或者get元素,都会将该数据放到最后
- 中间的操作,主要就是涉及到的链表操作
internalWriteEntries方法
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}该方法为了优化数据传输时,序列化优化数据;当hashmap写入数据时,会调用internalWriteEntries 将 头和末尾指针放入流中
get 和getOrDefault clear 方法
- get方法 直接调用hashmap的get方法判断是否 将数据放到末尾
- getOrDefault 方法 当数据获取不到时,设置默认数据
- clear 方法 调用 hashmap的clear方法,将数据清除 并将双向链表清理
- 这些方法都是比较直接的,我就不仔细分析了
LinkedHashIterator 迭代器
我们比较常用的keySet() 方法 并获取到LinkedKeyIterator 迭代器 说说这个
先从 keySet 方法 获取LinkedKeySet 类开始
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<K> iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
上面截取了一部分常用方法;清理数据 获取迭代器 删除key值的方法 获取迭代器的方法
迭代器
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
public final K next() { return nextNode().getKey(); }
}
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}给我们提供了 几种获取迭代器的方法 总的来说都是继承自LinkedHashIterator 迭代器,并在基础上做了 next方法重写
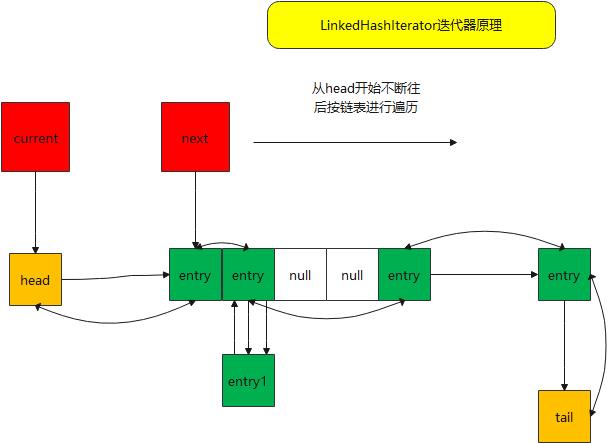
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}- 我相信如果你看了linkedlist的迭代器这个也是很简单的,这个和那个对比起来也很像的
- 并在迭代器中做了一个快速失败机制,这在每个集合中都使用
- 包括两个节点 的处理 next记录 下个节点;current记录当前节点
总结
整个LinkedHashMap 提供了链表将hashmap的node节点进行封装,并提供插入顺序访问,及访问数据的优化等等方法。就像作者说的那样推荐我们作为lru缓存的使用;putIfAbsent 方法 ;removeEldestEntry accessOrder 需要 linkedhashmap做为缓存时,这些方法 和属性设置,会增加我们的开发效率;如果不需要其他操作,我们也可以把作为顺序访问的数据结构使用
以上是关于Java 集合深入理解 (十六) :LinkedHashMap 实现原理深入 以及推荐使用建立lru缓存的主要内容,如果未能解决你的问题,请参考以下文章