Java 集合深入理解 (十七) :TreeMap源码研究如何达到快速排序和高效查找
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合深入理解 (十七) :TreeMap源码研究如何达到快速排序和高效查找相关的知识,希望对你有一定的参考价值。
前言
TreeMap是一个能比较元素大小的Map集合,会对传入的key进行了大小排序。其中,可以使用元素的自然顺序,也可以使用集合中自定义的比较器来进行排序;应用在需要排序的场景;其次说到排序的数据结构,肯定会想到PriorityQueue,也是排序的数据结构,但底层实现是数组,并采用最小顶堆的算法实现的;而我们的treemap则采用红黑树的方式进行存储数据,不采用最小顶堆算法(经过排序的完全二叉树)进行实现,具体看源码进行分析。
示例
public static void main(String[] args) {
System.out.println("----------------treemap---------------");
TreeMap< String, String> tm=new TreeMap<String, String>();
tm.put("9", "9");
tm.put("1", "1");
tm.put("3", "3");
tm.put("5", "5");
tm.put("8", "8");
tm.put("2", "2");
tm.keySet().forEach(k->{
System.out.println(k);
});
System.out.println("----------------treemap Comparator---------------");
TreeMap< String, String> tms=new TreeMap<String, String>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return Integer.valueOf(o1)>Integer.valueOf(o2)?1:-1;
}
});
tms.put("11", "11");
tms.put("23", "23");
tms.put("54", "54");
tms.put("25", "25");
tms.put("45", "45");
tms.put("99", "99");
tms.keySet().forEach(k->{
System.out.println(k);
});
}
----------------treemap---------------
1
2
3
5
8
9
----------------treemap Comparator---------------
11
23
25
45
54
99从上面例子来看我们两种方式去实现的
- 对于treemap中添加数据时,就会转换成红黑树 并使用传入参数默认compareTo 方法进行对比数据
- 然后对于自定的对比标准,需要实现Comparator 类中的compare 方法
- 从这个小例子就可以看出 ,按照key进行排序,在迭代时可以快速的访问数据
红黑树
红黑树(RBT)的定义:它或者是一棵空树,是具有特殊性质的平衡二叉查找树
- 节点非红即黑。
- 根节点是黑色
- 所有null结点称为叶子节点,且认为颜色为黑色
- 所有红节点的子节点都为黑色
- 从任意节点到其叶子节点 的所有路径上都包含相同数目的黑节点。
如果单从实现功能来说,treemap可以采用顺序二叉查找树即可,当然也可以使用avl平衡二叉树实现。至于为什么使用红黑树实现,也在于红黑树的特殊性质来选择的。 很大一部分来说,应该是性质决定的
红黑树对平衡树的一种改进,任意一个节点,它的红黑树的间隔不超过一倍,但它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但对之进行平衡的代价较低, 其平均统计性能要强于 AVL 。
- 红黑树需要维持颜色变更,因此 插入和删除保持为 O(log n))次;
- avl树需要维持任何节点的两个子树最大差别为1;因此总的来说,建树复杂度为O(NlogN)
- 红黑树是二叉排序树,因此可以采用中序遍历法,进行遍历出排序好的数据

比如如何插入结点 ,以及删除结点 维持红黑树的平衡,涉及到保持特性而做的左旋或者右旋,颜色的变化,可以看一下我这篇对红黑树的解析
整个treemap的实现就是基于红黑树而实现的,所以弄清楚红黑树的原理是研究源码的基础
注释分析
/**
*基于红黑树的{@link NavigableMap}实现。地图是根据{@linkplain可比自然图排序的它的键的}排序,或者由map提供的{@link Comparator}排序创建时间,取决于使用的构造函数。
*<p>此实现为{@code containsKey}、{@code get}、{@code put}和{@code remove}操作。算法是Cormen、Leiserson和Rivest的<em>算法简介</em>。
*
*<p>请注意,树映射维护的排序与任何排序的映射一样,以及无论是否提供显式比较器,都必须<em>一致如果要正确实现{@code Map}接口(请参阅{@code Comparable}或{@code Comparator}以获取
*<em>的精确定义与equals一致(这是因为{@code Map}接口是根据{@code equals}定义的操作,但排序映射使用其{@code执行所有键比较compareTo}(或{@code compare})方法,因此
*从排序图的观点来看,这种方法是相等的。行为一个排序映射<em>的定义是</em>的,即使它的排序是与{@code equals}不一致;它就是不遵守总承包合同{@code Map}接口的。
*
*<p><strong>请注意,此实现不同步。</strong>如果多个线程同时访问一个映射,则线程在结构上修改映射,它必须同步外部(结构修改是添加或删除删除一个或多个映射;只是改变了相关的价值
*使用现有密钥不是结构修改。)这是通常通过在某个对象上同步来完成封装地图。如果不存在这样的对象,则应该使用
*{@link Collections#synchronizedSortedMap Collections.synchronizedSortedMap}方法。这最好在创建时完成,以防止意外对地图的非同步访问:<pre>SortedMap m=Collections.synchronizedSortedMap(新树映射(…))</预处理>
*
*<p>集合的{@code iterator}方法返回的迭代器所有此类的“集合视图方法”返回的<em>快速失败</em>:如果映射在迭代器是以任何方式创建的,除了通过迭代器自己的
*{@code remove}方法,迭代器将抛出一个{@链接ConcurrentModificationException}。因此,面对修改后,迭代器会快速而干净地失败,而不是冒着
*未来某个未定时间内的任意、不确定性行为。
*
*<p>请注意,不能保证迭代器的快速失败行为一般说来,不可能在未来作出任何硬性保证存在未同步的并发修改。失败快速迭代器
*尽最大努力抛出{@code ConcurrentModificationException}。因此,编写依赖于此的程序是错误的其正确性例外:<em>迭代器的快速失败行为应该只用于检测错误</em>
*
*<p>此类中的方法返回的所有{@code Map.Entry}对它的视图表示映射创建时的快照生产。它们不支持{@code Entry.setValue}方法(但是请注意,可以在使用{@code put}关联的映射。)
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
*
* @author Josh Bloch and Doug Lea
* @see Map
* @see HashMap
* @see Hashtable
* @see Comparable
* @see Comparator
* @see Collection
* @since 1.2
*/全篇注释大概的意思在于
- 基于红黑树的NavigableMap 实现,可根据对象的键值进行排序,或者提供的Comparator 进行排序,构造函数时可以设置
- 树映射维护的排序与任何排序的映射一样,以及无论是否提供显式比较器,都必须实现Comparable 接口,定义好equals操作
- 这个实现是不同步的,多线程访问的情况下,会出现数据不一致的情况,因此最好使用Collections.synchronizedSortedMap} 方法控制同步
- 所提供的迭代器也会使用快速失败机制保证数据的安全性
- 不支持Entry.setValue 方法
接口实现
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{通过继承AbstractMap 对map的实现,说明treemap 是一个key-value的存储格式,并且具有map的基本操作 包括put等方法;然后实现NavigableMap ,这个接口 继承SortedMap 接口,会有很多排序的方法treemap实现,然后Cloneable 和Serializable 实现是可以被序列化的,所有集合都是可被序列,实现 serializble,我相信都会做transient 进行序列化传输时的优化
类的属性分析
/**
* 用于维护此树映射中的顺序的比较器,或
* 如果它使用密钥的自然顺序,则为null。
*
* @serial
*/
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
/**
* 树中的条目数
*/
private transient int size = 0;
/**
* 树的结构修改数。
*/
private transient int modCount = 0;几个属性分析
- comparator 比较器,用于构成二叉排序树时,对比元素的大小
- size记录整个红黑树的数据大小
- modcount记录操作红黑树的修改大小
- root属性存储数据,是一个红黑树,记录好根结点,我们在根据root进行分析基本结点;包括我们需要存储的数据 key 和value值,然后构成 树的存储结构 左子树 ,右子树,父结点 、以及 红黑树所需属性颜色结点;
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
/**
* Make a new cell with given key, value, and parent, and with
* {@code null} child links, and BLACK color.
*/
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}- 在结点中,构造方法中只有父结点,而子节点如何构造出来,是在使用时会将属性赋值,并没有提供方法进行设置
-
transient 非私有以简化嵌套类访问 避免传输时不必要的空间占用
被transient修饰的变量不参与序列化和反序列化;而且属性是实现了Serializable说明他能够被序列化和反序列化传输的;后来查阅了一些资料了解到:
,假如root的长度为10,而其中只有5个元素,那么在序列化的时候只需要存储5个元素,而数组中后面5个元素是不需要存储的。于是将elementData定义为transient,避免了Java自带的序列化机制,并定义了两个方法writeObject和readObject,实现了自己可控制的序列化 什么是writeObject 和readObject?可定制的序列化过程
构造方法分析
无参构造方法
public TreeMap() {
comparator = null;
}当采用无参构造产生对象时,会将比较器设置为null,而采用key进行比较顺序
有参构造方法
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}采用外部传输比较器,当然比较器的类型和key值类型相同,也可以传空和无参构造相同;其中包括直接传入map,和传入 SortedMap 这个也是进行设置
查询操作
其中包含的方法有 size 、 containsKey 、containsValue、get 方法、以及获取 比较器 、 firstKey、lastKey 、getEntry 方法 getCeilingEntry 方法、getFloorEntry 方法、等等
getEntry(key)方法 根据 key来获取entry
该方法作为 containsKey(key) 和 get(key)方法 和 remove方法的基础, 从代码层面去看如何实现的
- containsKey 通过方法获取到数据判断是否为空,如果不为空则返回true
- get(key) 通过方法获取到结点数据
- remove(key) 则根据方法获取结点判断数据是否为空,在判断是否删除
从代码来看是两种 情况
- 走无比较器的逻辑则采用的是,获取 根节点,采用key的比较器进行比较获取到数据,不知道你们发现没有,这个看起来和平衡二叉树进行平衡,或者查找二叉树的结点很像
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
- 走有比较器的情况,会走到 getEntryUsingComparator 方法中 这个方法和无设置比较器上的区别在与是否使用比较器进行对比。其他遍历方案是一样的。
final Entry<K,V> getEntryUsingComparator(Object key) {
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
return null;
}getFirstEntry 方法 获取第一个数据
首先这里的获取第一个数据并不是树的root结点,而是获取的左子树的的左边结点,根据二叉排序树的性质来说,这里获取到的是整个树中值最小的结点
- 为什么抽象出这个方法,我们需要遍历整个红黑树,而在之前我在分析红黑树时,遍历红黑树可以采用前序中序 后续进行打印整个树,但这里不是采用的 二叉树的应用分治法进行处理的。而是获取首个结点,而这里的遍历方法就采用的时候获取到左边结点,在获取 比左边结点大的下一个数据。这样更方便代码阅读,虽然代码量相对于递归来看会麻烦一些
- getFirstEntry() 方法 获取到 最小结点
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
} 
- containsValue(Object value)方法中 遍历所有数据进行 结合 getfirstentry方法和 successor方法的
public boolean containsValue(Object value) {
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e))
if (valEquals(value, e.value))
return true;
return false;
} 
- successor(Entry<K,V> t) 方法获取当前结点的下一个结点
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
- firstKey() 方法 这是在排序时需要获取的方法,结合 getFirstEntry 去获取到key值
public K firstKey() {
return key(getFirstEntry());
}- firstEntry()方法这里 导出的对象 是一个新的对象,并且是 natvigableMap api method 方法
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}- 这里面包括获取key的迭代器 keyIterator (),pollFirstEntry 导出 数据,都是来自这个方法的 ,我就分析了,如果各位感兴趣可以看看源码 ValueIterator
getLastEntry() 获取最大的数据
经过上面的解析查询数据,大概也知道了获取结尾的节点了把,上面的是left ,那这边肯定是right了,虽然源码没有通过lastentry去遍历查找key对象,但是我想也可以有这样的方法去查找
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p;
}
- 当然上面有firstkey方法 ,那我们这里有lastKey 方法用获取 lastkey 和 lastEntry
public K lastKey() {
return key(getLastEntry());
}
public Map.Entry<K,V> lastEntry() {
return exportEntry(getLastEntry());
}successor 和predecessor方法
这两个方法分别对应当前节点的下一个结点,和上一个结点,我在分析containsValue 方法时,分析过 successor 方法,可以看看上面,这里我就不多说
- predecessor 方法一看和successor 差别点 就在 于 判断左结点是否为空,
static <K,V> Entry<K,V> predecessor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.left != null) {
Entry<K,V> p = t.left;
while (p.right != null)
p = p.right;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.left) {
ch = p;
p = p.parent;
}
return p;
}
}
平衡操作
put(K key, V value) 方法 用于添加数据
- 根节点为空,添加某个结点,默认结点则为黑色,并且当前结点的子结点及父结点都为空,将新结点赋值给根结点 ,这里就能看出 key值是一定不能为空的
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // key值判断是否为空
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}- 当根结点不为空时,这里先做的是二叉排序树进行插入结点 ,如果不清楚怎么二叉排序树,可以看看我之前分析的二叉排序树
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;这里做了个拆分开 有比较器和无比较器的情况

- 由上图我们就可以看出破坏了红黑树的性质,我们肯定是要进行重新颜色平衡的,就涉及到下面的代码
fixAfterInsertion(e);
size++;
modCount++;fixAfterInsertion 方法 (插入后固定 方法)
理解这个方法之前,你一定要理解红黑树是如何平衡的,要不然你可能有点蒙
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
- 把 当前插入结点变红 ,判断是否继续平衡,如果是插入我上面的结点则直接就平衡了,最后把根 结点染黑
x.color = RED;
- 这里判断平衡的方式,x == null || x == root || x.parent.color != RED 主要是判断 父结点是否为黑色,则该树就平衡,这样来看是不是和avl树对比起来简单很多
- colorOf(Entry<K,V> p)方法获取 到结点的颜色,parentOf(Entry<K,V> p)方法 获取到父结点的方法,setColor(Entry<K,V> p, boolean c) 设置 结点为某个颜色,leftOf(Entry<K,V> p) 获取该结点的左结点,以及rightOf(Entry<K,V> p) 获取结点的右子结点
private static <K,V> boolean colorOf(Entry<K,V> p) {
return (p == null ? BLACK : p.color);
}
private static <K,V> Entry<K,V> parentOf(Entry<K,V> p) {
return (p == null ? null: p.parent);
}
private static <K,V> void setColor(Entry<K,V> p, boolean c) {
if (p != null)
p.color = c;
}
private static <K,V> Entry<K,V> leftOf(Entry<K,V> p) {
return (p == null) ? null: p.left;
}
private static <K,V> Entry<K,V> rightOf(Entry<K,V> p) {
return (p == null) ? null: p.right;
}- 对于红黑树的平衡,是判断的是叔叔结点的颜色,代码不多但是要理解算法的含义很有必要的
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}- 父节点是祖父节点的左孩子 祖父节点的另一个子节点(叔叔节点)是红色
对策: 将当前节点的父节点和叔叔节点涂黑,祖父节点涂红,把当前节点指向祖父节点,从新的当前节点开始算法
n节点代表 当前节点 p 代表父亲节点 g 代表祖父节点 u代表叔叔节点

- 插入节点的父节点是红色 ,父节点是祖父节点的左孩子;叔叔节点是黑色,当前节点是其父节点的右孩子
对策: 以当前父节点为支点左旋,当前节点的左节点做为新的当前节点。

- 插入节点的父节点是红色 ,父节点是祖父节点的左孩子;叔叔节点是黑色,当前节点是其父节点的左孩子
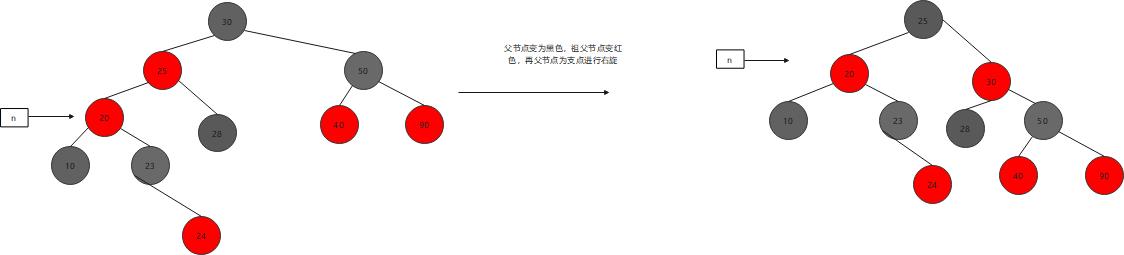
对策:父节点变为黑色,祖父节点变红色,再父节点为支点进行右旋
左旋操作
在平衡的情况下涉及到结点进行左旋
public void rotateLeft(Node<E> x){
if(x!=null){
Node<E> y=x.right;//先取到Y
//1.把h作为X的右孩子 x.right=h
x.right=y.left;
//2.h不为空 ,则将h的父亲设置为 x
if(y.left!=null){
y.left.parent=x;
}
//3。把Y移到原来X的位置上 y的父亲修改为 x的父亲
y.parent=x.parent;
// 4.x父亲为空
if(x.parent==null){
//设置根节点为y节点
root=y;
}else{
//x父亲不为空,则需要判断 x是父亲的左孩子还是右孩子 将父的左孩子或者右孩子设置为y
if(x.parent.left==x){
x.parent.left=y;
}else if(x.parent.right==x){
x.parent.right=y;
}
}
//3.X作为Y的左孩子
y.left=x;
x.parent=y;
}
}
整个左旋操作还是很简单的,基本就是通过链表前后断链并重新链接实现的 需要结合代码看一下,在代码上备注了有的
- 先取到Y 把h作为X的右孩子 x.right=h
- h不为空 ,则将h的父亲设置为 x
- 把Y移到原来X的位置上 y的父亲修改为 x的父亲
- x父亲为空 设置根节点为y节点
- x父亲不为空,则需要判断 x是父亲的左孩子还是右孩子 将父的左孩子或者右孩子设置为y
- X作为Y的左孩子
右旋操作
public void rotateRight(Node<E> y) {
if (y != null) {
Node<E> yl = y.left;
//step1
y.left = yl.right;
if (yl.right != null) {
yl.right.parent = y;
}
// step2
yl.parent = y.parent;
if (y.parent == null) {
root = yl;
} else {
if (y.parent.left == y) {
y.parent.left = yl;
} else if (y.parent.right == y) {
y.parent.right = yl;
}
}
// step3
yl.right = y;
y.parent = yl;
}
}
右旋操作 和左旋操作很像
- 首先拿到 y的左节点 x 在拿到 x的右节点 i 用于右旋时,进行移动
- i不为空,则将 i的父节点 设置为 y
- 拿到 y的 父节点 判断是否为根节点 ,不为根节点 则 判断是否y为父节点的左节点 还是有节点 并将父节点的左节点 或右节点 设置为 x 将 x的父节点设置为y的父节点
- 最后将 x的右节点设置为y, y的父节点设置为x 就可以了
remove(Object key) 方法
该方法用来删除key值得某个结点,并返回老得value值
- 通过getEntry 获取到老得entry值,如果为null则直接返回,不为空继续调用deleteEntry 删除结点,并保持平衡
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}deleteEntry 方法
- 进行操作修改及size减少
modCount++;
size--;- 复制到下一个元素 删除结点如果有两个结点,往下面一个结点走
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children- 在替换节点(如果存在)启动fixup。 主要是做一个替换结点,为后面得平衡做铺垫
Entry<K,V> replacement = (p.left != null ? p.left : p.right);- 当被删除得下个结点得左节点或者右结点不为空 ,
if (replacement != null) {
// 将替换链接到父级
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// 取消链接,使它们可以由fixAfterDeletion使用。
p.left = p.right = p.parent = null;
// 修复替换
if (p.color == BLACK)
fixAfterDeletion(replacement);
}- 只有一个root根结点时,则将root设置为空即可
else if (p.parent == null) { // return if we are the only node.
root = null;
} - 没有孩子。将self用作幻像替换并取消链接。 这里做得也是 如果是黑结点 ,则需要先平衡在做 数据设置为null
else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}fixAfterDeletion 方法,用于平衡删除结点树
这个方法和使用来做删除结点得平衡树得操作,这里就是红黑树删除结点平衡操作
- 只要结点不是根结点 或者 结点得颜色为黑色,就会一直做平衡操作
while (x != root && colorOf(x) == BLACK) {- 判断x结点为 父亲结点得左右结点
if (x == leftOf(parentOf(x))) {- 获取到兄弟结点
Entry<K,V> sib = rightOf(parentOf(x));- 兄弟结点为红色
- 对策:把父节点染成红色,兄弟节点染成黑色,对父节点进行左旋,重新设置x的兄弟节点
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
}
- 当前节点x 的兄弟节点是黑色 ,被删除节点是父节点的左孩子,兄弟节点的两个孩子都是黑色
对策:将x的兄弟节点设为红色,设置x的父节点为新的x节点
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
}
- 当前节点x 的兄弟节点是黑色 被删除节点是父节点的左孩子,兄弟的右孩子是黑色,左孩子是红色
对策:将x兄弟节点的左孩子设为黑色,将x兄弟节点设置红色,将x的兄弟节点右旋,右旋后,重新设置x的兄弟节点。

- 当前节点x 的兄弟节点是黑色 被删除节点是父节点的左孩子,兄弟节点的右孩子是红色
对策:把兄弟节点染成当前节点父节点颜色,把当前节点父节点染成黑色,兄弟节点右孩子染成黑色,再以当前节点的父节点为支点进行左旋,算法结算

else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}最后将结点设置为黑色
NavigableMap API方法
之前在查找方法中解析过firstEntry 方法和lastEntry 方法 和pollFirstEntry方法和pollLastEntry方法 继续下面的方法解析
getLowerEntry方法(寻找最接近的小于key的Entry,没有找到就返回为null)
作为排序接口的的实现,提供最接近key的方法,方便我们使用
final Entry<K,V> getLowerEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp > 0) {
if (p.right != null)
p = p.right;
else
return p;
} else {
if (p.left != null) {
p = p.left;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.left) {
ch = parent;
parent = parent.parent;
}
return parent;
}
}
}
return null;
}
这里在查找接近最小值时,利用二叉排序树的特性,如果是小于传入的值,则找右子树,如果等于是,就找父亲,就是最接近的值,while不断的循环找到个值;
System.out.println("----------------treemap lowerKey---------------");
TreeMap< String, String> tmss=new TreeMap<String, String>();
tmss.put("9", "9");
tmss.put("1", "1");
tmss.put("3", "3");
tmss.put("5", "5");
tmss.put("8", "8");
tmss.put("2", "2");
System.out.println(tmss.lowerKey("4"));
----------------treemap lowerKey---------------
3
System.out.println("----------------treemap lowerKey---------------");
TreeMap< String, String> tmss=new TreeMap<String, String>();
tmss.put("9", "9");
tmss.put("1", "1");
tmss.put("3", "3");
tmss.put("5", "5");
tmss.put("8", "8");
tmss.put("2", "2");
System.out.println(tmss.lowerKey("5"));
----------------treemap lowerKey---------------
3
getFloorEntry(K key)方法(从名字来看就是向下取整)
final Entry<K,V> getFloorEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp > 0) {
if (p.right != null)
p = p.right;
else
return p;
} else if (cmp < 0) {
if (p.left != null) {
p = p.left;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.left) {
ch = parent;
parent = parent.parent;
}
return parent;
}
} else
return p;
}
return null;
}
根据代码进行分析出来我们在 这和getLowerEntry 不太一样的点在于,如果找到了值,就直接返回该值,没有找到才会向下走,这在代码逻辑上就能看到
System.out.println("----------------treemap floorKey---------------");
TreeMap< String, String> tmss=new TreeMap<String, String>();
tmss.put("9", "9");
tmss.put("1", "1");
tmss.put("3", "3");
tmss.put("5", "5");
tmss.put("8", "8");
tmss.put("2", "2");
System.out.println(tmss.floorKey("4"));
----------------treemap floorKey---------------
3
System.out.println("----------------treemap floorKey---------------");
TreeMap< String, String> tmss=new TreeMap<String, String>();
tmss.put("9", "9");
tmss.put("1", "1");
tmss.put("3", "3");
tmss.put("5", "5");
tmss.put("8", "8");
tmss.put("2", "2");
System.out.println(tmss.floorKey("5"));
----------------treemap floorKey---------------
5
getCeilingEntry方法和getHigherEntry方法
根据上两个方法来判断这两个方法 一个是向上取整,和上一个方法,我这里只分析一个,基本就能明白下个方法把,我分析一下getHigherEntry 方法,因为区别都是在于cmp=0时做的逻辑处理
final Entry<K,V> getHigherEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp < 0) {
if (p.left != null)
p = p.left;
else
return p;
} else {
if (p.right != null) {
p = p.right;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
}
}
return null;
}
System.out.println("----------------treemap ceilingKey---------------");
TreeMap< String, String> tmsss=new TreeMap<String, String>();
tmsss.put("9", "9");
tmsss.put("1", "1");
tmsss.put("3", "3");
tmsss.put("5", "5");
tmsss.put("8", "8");
tmsss.put("2", "2");
System.out.println(tmsss.ceilingKey("6"));
----------------treemap ceilingKey---------------
8
迭代器(PrivateEntryIterator)
这个迭代器,我们在分析其他方法时基本也了解整个迭代的操作流程,接下来进行继续分析一下
Entry<K,V> next;
Entry<K,V> lastReturned;
int expectedModCount;如果您看过其他集合的迭代器,这个我相信很好理解,为什么这么说,next记录当前遍历的结点,lastretruned 记录上一个结点,并防止重复删除 , expectedmmodcount 则保证数据安全性,快速失败机制,具体是不是我们看一下方法属性
hasNext 判断迭代是否相等
public final boolean hasNext() {
return next != null;
} final Entry<K,V> nextEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = successor(e);
lastReturned = e;
return e;
}
nextEntry方法 中就是包含了 快速失败机制,及设置上一个结点信息,然后供删除时判断
其他的方法我不在过多的分析,各位如果有想法,可以自己去解析,其他的就比较简单
总结
经过分析treemap,使我也有很大的提升,希望这篇文章对你的提升也很大;如果各位时小白的话,可以按照搞清楚树,和排序二叉树 和avl树 红黑树,然后在来理解treemap,会理解很多,要不然恐怕很难理解其中的原理,共同学习成长,当然各位大牛,希望能指正一下我写的这篇文章,得到提升
以上是关于Java 集合深入理解 (十七) :TreeMap源码研究如何达到快速排序和高效查找的主要内容,如果未能解决你的问题,请参考以下文章