通过解析HashMap源码手写一个HashMap
Posted Dream_it_possible!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过解析HashMap源码手写一个HashMap相关的知识,希望对你有一定的参考价值。
前言
我们发现HashMap在jdk 1.8之后用了数组+链表+红黑树的结构,为了加深对HashMap底层设计的理解,自己也读了一些hashmap相关的源码,因此想通过手写hashmap去理其底层的操作原理。
目标: 基于数组+链表结构实现一个HashMap,包含get()、put()、remove()方法。
环境: jdk1.8
知识储备: hashcode, 幂等性, 数组,链表,红黑树。
原理: Hashmap 是先通过key计算得到一个hash值,通过hash值%(length-1)找到桶的位置,找到位置通过比对key 和hash值就能得到key对应的value, 如果有链表遍历链表,如果有红黑树就遍历红黑树,然后再进行相应的操作,如get,put, remove等。
HashMap源码解析
1. HashMap为什么用到Hash值,是怎么计算hash值的?
通过此hash值和map的length计算得到key 在hashmap桶里的位置index, 使用到的hash算法也是采用散列思想,能够均匀分布在hashmap的桶里面。
先看一段源代码, hash(object key)方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}可以发现, HashMap计算hash值是依据hashcode实现的,由于hashcode的幂等性,每次结算得出来的结果是相等的, 写一个小demo,多次运行程序:
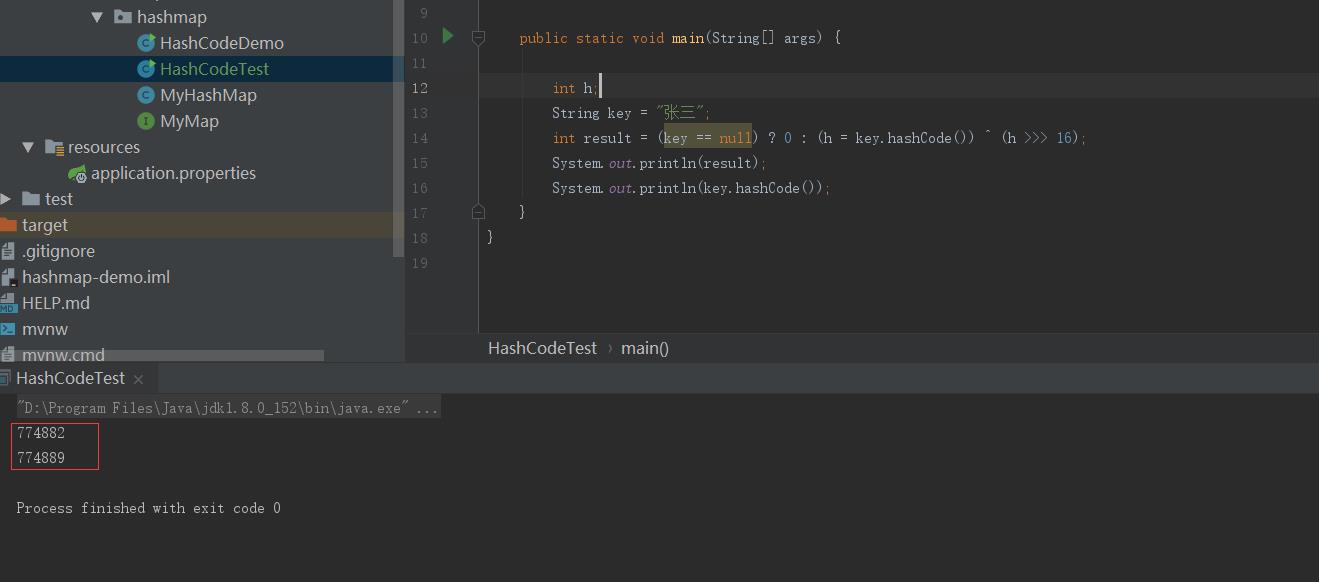
发现每次结算出来的结果是相同的, 因为幂等性,存放到桶里的key 对应的hash值是不相同的,同时也是固定的。
2. get()方法源码解析
看一下hashmap里get()里一个重要的方法: getNode()
1) 根据hash值计算出位置赋值给first, 然后比较first的key是否与传入的key 相等,如果相等就返回,如果不相等,那么就遍历first的next。
2) 如果first是一颗红黑树,那么就执行getTreeNode()方法,如果first不是那么就遍历链表。
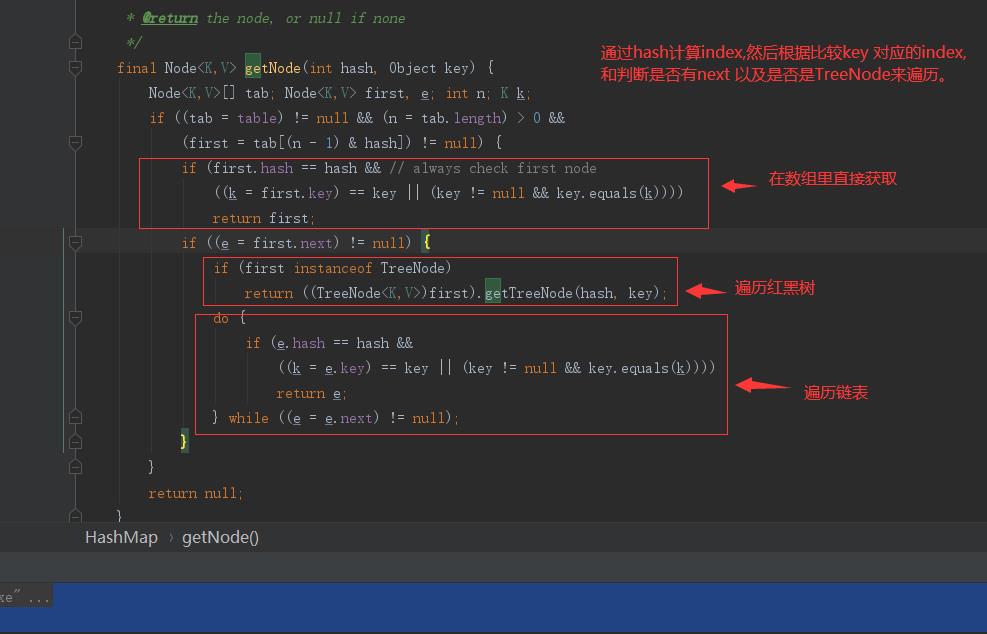
具体的流程如下:
1. 通过key 进行hash 计算得到index
2. 根据index 判断是否为空,如果为空就直接返回null。
3. 如果不为空,有查询的key与当前key 进行比较,如果当前节点的next是否为空,那么就返回当前节点,如果为不为空那么就取遍历next,判断node是否为树,如果是树,那么遍历树,如果是链表那么遍历链表,通过比较hash值和key来判断,直到相等为止。
4. 如果相等就直接返回数据。
3. put() 方法源码解析
在Put 到桶里的元素之前,每个元素可以看作为一个Node, Node里包含 hash值,hash值是必须要有的,因为在遍历链表的时候,不能仅通过hashcode计算出来的index来比较,还有需要比较hash,才能找到指定的key, hashmap中定义的Node的结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}put 流程分析:
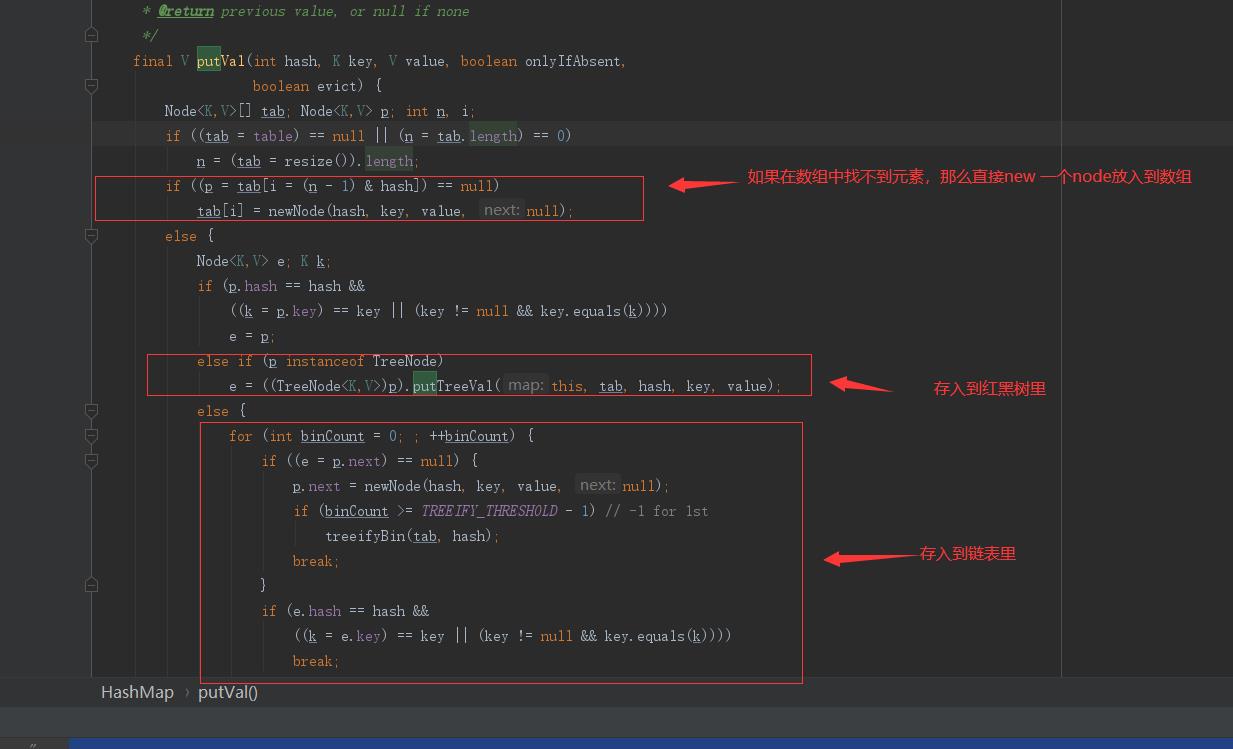
具体的流程如下:
1. 算出hashcode, 取模得到下标,然后通过下标拿到对象。
2. 如果为根据index取到的值为空那么可以直接赋值。
3. 如果不为空,那么使用链表进行存储, 每次存储的时候需要用新的节点的next指向之前的节点。
看了几个方法的源码后,发现他们都有相似的规律: 通过hash值去找到node, 然后判断node是否是链表或者红黑树,然后遍历链表或TreeNode(红黑树),然后再操作。
手写HashMap
1. 定义Map接口
HashMap实现了Map接口,可以定义如下常用方法,另外需要添加一个Entry<K,V>接口,此接口用来获取节点(Entry)的key 和value。
package com.example.hashmap;
/**
* @author bingbing
* @date 2021/5/15 0015 15:51
*/
public interface MyMap<K, V> {
int size();
V put(K k, V v);
V get(K k);
V remove(K k);
interface Entry<K, V> {
K getKey();
V getValue();
}
}
2. 定义Entry 对象
主要包含当前节点的key、value、next指针以及hash值,另外实现Map里的Entry接口。
class Entry<K, V> implements MyMap.Entry<K, V> {
int hash;
K k;
V v;
Entry<K, V> next;
public Entry(K k, V v, Entry<K, V> next, int hash) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}3 .定义HashMap 实现类
注意:
1) put()方法,在new Node时将计算得到的hash值和当前的entry 当作next赋赋值给node。 table[index] = new Entry<>(k, v, entry, hash);
2) get()方法,在遍历链表的时候,需要比较hash值和next,key 。
3) remove()方法,如果在链表里,那么用前一个节点的next指向当前节点next即可删除。
package com.example.hashmap;
/**
* @author bingbing
* @date 2021/5/15 0015 15:52
*/
public class MyHashMap<K, V> implements MyMap<K, V> {
Entry[] table = null;
int size = 0;
public MyHashMap() {
table = new Entry[16];
}
@Override
public int size() {
return size;
}
/**
* 算出hashcode, 取模得到下标,然后通过下标拿到对象。
* 如果为空那么可以直接赋值。
* 如果不为空,那么使用链表进行存储
*
* @param k
* @param v
* @return
*/
@Override
public V put(K k, V v) {
int index = hash(k);
int hash = k.hashCode();
Entry<K, V> entry = table[index];
if (null == entry) {
table[index] = new Entry<>(k, v, null, hash);
size++;
} else {
// 链表
table[index] = new Entry<>(k, v, entry, hash);
}
return (V) table[index].getValue();
}
private int hash(K k) {
int index = k.hashCode() % (table.length - 1);
if (index < 0) {
// 如果取的到为负数
return -index;
}
return index;
}
/**
* 1. 通过key 进行hash 计算得到index
* 2. 根据index 判断是否为空,如果为空就直接返回null。
* 3. 如果不为空,有查询的key与当前key 进行比较,如果当前节点的next是否为空,那么就返回当前节点,如果为不为空那么就取遍历next,直到相等为止。
* 4. 如果相等就直接返回数据。
*
* @param k
* @return
*/
@Override
public V get(K k) {
int index = hash(k);
int hash = k.hashCode();
Entry<K, V> entry = table[index];
if (null == entry) {
return null;
} else {
if (entry.getKey() == k && hash == entry.hash) {
return entry.getValue();
}
Entry<K, V> next = entry.next;
while (null != next) {
if (next.getKey() == k&& hash == next.hash) {
return next.getValue();
}
next = next.next;
}
}
return null;
}
@Override
public V remove(K k) {
int index = hash(k);
int hash = k.hashCode();
Entry<K, V> entry = table[index];
if (null == entry) {
return null;
} else {
if (entry.getKey() == k && entry.hash == hash) {
// 直接移除该元素
entry = entry.next;
table[index] = entry;
return (V) table[index];
}
if (null != entry.next) {
// 链表
Entry<K, V> head = entry;
Entry<K, V> p = head;
Entry<K, V> next = head.next;
do {
if (next.getKey() == k && next.hash == hash) {
// 删除该节点, 前一个节点的next 指向该节点的next
p.next = next.next;
break;
}
p = next;
next = next.next;
} while (next != null);
} else {
// 数组
table[index] = null;
}
return table[index] == null ? null : (V) table[index].getValue();
}
}
class Entry<K, V> implements MyMap.Entry<K, V> {
int hash;
K k;
V v;
Entry<K, V> next;
public Entry(K k, V v, Entry<K, V> next, int hash) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}
4. 测试
测试get(), put () ,remove()方法
package com.example.hashmap;
import java.util.HashMap;
import java.util.Map;
/**
* @author bingbing
* @date 2021/5/15 0015 15:19
*/
public class HashMapDemo {
private static MyInnerMap myInnerMap = new MyInnerMap(16);
public static void main(String[] args) {
Map<Object, Object> map = new HashMap<>(16);
map.put("张三", "张三");
map.put("李四", "李四");
map.put("王五", "王五");
map.put("刘六", "刘六");
System.out.println(map);
myInnerMap.put("张三", "张三");
myInnerMap.put("李四", "李四");
myInnerMap.put("王五", "王五");
myInnerMap.put("刘六", "刘六");
myInnerMap.put("小二", "小二");
myInnerMap.put("李七", "李七");
myInnerMap.put("赵九", "赵九");
myInnerMap.put("周十", "周十");
myInnerMap.put("孙一", "孙一");
// 使用自定义的Map
MyMap<Object, Object> myMap = new MyHashMap<>();
myMap.put("张三", "张三");
myMap.put("李四", "李四");
Object o = myMap.put("周十", "周十");
System.out.println(myMap.get("张三"));
System.out.println(myMap.get("李四"));
System.out.println(myMap.get("周十"));
myMap.remove("周十");
System.out.println(myMap.get("周十"));
myMap.remove("李四");
System.out.println(myMap.get("李四"));
}
static class MyInnerMap {
int length;
MyInnerMap(int capacity) {
this.length = capacity;
}
// 利用数组的特性去取模,得到的hashcode 遵循幂等性
public void put(Object key, Object value) {
System.out.println("key:" + key + ",hashcode:" + key.hashCode() + ",位置:" + Math.abs(key.hashCode()) % (length - 1));
}
}
}
打印结果如下:
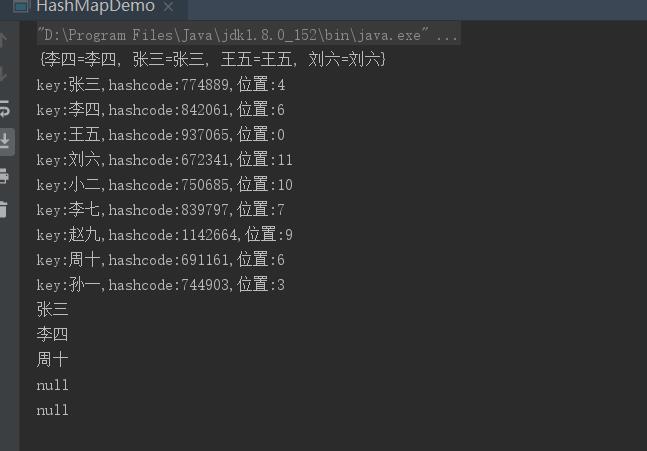
源码地址: https://gitee.com/bingbing-123456/java-source-learining.git
以上是关于通过解析HashMap源码手写一个HashMap的主要内容,如果未能解决你的问题,请参考以下文章