终于有人把Prometheus入门讲明白了 | 留言送书 Posted 2021-04-02 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了终于有人把Prometheus入门讲明白了 | 留言送书相关的知识,希望对你有一定的参考价值。
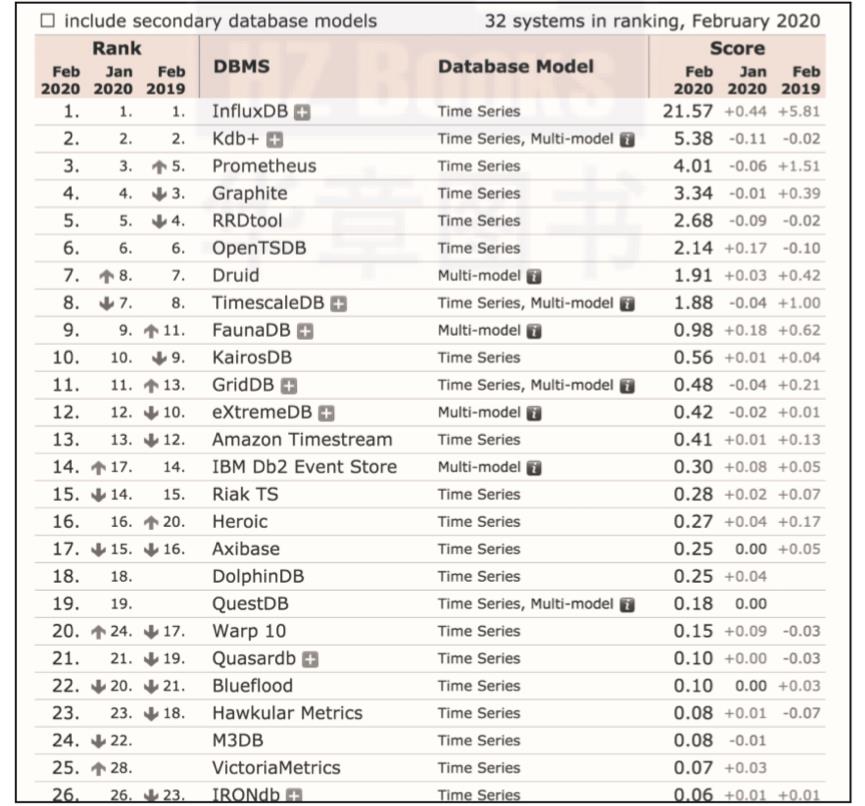
Prometheus既是一个时序数据库,又是一个监控系统,更是一套完备的监控生态解决方案。作为时序数据库,在2020年2月的排名中,Prometheus已经跃居到第三名,超越了老牌的时序数据库OpenTSDB、Graphite、RRDtool、KairosDB等,如图1所示。
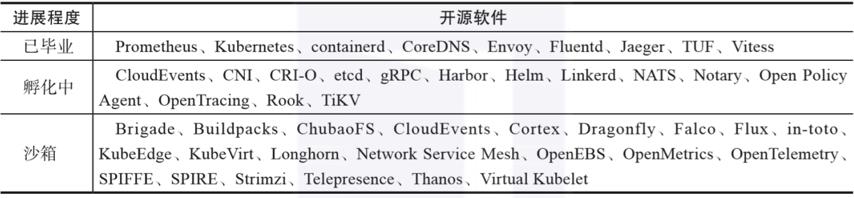
作为监控系统,2018年8月9日CNCF在PromCon(年度Prometheus会议)上宣布:Prometheus是继Kubernetes之后的第二个CNCF“毕业”项目。在CNCF管理的项目中,要从孵化转为毕业,项目必须被社区广泛采用,且有结构完整的治理过程文档,以及对社区可持续性和包容性的坚定承诺。Prometheus的开源社区十分活跃,在GitHub上拥有约30000颗星,并且经常会有小版本的更新发布在上面。除了PromCon、KubeCon和CloudNativeCon之外,CNCF也为采用者、开发人员和从业者搭建了面对面合作的平台,与Kubernetes、Prometheus及其他CNCF托管项目领导者探讨行业发展,一同设定云原生生态系统的发展方向。表1展示的是2020年KubeCon和CloudNativeCon重点关注的CNCF开源软件,从中可以看出Prometheus的重要性。
表1 2020年KubeCon和CloudNativeCon重点关注的CNCF开源软件
作为监控生态解决方案,仅仅是Prometheus的Exporter就已经支持了对官方收录和未收录的上千种常见软件、中间件、系统等的监控。
Prometheus和Kubernetes不仅在使用过程中紧密相关,而且在历史上也有很深的渊源。在加利福尼亚州山景城的Google公司里曾经有两款系统——Borg系统和它的监控Borgmon系统。Borg系统是Google内部用来管理来自不同应用、不同作业的集群的管理器,每个集群都会拥有数万台服务器及上万个作业;Borgmon系统则是与Borg系统配套的监控系统。Borg系统和Borgmon系统都没有开源,但是目前开源的Kubernetes、Prometheus的理念都是对它们的理念的传承。
Kubernetes系统传承于Borg系统,Prometheus则传承于Borgmon系统。Google SRE的书内也曾提到,与Borgmon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器调度管理系统中,通常会搭配Prometheus进行监控。
2012年前Google SRE工程师Matt T. Proud将Prometheus作为研究项目开始开发,在他加入SoundCloud公司后,与另一位工程师Julius Volz以开源软件的形式对Prometheus进行研发,并且于2015年年初对外发布早期版本。Prometheus是独立的开源项目,并且由公司来运作,有非常活跃的社区和许多开发人员,因此很多公司使用它来满足自己的监控需求。2016年5月,继Kubernetes之后Prometheus成为第二个正式加入CNCF的项目,同年6月正式发布1.0版本。2017年年底发布了基于全新存储层的2.0版本,该版本能更好地与容器平台、云平台兼容。
Prometheus官网首页如图2所示。Prometheus主要用于提供近实时,基于动态云环境、容器、微服务、应用程序等的监控服务。在《站点稳定性工程:Google如何运行可靠的系统》一书中也提到,尽管Borgmon仍然是谷歌内部的,但是将时间序列数据作为生成警报的数据源的想法,已经通过Prometheus等完美体现了。这直接说明了Prometheus和Kubernetes、Google具有很深的历史渊源。
Prometheus官网上的自述是:“From metrics to insight. Power your metrics and alerting with a leading open-source monitoring solution.”翻译过来就是:从指标到洞察力,Prometheus通过领先的开源监控解决方案为用户的指标和告警提供强大的支持。
与Nagios
尤其是第一点,这是很多监控系统望尘莫及的。多维度的数据模型和灵活的查询方式,使监控指标可以关联到多个标签,并对时间序列进行切片和切块,以支持各种图形、表格和告警场景。
除了上述4种特色之外,Prometheus还有如下特点:
Go语言编写,拥抱云原生。
采用拉模式为主、推模式为辅的方式采集数据。
二进制文件直接启动,也支持容器化部署镜像。
支持多种语言的客户端,如Java、JMX、Python、Go、Ruby、.NET、Node.js等语言。
支持本地和第三方远程存储,单机性能强劲,可以处理上千target及每秒百万级时间序列。
高效的存储。 平均一个采样数据占3.5B左右,共320万个时间序列,每30秒采样一次,如此持续运行60天,占用磁盘空间大约为228GB(有一定富余量,部分要占磁盘空间的项目未在这里列出)。
可扩展。可以在每个数据中心或由每个团队运行独立Prometheus Server。也可以使用联邦集群让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)对其进行扩展。
出色的可视化功能。 Prometheus拥有多种可视化的模式,比如内置表达式浏览器、Grafana集成和控制台模板语言。 它还提供了HTTP查询接口,方便结合其他GUI组件或者脚本展示数据。
精确告警。Prometheus基于灵活的PromQL语句可以进行告警设置、预测等,另外它还提供了分组、抑制、静默等功能防止告警风暴。
支持静态文件配置和动态发现等自动发现机制,目前已经支持了Kubernetes、etcd、Consul等多种服务发现机制,这样可以大大减少容器发布过程中手动配置的工作量。
开放性。Prometheus的client library的输出格式不仅支持Prometheus的格式化数据,还可以在不使用Prometheus的情况下输出支持其他监控系统(比如Graphite)的格式化数据。
Prometheus也存在一些局限性,主要包括如下方面:
Prometheus主要针对性能和可用性监控,不适用于针对日志(Log)、事件(Event)、调用链(Tracing)等的监控。
Prometheus关注的是近期发生的事情,而不是跟踪数周或数月的数据。因为大多数监控查询及告警都针对的是最近(通常不到一天)的数据。Prometheus认为最有用的数据是最近的数据,监控数据默认保留15天。
本地存储有限,存储大量的历史数据需要对接第三方远程存储。
采用联邦集群的方式,并没有提供统一的全局视图。
Prometheus的监控数据并没有对单位进行定义。
Prometheus对数据的统计无法做到100%准确,如订单、支付、计量计费等精确数据监控场景。
Prometheus默认是拉模型,建议合理规划网络,尽量不要转发。
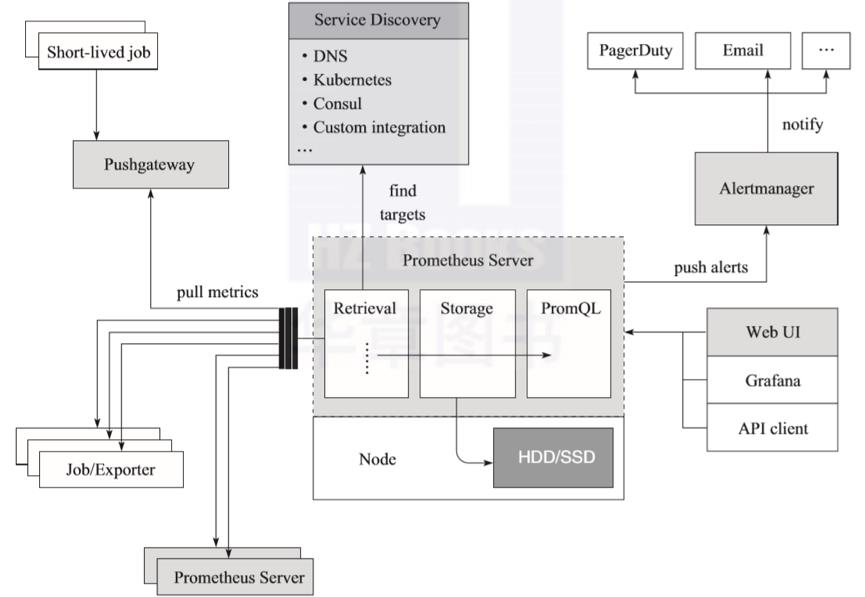
Prometheus的架构如图3所示,它展现了Prometheus内部模块及相关的外围组件之间的关系。
如图3所示,Prometheus主要由Prometheus Server、Pushgateway、Job/Exporter、Service Discovery、Alertmanager、Dashboard这6个核心模块构成。Prometheus通过服务发现机制发现target,这些目标可以是长时间执行的Job,也可以是短时间执行的Job,还可以是通过Exporter监控的第三方应用程序。被抓取的数据会存储起来,通过PromQL语句在仪表盘等可视化系统中供查询,或者向Alertmanager发送告警信息,告警会通过页面、电子邮件、钉钉信息或者其他形式呈现。
从上述架构图中可以看到,Prometheus不仅是一款时间序列数据库,在整个生态上还是一套完整的监控系统。对于时间序列数据库,在进行技术选型的时候,往往需要从宽列模型存储、类SQL查询支持、水平扩容、读写分离、高性能等角度进行分析。而监控系统的架构,除了在选型时需要考虑的因素之外,往往还需要考虑通过减少组件、服务来降低成本和复杂性以及水平扩容等因素。
很多企业自己研发的监控系统中往往会使用消息队列Kafka和Metrics parser、Metrics process server等Metrics解析处理模块,再辅以Spark等流式处理方式。应用程序将Metric推到消息队列(如Kafaka),然后经过Exposer中转,再被Prometheus拉取。之所以会产生这种方案,是因为考虑到有历史包袱、复用现有组件、通过MQ(消息队列)来提高扩展性等因素。这个方案会有如下几个问题:
增加了查询组件,比如基础的sum、count、average函数都需要额外进行计算。这一方面多了一层依赖,在查询模块连接失败的情况下会多提供一层故障风险;另一方面,很多基本的查询功能的实现都需要消耗资源。而在Prometheus的架构里,上述这些功能都是得到支持的。
抓取时间可能会不同步,延迟的数据将会被标记为陈旧数据。如果通过添加时间戳来标识数据,就会失去对陈旧数据的处理逻辑。
Prometheus适用于监控大量小目标的场景,而不是监控一个大目标,如果将所有数据都放在Exposer中,那么Prometheus的单个Job拉取就会成为CPU的瓶颈。这个架构设计和Pushgateway类似,因此如果不是特别必要的场景,官方都不建议使用。
缺少服务发现和拉取控制机制,Prometheus只能识别Exposer模块,不知道具体是哪些target,也不知道每个target的UP时间,所以无法使用Scrape_*等指标做查询,也无法用scrape_limit做限制。
对于上述这些重度依赖,可以考虑将其优化掉,而Prometheus这种采用以拉模式为主的架构,在这方面的实现是一个很好的参考方向。同理,很多企业的监控系统对于cmdb具有强依赖,通过Prometheus这种架构也可以消除标签对cmdb的依赖。
Job/Exporter属于Prometheus target,是Prometheus监控的对象。
Job分为长时间执行和短时间执行两种。对于长时间执行的Job,可以使用Prometheus Client集成进行监控;对于短时间执行的Job,可以将监控数据推送到Pushgateway中缓存。
Prometheus收录的Exporter有上千种,它可以用于第三方系统的监控。Exporter的机制是将第三方系统的监控数据按照Prometheus的格式暴露出来,没有Exporter的第三方系统可以自己定制Exporter,这在后面的章节会详细描述。Prometheus是一个白盒监视系统,它会对应用程序内部公开的指标进行采集。假如用户想从外部检查,这就会涉及黑盒监控,Prometheus中常用的黑盒Exporter就是blackbox_exporter。blackbox_exporter包括一些现成的模块,例如HTTP、TCP、POP3S、IRC和ICMP。blackbox.yml可以扩展其中的配置,以添加其他模块来满足用户的需求。blackbox_exporter一个令人满意的功能是,如果模块使用TLS/SSL,则Exporter将在证书链到期时自动公开,这样可以很容易地对即将到期的SSL证书发出告警。
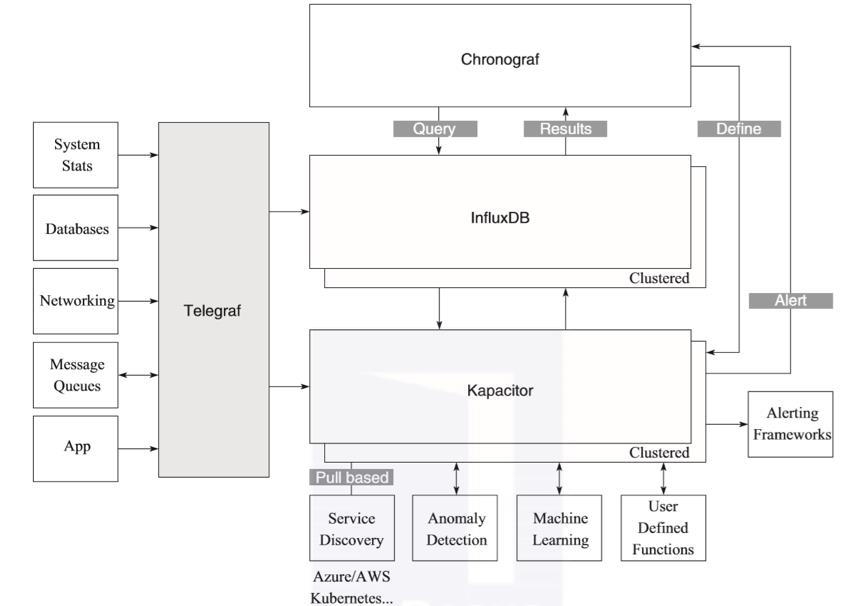
Exporter种类繁多,每个Exporter又都是独立的,每个组件各司其职。但是Exporter越多,维护压力越大,尤其是内部自行开发的Agent等工具需要大量的人力来完成资源控制、特性添加、版本升级等工作,可以考虑替换为Influx Data公司开源的Telegraf?统一进行管理。Telegraf是一个用Golang编写的用于数据收集的开源Agent,其基于插件驱动。Telegraf提供的输入和输出插件非常丰富,当用户有特殊需求时,也可以自行编写插件(需要重新编译),它在Influx Data架构中的位置如图4所示。
图4 Telegraf在Influx Data架构中的位置示意图
Telegraf就是Influx Data公司的时间序列平台TICK(一种高性能时序中台)技术栈中的“T”,主要用于收集时间序列型数据,比如服务器CPU指标、内存指标、各种IoT设备产生的数据等。Telegraf支持各种类型Exporter的集成,可以实现Exporter的多合一。还有一种思路就是通过主进程拉起多个Exporter进程,仍然可以跟着社区版本进行更新。
Telegraf的CPU和内存使用率极低,支持几乎所有的集成监控和丰富的社区集成可视化,如Linux、Redis、Apache、StatsD、Java/Jolokia、Cassandra、mysql
Prometheus是拉模式为主的监控系统,它的推模式就是通过Pushgateway组件实现的。Pushgateway是支持临时性Job主动推送指标的中间网关,它本质上是一种用于监控Prometheus服务器无法抓取的资源的解决方案。它也是用Go语言编写的,在Apache 2.0许可证下开源。
Pushgateway作为一个独立的服务,位于被采集监控指标的应用程序和Prometheus服务器之间。应用程序主动推送指标到Pushgateway,Pushgateway接收指标,然后Pushgateway也作为target被Prometheus服务器抓取。它的使用场景主要有如下几种:
应用程序与Prometheus服务器之间有网络隔离,如安全性(防火墙)、连接性(不在一个网段,服务器或应用程序仅允许特定端口或路径访问)。
Pushgateway与网关类似,在Prometheus中被建议作为临时性解决方案,主要用于监控不太方便访问到的资源。它会丢失很多Prometheus服务器提供的功能,比如UP指标和指标过期时进行实例状态监控。
Pushgateway的一个常见问题是,它存在单点故障问题。如果Pushgateway从许多不同的来源收集指标时宕机,用户将失去对所有这些来源的监控,可能会触发许多不必要的告警。
使用Pushgateway时需要记住的另一个问题是,Pushgateway不会自动删除推送给它的任何指标数据。因此,必须使用Pushgateway的API从推送网关中删除过期的指标。
Curl -X DELETE http://pushgateway.example.org:9091/metrics/job/some_job/instance/ some_instance
Pushgateway还有防火墙和NAT问题。推荐做法是将Prometheus移到防火墙后面,让Prometheus更加接近采集的目标。
注意,Pushgateway会丧失Prometheus通过UP监控指标检查实例健康状况的功能,此时Prometheus对应的拉状态的UP指标只是针对单Pushgateway服务的。
作为下一代监控系统的首选解决方案,Prometheus通过服务发现机制对云以及容器环境下的监控场景提供了完善的支持。
除了支持文件的服务发现(Prometheus会周期性地从文件中读取最新的target信息)外,Prometheus还支持多种常见的服务发现组件,如Kubernetes、DNS、Zookeeper、Azure、EC2和GCE等。例如,Prometheus可以使用Kubernetes的API获取容器信息的变化(如容器的创建和删除)来动态更新监控对象。
对于支持文件的服务发现,实践场景下可以衍生为与自动化配置管理工具(Ansible、Cron Job、Puppet、SaltStack等)结合使用。
通过服务发现的方式,管理员可以在不重启Prometheus服务的情况下动态发现需要监控的target实例信息。服务发现中有一个高级操作,就是Relabeling机制。Relabeling机制会从Prometheus包含的target实例中获取默认的元标签信息,从而对不同开发环境(测试、预发布、线上)、不同业务团队、不同组织等按照某些规则(比如标签)从服务发现注册中心返回的target实例中有选择性地采集某些Exporter实例的监控数据。
相对于直接使用文件配置,在云环境以及容器环境下我们更多的监控对象都是动态的。实际场景下,Prometheus作为下一代监控解决方案,更适合云及容器环境下的监控需求,在服务发现过程中也有很多工作(如Relabeling机制)可以加持。
Prometheus服务器(Prometheus Server)
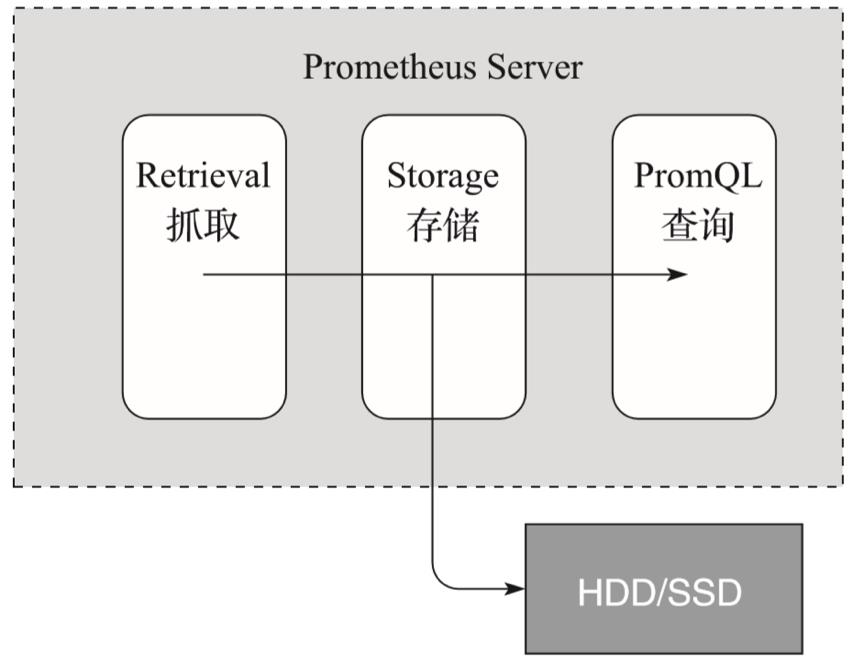
Prometheus服务器是Prometheus最核心的模块。它主要包含抓取、存储和查询这3个功能,如图5所示。
抓取:Prometheus Server通过服务发现组件,周期性地从上面介绍的Job、Exporter、Pushgateway这3个组件中通过HTTP轮询的形式拉取监控指标数据。
存储:抓取到的监控数据通过一定的规则清理和数据整理(抓取前使用服务发现提供的relabel_configs方法,抓取后使用作业内的metrics_relabel_configs方法),会把得到的结果存储到新的时间序列中进行持久化。多年来,存储模块经历了多次重新设计,Prometheus 2.0版的存储系统是第三次迭代。该存储系统每秒可以处理数百万个样品的摄入,使得使用一台Prometheus服务器监控数千台机器成为可能。使用的压缩算法可以在真实数据上实现每个样本1.3B。建议使用SSD,但不是严格要求。
Prometheus的存储分为本地存储和远程存储。
本地存储:会直接保留到本地磁盘,性能上建议使用SSD且不要保存超过一个月的数据。记住,任何版本的Prometheus都不支持NFS。一些实际生产案例告诉我们,Prometheus存储文件如果使用NFS,则有损坏或丢失历史数据的可能。
远程存储:适用于存储大量的监控数据。Prometheus支持的远程存储包括OpenTSDB、InfluxDB、Elasticsearch、Graphite、CrateDB、Kakfa、PostgreSQL、TimescaleDB、TiKV等。远程存储需要配合中间层的适配器进行转换,主要涉及Prometheus中的remote_write和remote_read接口。在实际生产中,远程存储会出现各种各样的问题,需要不断地进行优化、压测、架构改造甚至重写上传数据逻辑的模块等工作。
查询:Prometheus持久化数据以后,客户端就可以通过PromQL语句对数据进行查询了。后面会详细介绍PromQL的功能。
在Prometheus架构图中提到,Web UI、Grafana、API client可以统一理解为Prometheus的Dashboard。Prometheus服务器除了内置查询语言PromQL以外,还支持表达式浏览器及表达式浏览器上的数据图形界面。实际工作中使用Grafana等作为前端展示界面,用户也可以直接使用Client向Prometheus Server发送请求以获取数据。
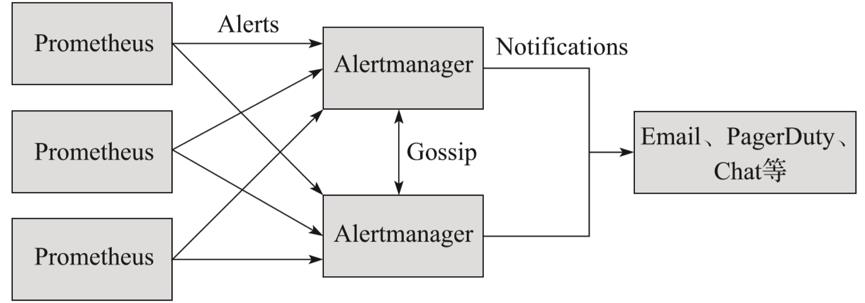
Alertmanager是独立于Prometheus的一个告警组件,需要单独安装部署。Prometheus可以将多个Alertmanager配置为一个集群,通过服务发现动态发现告警集群中节点的上下线从而避免单点问题,Alertmanager也支持集群内多个实例之间的通信,如图6所示。
图6 Prometheus Alertmanager集群
Alertmanager接收Prometheus推送过来的告警,用于管理、整合和分发告警到不同的目的地。Alertmanager提供了多种内置的第三方告警通知方式,同时还提供了对Webhook通知的支持,通过Webhook用户可以完成对告警的更多个性化的扩展。Alertmanager除了提供基本的告警通知能力以外,还提供了如分组、抑制以及静默等告警特性。
本文节选自《Prometheus云原生监控:运维与开发实战》,经出版社授权发布。为了感谢粉丝的支持特意送出6本此书作为福利。欢迎大家在留言区谈谈
使用Prometheus的心得,截止2020年12月8日12时,精选留言点赞前6名,各送出此书一本!没中奖的同学可以点击下方链接购买。