(2021-05-28)JVM概览学习
Posted Mr. Dreamer Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(2021-05-28)JVM概览学习相关的知识,希望对你有一定的参考价值。
面试准备,jvm也需要再回顾一下。
目录
5.2 Parallel Scavenge(PS)—Parallel Old(PO)
1.什么是JVM
JVM应该是我们平时很难实际接触到,但是面试又很容易问到的一个知识点了。首先,简单的介绍一下JVM。JVM(Java Virtual Machine),是一个跨平台的工具。不光java,c++以及Python等语言也是适用的,而且不光在Windows平台,linux等平台也是适用的。
而在我看来,JVM就是一个“翻译器”,为什么说它是“翻译器”呢?下面用一张图,来直观的感受一下
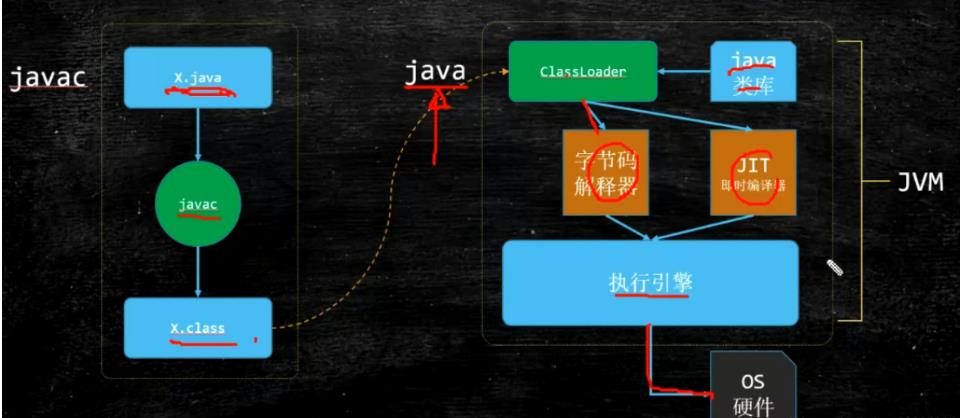
在我们.java文件运行之后(通过javac执行之后),会变成.class文件。而字节码文件(.class)是JVM能够识别并且处理的文件。
简单的来过一下流程,类加载器将字节码文件,java类库进行加载,然后通过字节码解释器来读对应的代码,以及通过JIT将其解析成为本机的机器码,让后通过执行引擎对机器码进行执行(机器码也就是二进制语言:010111)
2.JVM的组成
JVM是由 类加载子程序,运行时数据区,执行引擎 这三部分组成。
2.1 类加载子程序
它的过程简单来讲就是:加载.class文件到内存,并对数据进行校验,解析和初始化。最后让它形成可以被虚拟机直接使用的类型。
详细点来说的话,分为5个步骤
加载、验证、准备、解析、初始化
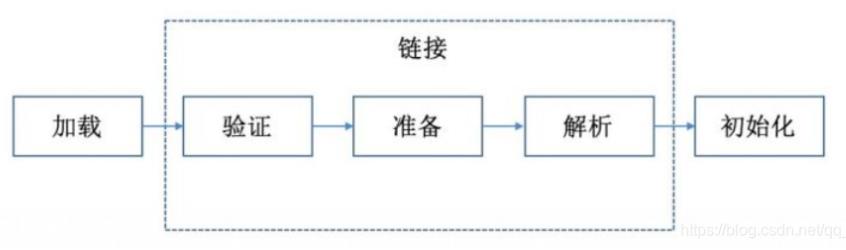
1.加载
其实就是通过类加载器把字节码文件(.class)加载到内存中,以及java对应的核心库等数据源
什么是类加载器呢?——实现通过类的权限定名获取该类的二进制字节流的代码块
常见的四种类型加载器:
- 启动加载器:用来加载java核心类库,无法被java程序直接引用的
- 扩展加载器:它用来加载java的扩展库
- 系统加载器:根据java应用的类路径来加载java类
- 用户自定义类加载器:通过继承java.lang.ClassLoader类的方式实现
2.验证
主要为了确保class文件的字节流中的信息不会危害的虚拟机,或者说导致虚拟机无法正确的执行操作。具体有四种验证:
- 文件格式验证:验证字节流是否符合class文件规范
- 元数据验证:对对接描述的信息进行分析,比如这类是否继承了父类,是否继承了不能被继承的类等
- 元数据验证:验证程序语义是否正确,只要针对方法体的验证。比如:方法中的类型转化等
- 符号引用验证:确保解析操作能够正确执行。(将符号引用解析为直接引用)
3.准备
主要为类变量(在类中被static修饰的变量属于“类”,成为类变量)进行内存分配
4.解析
将常量池中的符号引用替换为直接引用的过程。
例如:A类引用了B类,但是在JVM编译之前,并不知道B类的内存地址。所以用一个符号来替代。
- 符号引用:即一个字符串,但是这个字符串给出了一些能够进行唯一识别的方法。
- 直接引用:可以理解为内存地址。
5.初始化
这个阶段主要对类变量初始化,是执行类构造器的过程。
换句话说,对static修饰的变量或者语句进行初始化
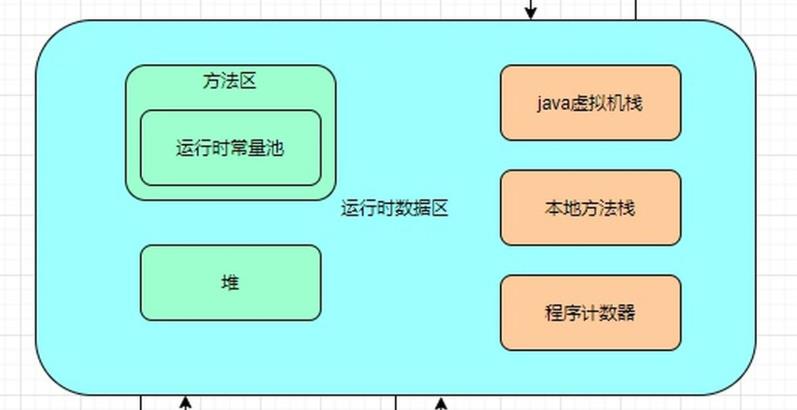
2.2 运行时数据区
运行时数据区可以说是在针对jvm面试题中,最最重要的部分
运行时数据区分为线程私有数据和线程共享数据
1. 线程私有数据
线程私有数据,顾名思义,其实就是每个线程私有的数据。不能被其他线程使用,别人也不清楚的数据。
线程私有数据又由这三部分组成:程序计数器,虚拟机栈,本地方法栈
程序计数器
定义:正指向单线程正在执行的字节码指令行号
大家可以思考一下,它的作用是啥。
java天生就是多线程,那么肯定意味着会进行线程切换。而程序计数器就是保证切换回来之后,每个线程能够知道它应该从哪开始继续执行。
本地方法栈
既然都说到这里了,那么就简单提一下堆和栈的区别。
- 堆:先进先出,需要申请才会开辟空间,空间大
- 栈:先进后出,由系统直接分配,空间小
定义:用来存放native方法的地方。也就是基于非java语言的开发,比如synchronized等无法直接查看底层实现逻辑的方法(当然,我说的是无法直接看到的),使用native修饰的方法!
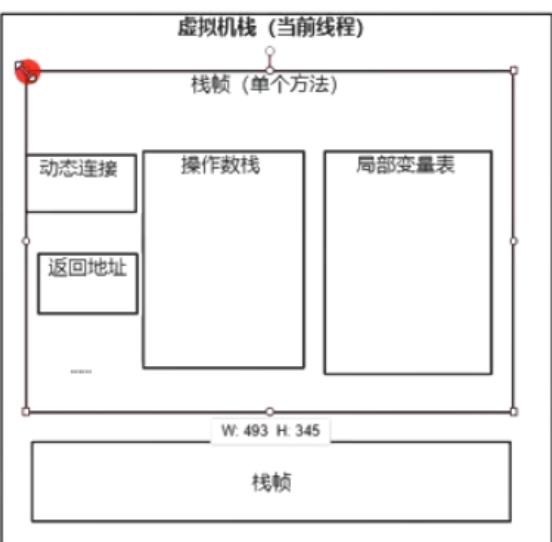
虚拟机栈
定义:每个线程独享的内存空间。存放当前线程的数据,指令以及返回地址信息等
其实从这张图就可以看出来,虚拟机栈就是存放栈帧的地方(每个方法都会生成一个栈帧,栈帧中存放这个方法对应的的数据信息等)
2.线程共享数据
线程共享数据分为:堆和方法区(运行时常量池也在其中)
当然了,对于方法区有不同的叫法。1.7的时候被称为永久代,1.8被称为元空间。大家了解就行了,知道它实际上是干嘛的才是重点
堆
定义:一般用来存放实例化的对象的地址,以及成员变量,数组等
方法区
定义:用于存储已经被虚拟机加载的类信息,常量以及静态变量等数据
我之前笔试的时候遇过到对于不同区域存放的数据的考察,下面总结一下,也方便大家记忆
- 方法区:主要存放类信息,常量池(static final常量和static变量,以及String str=“abc”)
- 堆:实例对象(new XXX),成员变量(非static变量),所有数组
这里说一下jvm、jre和jdk的关系吧,如下图
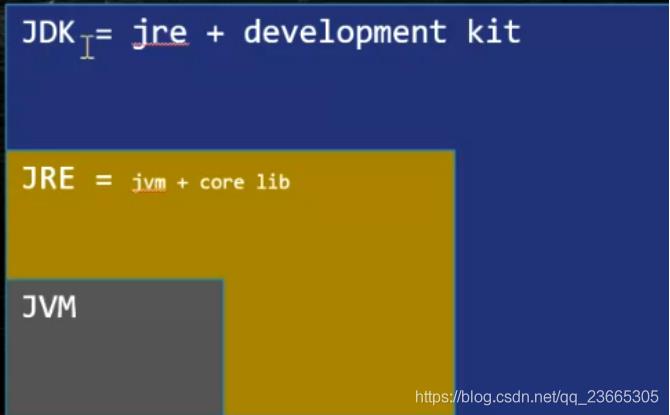
这里有个面试题,如果需要跑一个简单的Java代码,需要安装到哪种程度——JRE
2.3 执行引擎
简单总结一下执行引擎,知道就行了
执行引擎得到对应的机器码,然后将其机器码进行执行
3. GC
我们先了解一下什么是GC,GC(garbage collection)——垃圾回收。为的就是释放有限的内存空间,让接下来的对象能够被安排内存空间。
注意:GC是JVM自动操作的,和你在java程序里面调用没毛线关系的。
3.1 GC的判断方法
1.引用计数法
简单来说就是用到了这个对象,就对着对象就+1,没用就-1.为0则代表可以进行回收了。(但是JVM中并没有使用这个方式,因为无法解决循环引用的问题)
2.跟可达法
以一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链(不可达)时,证明此对象不可用了。
例如:扔线团,一个线团连着一个线团,如果能顺着最后那个线团发现你最开始扔的那个线团,那么说明根可达。不能被回收。
https://blog.csdn.net/G_66_hero/article/details/86513625 这篇帖子我感觉说明很形象
3.2 GC ROOT
gc root这个听起来高大上,其实就是GC不能回收的对象的内存空间。简单来说,就是TM的关系户,不受管控。
关系户如下:
1.虚拟机栈中的引用对象(局部变量)
2.方法区中的常量和静态变量的引用对象
3.本地方法栈中的引用对象
3.2 内存泄漏和内存溢出
这个知识点应该是问的很多,而且很容易搞混的
- 内存溢出:需要分配空间发现内存不够了(这里分享一个我的联想记忆方式:溢出,为什么会溢出。你正在向一个大杯子里面倒水。你本来是想把一个小杯子的水全部倒进大杯子,但是由于大杯子原来就有水了,没办法接收你小杯子中所有的水,你如果非要全部倒入,那么多余的水就溢出来了。)
- 内存泄漏:一个已经被分配的内存空间的对象已经不需要再被使用了,但是没办法回收(你占了这个地方,你没用了,但是没办法把你丢出去),通常出现在长生命周期引用了短生命周期的对象
4.分代机制
垃圾回收机制主要出现在新生代和老年代(也叫终生代)。
分代的原因:就是为了优化GC的性能。
试想一下,如果没有分代,所有的对象都在一起,GC开始全局扫描,麻烦。
新生代和老年代的占空间比例是1:2(可以自己调整大小)
- 新生代:Minor GC
- 老年代:Major GC
- 新生代和老年代:Full GC
注意:这里说的分代是都是基于堆的,不要搞错了!!!!

4.1 新生代
新生代分为eden区、from区、to区(from和to也被成为survivor1,survivor2或者survivor0,survivor1)
eden区(伊甸园,万物生产的地方)。通常来说,基本上对象都会先到这个地方(除非特别大的对象,因为新生代可能没办法负担它的空间,导致它直接进入老年代)
对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。如果还未到相应“年龄”,那么进入"To"区。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。总之,始终保证其中一个区域为空。
通常发生15次GC还没被回收的成为“老不死”,进入老年代。
复制算法
在新生代中,使用的垃圾回收算法是 复制算法。
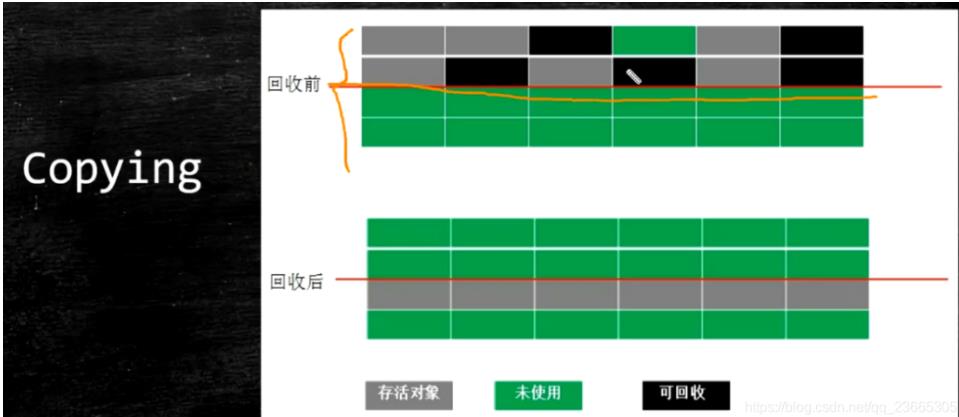
之前有的同学可能会问,为什么from和to区始终有一个为空。我的理解其实这就是复制算法的体现。
简单来说,就是先将空间一分为二,每次只用其中一个。当这块内存快用完了,将还需要存活的对象放到另一块区域去,然后将之前这块区域的数据一次性清除。
- 优点:速度快,没有内存碎片
- 缺点:空间折半
这里提一句,虽然折半空间会导致使用的空间变小,但是其实并没有多大的影响。这是因为新生代的对象基本上都是“朝生夕死”的状态,通常存活下来的对象不足5%-10%,所以基本不用考虑空间的使用情况。
4.2 老年代
通常来说,当新生代超过15次GC都没有被回收的数据,进入老年代。
老年代通常使用两种垃圾回收算法
1.标记清理
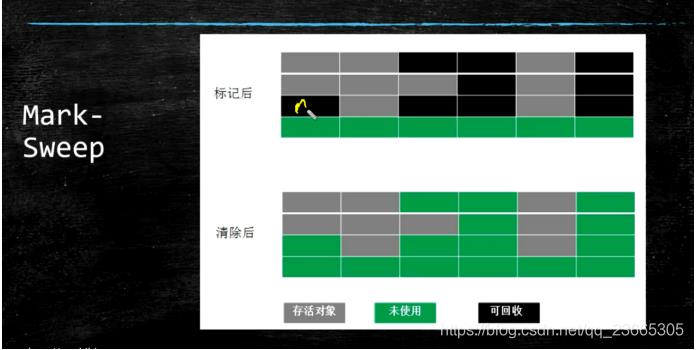
其实由图就可以知道它的优缺点了
优点:速度快
缺点:有内存碎片(不利于分配大内存的对象)
2.标记整理
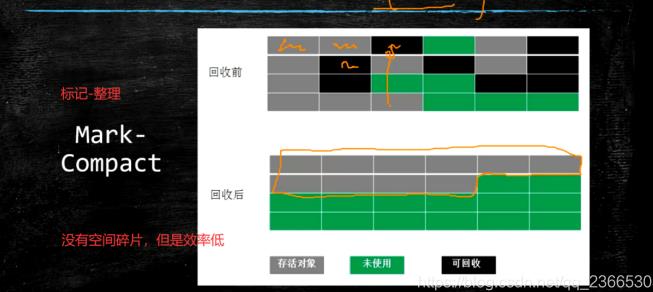
- 优点:不会产生内存碎片
- 缺点:由于需要清理之后进行整理,所以速度慢
5.垃圾回收器
现在基本上提到JVM,面试官总会多多少少问问你垃圾回收器的问题。迫于生活压力,我也对这方面进行了一个了解。老规矩,先上个图吧
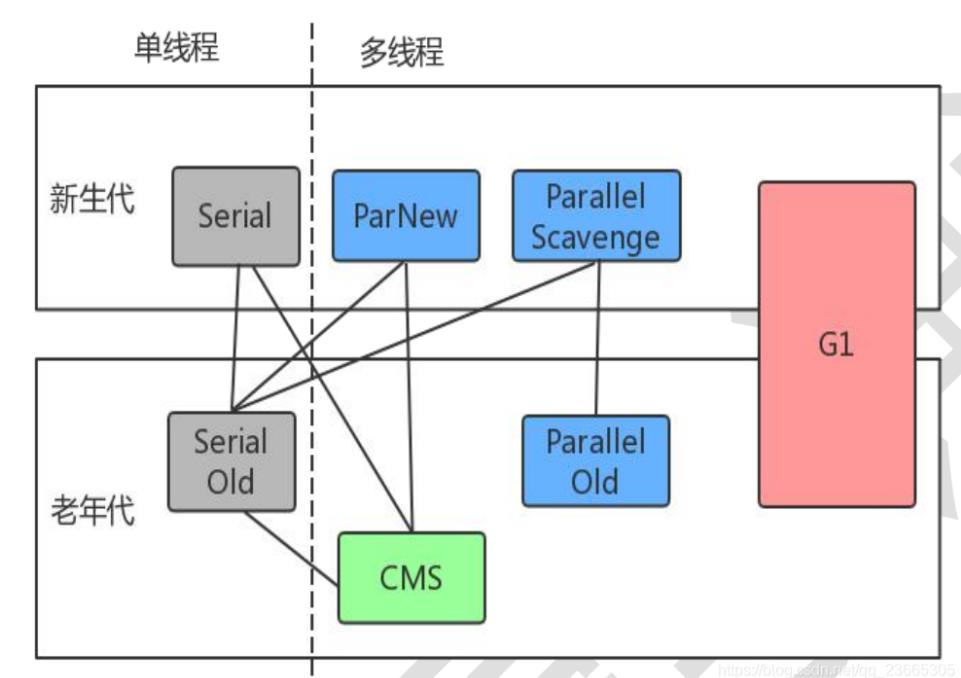
其实如上图可知,我们现目前常用的垃圾回收期以及它所处于的分代中。
先配对吧
serial - serial Old(单线程)
parNew - CMS
Parallel Scavenge(PS)—Parallel Old(PO)
这里先说明一下,我不会每个垃圾回收器都去详细的讲解,只会让大家有一个大致的了解。
5.1 serial - serial old
最最老的垃圾回收器
单线程,很耗时

在解释之前,我们先了解一下什么叫做 stop-the-world(stw)
先说下它的意思吧,“停下来”!!! 记住,现目前绝大多数垃圾回收器都会有这个操作
举个例子吧:一群小盆友在一个房间里面玩耍,在撕纸或者乱扔东西。但是过了一段时间之后,发现地上都要扔满了。这时候,男保姆来了,他要开始打扫卫生了,为了清理这些垃圾。他强制所有小朋友不允许再丢垃圾了,什么都不准做了,安静的呆着。过了一会,等他打扫完了,清理干净了。小朋友们才继续“玩耍”。
它有一个很大的缺点:就是效率很低。在清理的时候会造成停止的现象,会对性能造成很大的伤害。
serial old 这里就不去多说了,和serial差不多。只是它是基于老年代的垃圾回收器
5.2 Parallel Scavenge(PS)—Parallel Old(PO)
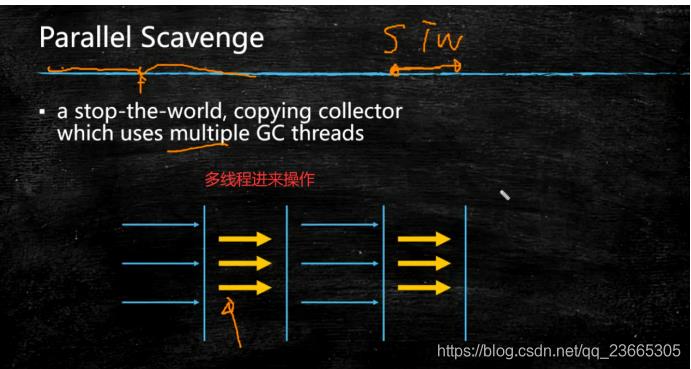
其实如图可见,它和serial其实没啥区别,依然会STW。只是它升级了,用了多线程,让停止的时间尽量减少一些
5.3 parNew—CMS
parNew,这个垃圾回收期和PS其实没啥本质上的区别。
我们来详细说一下CMS,为什么面试官很喜欢问CMS呢?其实就是因为CMS有一个承上启下的作用,虽然说CMS有很多的问题哈,但是现在很火的G1就是建立在它的基础上,进行了修改。
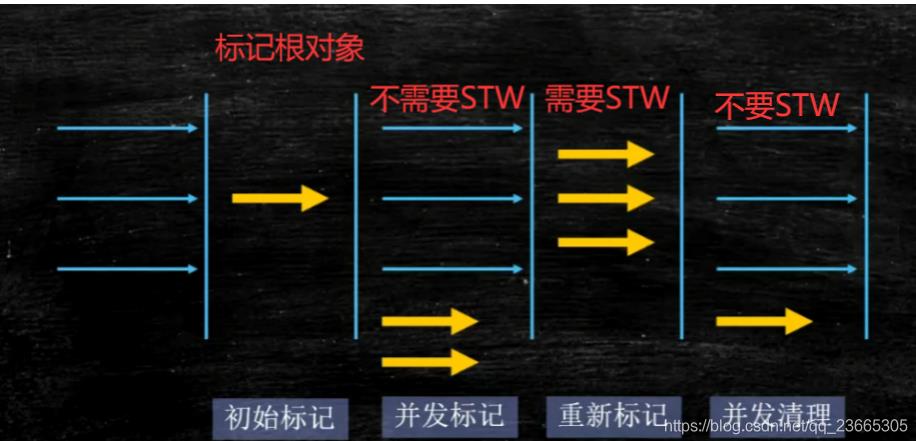
老规矩,上图之后我们来看看它的回收过程
初始标记:速度很快。只标记GC Root直接关联到的对象,需要STW
并发标记:标记和清理共同进行,不需要停止(比较耗时)
重新标记:需要STW。但是由于之前已经标记过了,所以这次时间不会很长,遗漏标记的会很少
并发清理:不需要STW。清理和产生对象一起进行
- 优点:
- 由于加入了并发收集,少停顿,所以时间快;
- 缺点:
- 大量的并发操作会占用大量的cpu资源
- 产生浮动垃圾。简单点来说,由于清理的同时也会伴随着垃圾的不断产生,所以说有些只能放到下一次清理。这就意味着,需要留出一些空间来存放这些“浮动垃圾”。但是由于它的并发机制,清理垃圾和产生垃圾同时进行,可能会导致无法保证某些“浮动垃圾”的空间存放。出现这种情况,它会临时使用SO(serial old)来替代CMS(注意看那张图的连接线)
- 由于使用的是标记清理算法,会导致大量的内存碎片
ok,到这里。大家先去消化一下。我们接下来会有重头戏 G1
5.4 G1
G1垃圾收集器的G1其实是Garbage First。但是并不是垃圾优先的意思,而是优先处理那些垃圾多的内存块的意思。
CMS和G1通常来说,是面试最容易问到的垃圾回收器。一般来说。你的简历上写了解JVM,问到你垃圾回收器,回答上这个几个就够了。S和SO,PS和PO,CMS和ParNew以及G1
G1是现在很多JVM调优常使用的一个垃圾回收器,
我们先来看看G1做出的改变
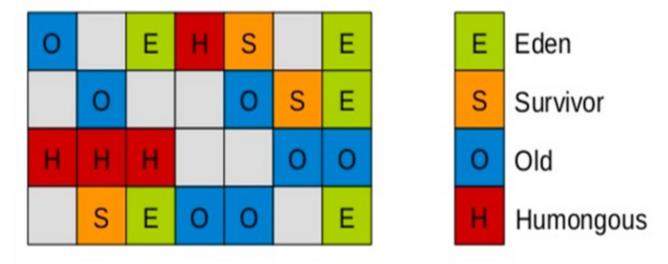
内存布局改变
G1把堆划分成多个大小相等的独立区域(region),新生代和老年代不再物理隔离。这个是和CMS较大的区别了。而且G1更厉害的是,它可以预测停顿的功能(一个为M毫米的时间片中,清理垃圾的时间不超过N毫秒)
- 划分多个大小相等的好处:内存块的粒度变小了,从而可以垃圾回收工作更彻底的并行化。
算法
标记整理算法(老年代Old,Humongous(庞大的:如果一个对象的大小占用了超过分区50%))
复制算法(新生代Survivor)
GC 模式
Young GC
选定所有新生代中的region。通过控制新生代的region个数,即新生代内存大小,来控制young gc的时间开销(复制回收算法)
Mixed GC
选定新生代中所有的region,外加根据global concurrent marking统计得出收集收益高的若干老年代的region(标记整理)
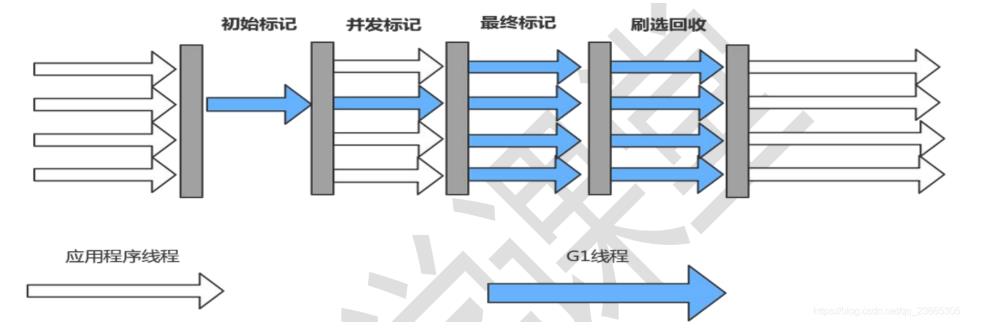
G1运作步骤:
1、初始标记(stop the world事件 CPU停顿只处理垃圾);
2、并发标记(与用户线程并发执行);
3、最终标记(stop the world事件 ,CPU停顿处理垃圾);
4、筛选回收(stop the world事件 根据用户期望的GC停顿时间回收)
特点
- 空间整合:不会产生内存碎片(使用了标记整理算法)
- 可预测停顿:G1之所有能够预测停顿,就是因为它可以有计划的避免整个java堆中进行全区域的垃圾回收。G1跟踪各个region里面的垃圾堆积的价值大小(回收所获得的的空间大小以及回收所需要的时间)。而且到底回收多少内存就看用户配置的暂停时间,配置的时间短就少回收点,配置的时间长就多回收点,伸缩自如
以上是关于(2021-05-28)JVM概览学习的主要内容,如果未能解决你的问题,请参考以下文章