聊聊 Prometheus Operator
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊 Prometheus Operator相关的知识,希望对你有一定的参考价值。

一方面吧,它生态特别好:作为 Kubernetes 监控的事实标准,(几乎)所有 Kubernetes 相关组件都暴露了 Prometheus 的指标接口,甚至在 Kubernetes 生态之外,绝大部分传统中间件(比如 mysql、Kafka、Redis、ES)也有社区提供的 Prometheus Exporter。我们已经可以去掉 Kubernetes 这个定语,直接说 Prometheus 是开源监控方案的”头号种子选手”了;
另一方面吧,都 2019 年了,一个基础设施领域的“头号种子”选手居然还不支持分布式、不支持数据导入/导出、甚至不支持通过 API 修改监控目标和报警规则,这是不是也挺匪夷所思的?
Alertmanager:定义一个 Alertmanager 集群;
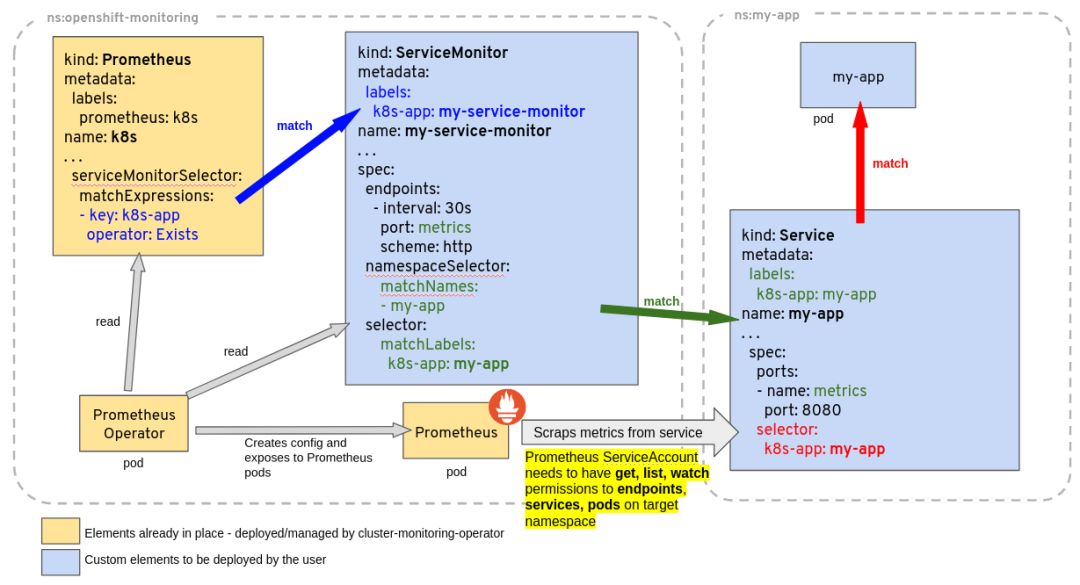
ServiceMonitor:定义一组 Pod 的指标应该如何采集;
PrometheusRule:定义一组 Prometheus 规则;
Prometheus:定义一个 Prometheus “集群”,同时定义这个集群要使用哪些 ServiceMonitor 和 PrometheusRule。
kind: Alertmanager ➊
metadata:
name: main
spec:
baseImage: quay.io/prometheus/alertmanager
replicas: 3 ➋
version: v0.16.0
➊ 一个 Alertmanager 对象
➋ 定义该 Alertmanager 集群的节点数为 3
kind: Prometheus
metadata: # 略
spec:
alerting:
alertmanagers:
- name: alertmanager-main ➊
namespace: monitoring
port: web
baseImage: quay.io/prometheus/prometheus
replicas: 2 ➋
ruleSelector: ➌
matchLabels:
prometheus: k8s
role: alert-rules
serviceMonitorNamespaceSelector: {} ➍
serviceMonitorSelector: ➎
matchLabels:
k8s-app: node-exporter
query:
maxConcurrency: 100 ➏
version: v2.5.0
➊ 定义该 Prometheus 对接的 Alertmanager 集群名字为 main,在 monitoring 这个 namespace 中;
➋ 定义该 Proemtheus “集群”有两个副本,说是集群,其实 Prometheus 自身不带集群功能,这里只是起两个完全一样的 Prometheus 来避免单点故障;
➌ 定义这个 Prometheus 需要使用带有 prometheus=k8s 且 role=alert-rules 标签的 PrometheusRule;
➍ 定义这些 Prometheus 在哪些 namespace 里寻找 ServiceMonitor,不声明则默认选择 Prometheus 对象本身所处的 Namespace;
➎ 定义这个 Prometheus 需要使用带有 k8s-app=node-exporter 标签的 ServiceMonitor,不声明则会全部选中;
➏ 定义 Prometheus 的最大并发查询数为 100,几乎所有配置都可以通过 Prometheus 对象进行声明(包括很重要的 RemoteRead、RemoteWrite),这里为了简洁就不全部列出了。
kind: ServiceMonitor
metadata:
labels:
k8s-app: node-exporter ➊
name: node-exporter
namespace: monitoring
spec:
selector:
matchLabels: ➋
app: node-exporter
k8s-app: node-exporter
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s ➌
targetPort: 9100 ➍
scheme: https
jobLabel: k8s-app
➊ 这个 ServiceMonitor 对象带有 k8s-app=node-exporter 标签,因此会被上面的 Prometheus 选中;
➋ 定义需要监控的 Endpoints,带有 app=node-exporter 且 k8s-app=node-exporter 标签的 Endpoints 会被选中;
➌ 定义这些 Endpoints 需要每 30 秒抓取一次;
➍ 定义这些 Endpoints 的指标端口为 9100;
kind: PrometheusRule
metadata:
labels: ➊
prometheus: k8s
role: alert-rules
name: prometheus-k8s-rules
spec:
groups:
- name: k8s.rules
rules: ➋
- alert: KubeletDown
annotations:
message: Kubelet has disappeared from Prometheus target discovery.
expr: |
absent(up{job="kubelet"} == 1)
for: 15m
labels:
severity: critical
➊ 定义该 PrometheusRule 的 label,显然它会被上面定义的 Prometheus 选中;
➋ 定义了一组规则,其中只有一条报警规则,用来报警 kubelet 是不是挂了。
那么 Prometheus 做配置热更新的时候就会失败,假如配置更新失败没有报警,那么 Game Over;
热更新失败有报警,但这时 Prometheus 突然重启了,于是配置错误重启失败,Game Over。
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::d+)?;(d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
这个 Prometheus 要针对所有 annotation 中带有 prometheus.io/scrape=true 的 Endpoints 对象,按照 annotation 中的 prometheus.io/port,prometheus.io/scheme,prometheus.io/path 来抓取它们的指标。
复杂:复杂是万恶之源;
没有分离关注点:应用开发者(提供 Pod 的人)必须知道 Prometheus 维护者的配置是怎么编写的,才能正确提供 annotation;
没有 API:更新流程复杂,需要通过 CI 或 Kubernetes ConfigMap 等手段把配置文件更新到 Pod 内再触发 webhook 热更新;
以上是关于聊聊 Prometheus Operator的主要内容,如果未能解决你的问题,请参考以下文章