Facebook有序队列服务设计原理和高性能浅析
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Facebook有序队列服务设计原理和高性能浅析相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨Coder的技术之路
来源丨Coder的技术之路
前言
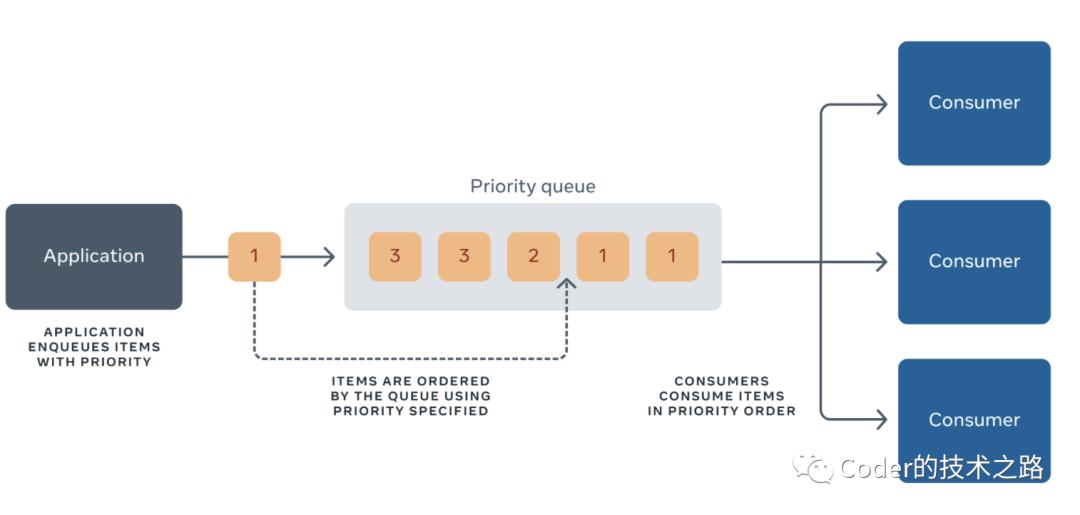
Facebook生态系统是由成千上万的分布式系统和微服务驱动构成的,其中许多服务都得益于异步作业,特别是在在线流量的高峰时期。异步化提供了诸多好处:更有效地利用资源、提高系统可靠性、允许计划执行,以及微服务彼此间可靠通信。实现这些优势都需要一个队列——一个存储作业的地方,允许其异步发生,或者从一个服务传递到另一个服务。facebook有序队列服务FOQS应运而生。
FOQS在Facebook上支持数百个服务,包括:
- Async (Facebook的异步计算平台),是Facebook上广泛使用的通用异步计算平台。它提供了各种功能,从通知到完整性检查,再到为任务计划执行,利用FOQS的能力来存储大量作业的积压,推迟作业运行,从而达到削峰填谷。
- 视频编码服务,支持异步视频编码服务。当视频被上传时,它们被分解成多个组件,每个组件存储在FOQS中,然后进行处理。
- 语言翻译技术,为语言间的帖子翻译提供了支持。这种工作在计算上可能非常昂贵,通过将其分解为多个作业,存储在FOQS中,并由workers并行运行而从并行化中获益。等
facebook engineering[1]
构建分布式优先队列
FOQS的主要能力是存储位于namespace中的topic中的item。它公开了一个Thrift API,包含以下操作:
Enqueue
Dequeue
Ack
Nack
GetActiveTopics
FOQS通过内部服务Shard Manager来管理对主机的分片分配。每个分片分配给一台主机。为了更容易地与其他后端服务通信,FOQS实现了Thrift接口。下面来分别介绍各部分的原理和设计:
Item
item是FOQS中优先队列的消息,其中包含用户指定的数据。一般来说,它由以下字段组成:
Namespace FOQS的多租户单元
Topic 即一个优先队列; 一个 namespace可以包含许多(数千个) topics.
Priority (用户指定的32位整数), 数值越小优先级越高。
Payload 不可变二进制大对象,大小可以到10kb。开发人员可以自由地在这里放置他们想要的任何东西。
Metadata 可变二进制对象。开发人员可以自由地在这里放置他们想要的任何东西。通常,元数据应该只有几百字节。
Dequeue delay — Item应该从队列中退出的时间戳。这也称为deliver_after.
Lease duration 一个Item需要被消费者ACK或者NACK而出队列的持续时间,如果消费者什么都没有做,则FOQS可以根据客户指定的重试策略(至少一次、最多一次和最大重试计数)重新投递Item。
FOQS-assigned unique ID 用于通过API标识一个Item.
TTL 限制Item在队列中的驻留时间。一旦一个Item的生存时间(TTL)被命中,它将被删除。
「FOQS中的每个Item对应于MySQL表中的一行。在进入队列时,会给一个Item分配一个ID。」
topic
一个topic就是一个逻辑优先队列,一般是一个字符串,由用户指定。它包含item,并按它们的优先级和deliver_after值对它们进行排序。主题是廉价且而且是动态变动的,只需将item排队并指定topic标识就可以创建topic。
由于topic是动态的,FOQS为开发人员提供了一个API,通过查询活动topic(至少包含一个item)来发现topic。当一个topic没有更多的item时,它就不再存在。
namespace
一个namespace和一个队列用例相匹配。它是FOQS的多租户单位。每个namespace都有一定的容量保证,以每分钟的队列数量衡量。命名空间可以共享同一列(一列是FOQS主机和mysql分片的集合,为一组命名空间提供服务),且不相互影响。命名空间只映射到一个列。
Enqueue
Enqueues是item进入FOQS的入口。如果成功进入队列,则会执行持久化,最终出队列。
当一个入队请求到达FOQS主机时,请求被缓冲下来并返回一个promise。每个MySQL分片都有一个对应的worker,它从缓冲区中读取item并将它们插入到MySQL中。一个数据库行对应一个item。一旦插入完成(成功或失败),promise就会完成实现,并将队列响应发送回客户机。如下图所示: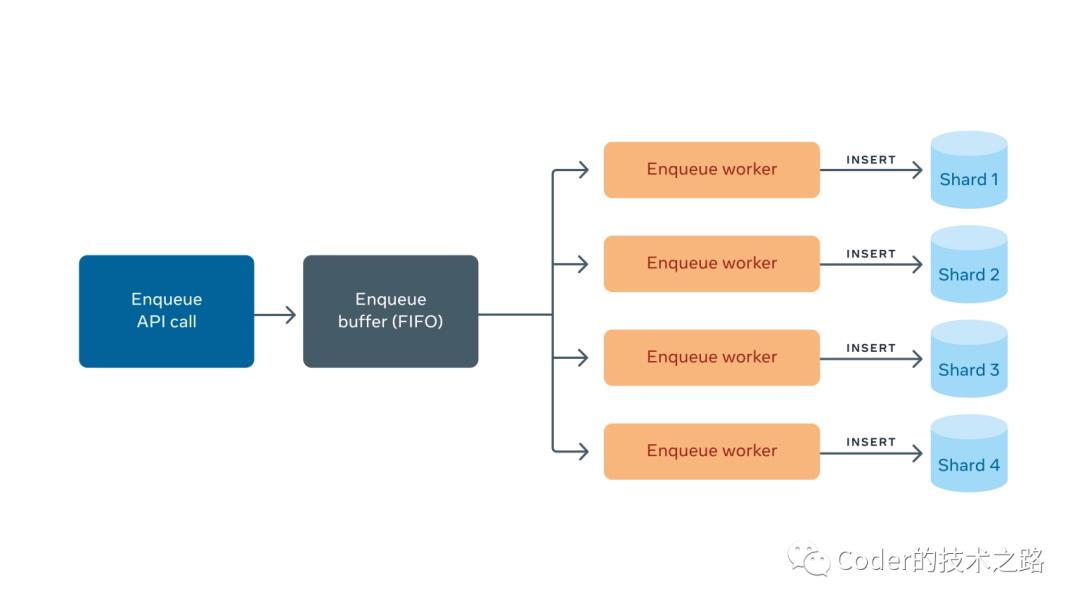 FOQS使用熔断设计模式来标记不健康的分片。其健康状况由慢查询(滚动窗口上平均毫秒数大于 x ms)或错误率(滚动窗口上平均错误数大于x%)定义。如果分片被判定为不健康,worker将停止工作,直到分片健康。这样,FOQS就不会继续向已经不健康的分片添加新item了。
FOQS使用熔断设计模式来标记不健康的分片。其健康状况由慢查询(滚动窗口上平均毫秒数大于 x ms)或错误率(滚动窗口上平均错误数大于x%)定义。如果分片被判定为不健康,worker将停止工作,直到分片健康。这样,FOQS就不会继续向已经不健康的分片添加新item了。
如果插入成功,enqueue API返回一个项目的唯一ID。该ID是一个字符串,包含分片 ID和分片中的64位主键。这种组合唯一地标识了FOQS中的每一项。
Dequeue
dequeue API的入参是(topic, count)的参数对的集合。对于每个topic,FOQS最多会返回对该topic的count个item。这些item是按优先级和deliver_after排序的,因此优先级较低的物品将首先被交付。如果多个item的优先级最低,较低的deliver_after(即较老的)item将首先交付。
队列API允许指定项目的过期期限。当一个item出队列时,它的过期判定也会开始。如果item没有在期限内被ack或被nack,它可以被重投。这是为了避免下游消费者在ack或nack item之前崩溃时丢失item。FOQS支持至少一次和最多一次的投递。如果一个item最多投递一次,则在过期时间到期后将其删除;如果至少一次,将尝试重新投递。
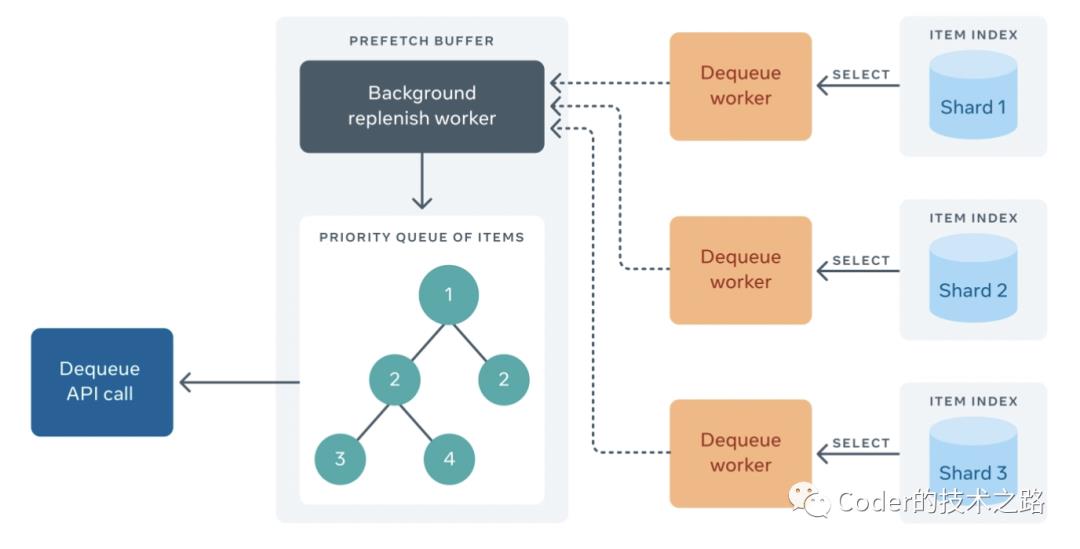
由于FOQS支持优先级,每台主机需要在它关联的分片上做一个reduce操作,以找到优先级最高的item。为了优化,FOQS维护了一个叫做预取缓冲区(Prefetch Buffer)的数据结构,它在后台运行,从所有分片中取优先级最高的item,然后进行缓存,以便客户端从队列中取出。
每个分片维护一个按优先级排序的,准备投递的item主键的 内存索引。该索引被所有可能标记一个item已经准备好投递的操作(如enqueues)进行更新。并允许预取缓冲区通过k-way merge和select查询来高效地找到优先级最高的主键。这些item的状态在数据库中也被更新为“已投递”,避免重复投递。
预取缓冲区(Prefetch Buffer)通过存储每个topic的客户端请求(出队率)来补充自身。预取缓冲区(Prefetch Buffer)将以与客户端请求成比例的速率请求item。快速出队的topic将获得更多的item放入预取缓冲区。
dequeue API只是从预取缓冲区读取项目并将它们返回给客户机:
Ack/Nack
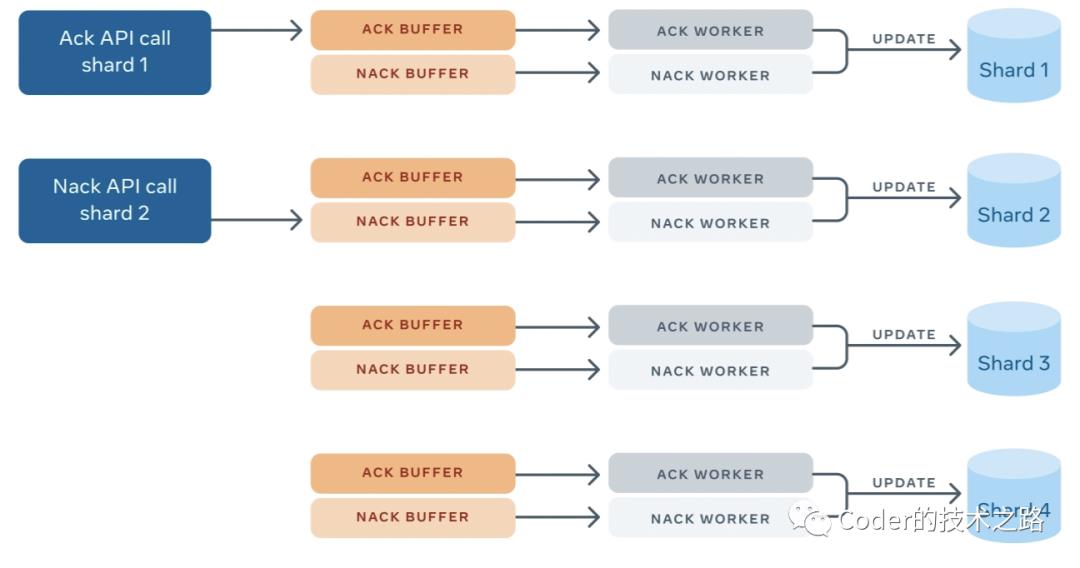
ack表示该item已退出队列并已成功处理,不需要再次发送。
nack表示一个item应该被重新投递,因为客户端需要再次处理。当一个项被NACK时,是可以延迟处理的,允许客户端在处理失败的item时利用指数后退。此外,客户端可以在nack上更新该item的元数据,以便在该item中存储部分结果。
因为每个MySQL分片最多属于一个FOQS主机,一个ack/nack请求需要落在分片对应的主机上。由于shard ID编码在每个item ID中,FOQS客户端使用shard来定位主机。这个映射通过Shard Manager查找。
一旦ack/nack被路由到正确的主机,它就会被发送到特定分片的内存缓冲区。worker从ack缓冲区中取出item,然后从MySQL分片中删除这些行; 类似地,worker从nack缓冲区中提取item。但不是删除,而是使用新的deliver_after时间和元数据(如果客户端更新了它)更新item。如果ack或nack操作因为任何原因丢失,例如MySQL不可用或FOQS节点崩溃,这些item将被考虑在租约到期后重新投递。
Push vs. Pull
FOQS提供了一个基于拉的接口,消费者使用dequeue API来获取可用数据。为了理解在FOQS API中提供拉模型背后的动机,我们看看使用FOQS的作业的多样性。它包括以下特征:
端到端延迟处理的需要:端到端处理延迟,是指item从准备好到被消费者从队列中拉取消费所经历的时间。快速消费和缓慢消费的作业混在一起。有的可以被毫秒级消费,而有的会延迟好几天。
处理速率 : topic对于item的消费速率可能是不同的(每分钟10个item到每分钟1000多个item)。但是,根据下游资源在特定时间的可用性,可能有别于它们日常的处理速度。
优先级: topic级别或topic内单个item级别的处理优先级不同。
处理的位置 : 某些topic和item需要在特定的区域进行处理,以确保它们与正在处理的数据的关联性。
FOQS的大规模实践
FOQS在过去几年中经历了指数级的增长,现在每天处理近一万亿件产品。而处理的积压订单已经达到数千亿项,反映了系统处理能力普遍欠缺。为了处理这种规模,我们必须实现一些优化。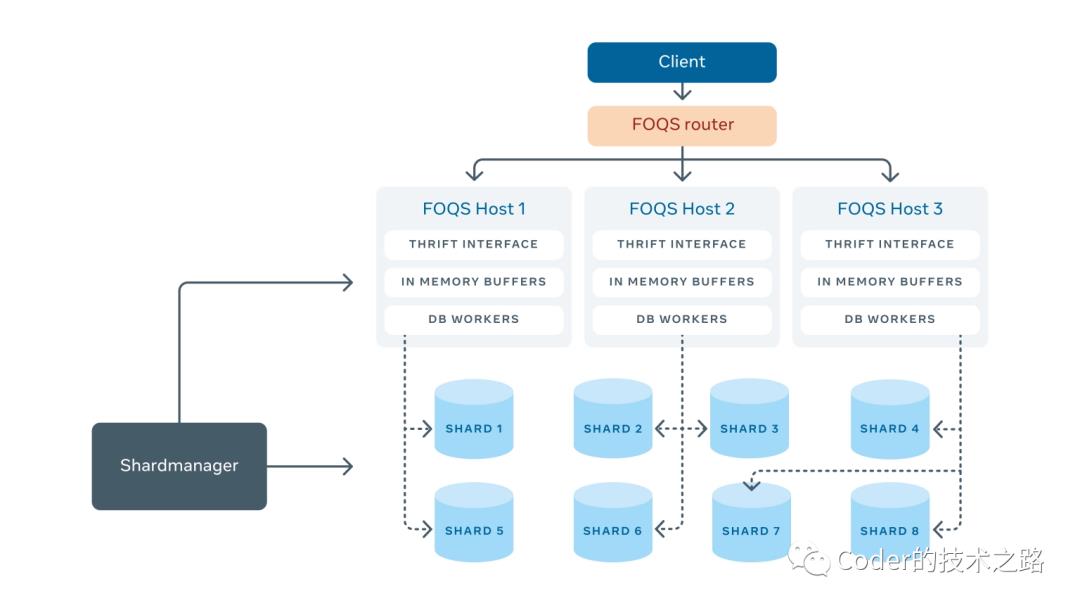
检查点 CheckPointing
FOQS专门设置有后台线程,来运行比如延迟的item准备投递、租约过期和清除过期的item,这些操作依赖于记录行中的时间戳字段。
比如,如果我们想更新所有准备交付的item的状态,来标识它们已经准备好投递,则需要一个查询:
where timestamp_column <= UNIX_TIMESTAMP() for update
对所有行进行更新。
这种查询的问题是MySQL需要用时间戳≲now 锁定对所有行更新(不仅仅是符合条件的那些记录)。、历史越长,读取查询就越慢。
通过checkpoinging,FOQS在查询上维护了一个下界(最后处理的已知时间戳),它限定了where子句。where子句变成:
WHERE <checkpoint> <= timestamp_column AND timestamp_column <= UNIX_TIMESTAMP()
通过在两边绑定查询,表示历史记录的行数就会更少,从而使读取(和更新)的总体性能更好。
灾备
Facebook的基础设施需要能够承受一整个数据中心发生异常。所以,每个FOQS MySQL分片被复制到两个冗余的灾备集群。跨区复制是异步的,但是MySQL binlog以同步的方式持久化到同一区域的另一个灾备集群中。
如果数据中心需要被清空(或者MySQL数据库正在进行维护),MySQL主数据库将暂时处于只读模式,直到副本能够和主节点同步。
这通常需要几毫秒。一旦副本和主节点数据达到一致,副本就被提升为主节点。
而这时会变成MySQL的主节点在另一个区域,而分区被分配给该区域的FOQS主机。这将最大限度地减少跨区域的网络流量,但相对来说比较昂贵。推动MySQL副本成为主节点的事件会导致跨地区的流量不平衡(一般来说,FOQS不能假设哪里有多少流量)。为了处理这些场景,FOQS不得不改进它的路由,使入队列路由到有足够容量的主机,而出队列路由到具有高优先级item的主机。
FOQS本身使用的一些灾难可靠性优化:
入队转发: 如果入队请求落在一个负载过重的主机上,FOQS将它转发给另一个有处理能力的主机。
全局速率限制: 由于namespace是foqs的多租户单元,所以每个namespace都有一个速率限制(计算为每分钟排队数)。FOQS在全局(所有地区)强制执行这个速率限制。在一个特定的区域内保证速率限制是不可能的,但是FOQS确实使用流量模式来尝试将处理能力与流量配置在一起,以减少跨区域的流量。
Reference
[1]
facebook engineering: facebook工程师技术博客
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于Facebook有序队列服务设计原理和高性能浅析的主要内容,如果未能解决你的问题,请参考以下文章