Spark学习笔记--Spark简介
Posted 幼儿园园草
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习笔记--Spark简介相关的知识,希望对你有一定的参考价值。
Spark 作为大数据计算平台的后起之秀,在2014年打破了Hadoop 保持的基准排序(Sort Benchmark)纪录,使用206个节点在23分钟的时间里完成了100TB数据的排序,而Hadoop则是使用2000个节点在72分钟的时间里完成同样数据的排序。也就是说,Spark仅使用了十分之一的计算资源,获得了3倍于Hadoop的速度。新纪录的诞生,使得Spark获得多方追捧,也表明了Spark可以作为一个更加快速、高效的大数据计算平台。
1 优点
- 运行速度快:Spark使用先进的有向无环图(Directed AcyclicGraph,DAG)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
- 容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
- 运行模式多样:Spark 可运行于独立的集群模式中,或者运行于Hadoop 中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
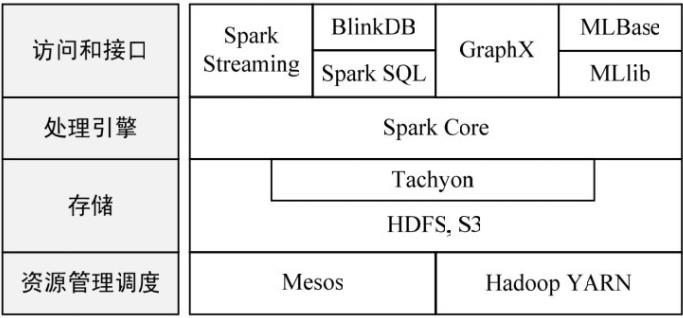
2 Spark生态
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统足以应对3种场景,分别是复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间;基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间;基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
以上是关于Spark学习笔记--Spark简介的主要内容,如果未能解决你的问题,请参考以下文章