hive常用操作一
Posted NC_NE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive常用操作一相关的知识,希望对你有一定的参考价值。
一、创建表
1、官方参考文档https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
截取重要部分
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释 (常用 )
(4)PARTITIONED BY 创建分区表(常用)
(5)CLUSTERED BY 创建分桶表(不常用)
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化 ( 常用)
(8)STORED AS 指定存储文件类型常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。(常用)
(9)LOCATION :指定表在 HDFS 上的存储位置,默认位置在hdfs(/user/hive/warehouse)(外部表一般都会指定存储位置)
2、create table 案列
没啥说的,用过hive的应该都懂得,都是一些常用
create EXTERNAL table if not exists test_db.user1(
name string comment 'name',
salary float comment 'salary'
)
comment 'description of the table'
partitioned by (age int)
row format delimited fields terminated by '\\t'
stored as orc
location '/tmp/user1';3、create table xxx as select(简称 CTAS)
create table if not exists test_db.user2 as select * from test_db.user1;
create table if not exists test_db.user2
stored as orc
as select * from test_db.user1;使用CTAS创建表时要注意如下事项:
1).hive中用CTAS 创建表,所创建的表统一都是非分区表,不管源表是否是分区表。所以对于分区表的创建使用create table ..as一定要注意分区功能的丢失。当然创建表以后可以添加分区,成为分区表。注意如果源表是非分区表则没有这个问题。
2).如果使用create table as select * 创建表时源表是分区表,则新建的表会多字段,具体多的字段个数和名称就是源表分区的个数和名称。当然如果select选择的是指定的列则不会有这种问题。
3).如果源表的存储格式不是TEXTFILE。则使用CTAS创建的表存储格式会变成默认的格式textfile(指定除外)。比如这里源表是RCFILE。而新建的表则是TEXTFILE。当然可以在使用create table ....as创建表时指定存储格式和解析格式,甚至是列的名称等属性。
4).使用CTAS方式创建的表不能是外部表.
5).使用CTAS创建的表不能分桶表
4、create table xxx like xxx2
这种方式建表基本和原表一致,但是如果元表是外部表创建后目标表是内部表
create table if not exists test_db.user3 like test_db.user1;
自己指定外部表
create external table if not exists test_db.user3 like test_db.user1;二、查看表结构
1、desc tablename
2、desc formatted tablename (加formatted,可以看到更加详细和冗长的输出信息)
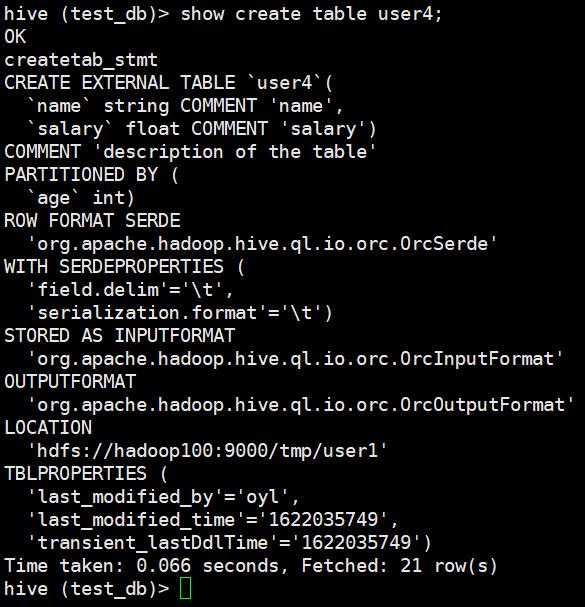
3、show create table tablename
4、show partitions tablename (查看分区信息)
三、修改表(都是通过alter关键字)
1、重命名表
ALTER TABLE table_name RENAME TO new_table_name
ALTER TABLE test_db.user1 RENAME TO test_db.user4;2、 增加、修改和删除表分区
增加分区
alter table table_name add partition(...) location hdfs_path
alter table test.user2 add if not exists partition (age = 101) location '/user/hive/warehouse/test.db/user2/part-0000101' partition (age = 102) location '/user/hive/warehouse/test.db/user2/part-0000102'修改分区
alter table ... set ...
alter table test.user2 partition (age = 101) set location '/user/hive/warehouse/test.db/user2/part-0000110'删除分区
alter table tableName drop if exists partition(...)
alter table test.user2 drop if exists partition(age = 101)3、列增加,修改
增加列 ADD 是代表新增一字段,字段位置在所有列后面(partition 列前)
alter table test_db.user2 add columns ( num int comment '幸运数', hobby string comment '爱好' );修改列类型(int->string)
alter table test_db.user2 change column num desc string;替换列(也可以删除列及数据)
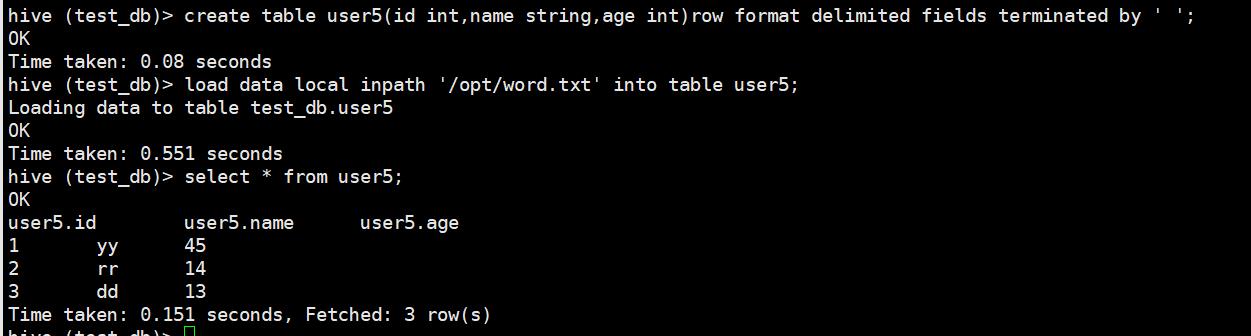
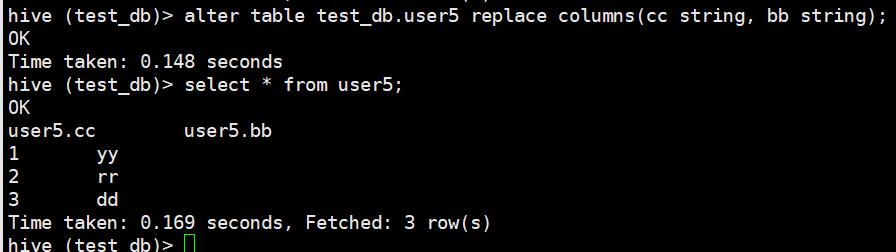
alter table test_db.user5 replace columns(cc string, bb string);将原表三列数据替换成两列了
替换后的表
以上是关于hive常用操作一的主要内容,如果未能解决你的问题,请参考以下文章