高性能分布式任务队列Celery功能探究
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能分布式任务队列Celery功能探究相关的知识,希望对你有一定的参考价值。
本文讲述的是高性能分布式任务队列Celery的相关功能和设计,Celery因为其良好的设计思想和性能,跟分布式任务调度系统Airflow完美配合,成就了两套知名系统,而Celery更加掩藏功与名,成为幕后英雄,将功能收缩,专注于成为分布式调度系统的底层基础设施:分布式任务队列。尽管如此,Celery并不会不为人所知,假如你想轻松开发另一套分布式系统,比如WaterFlow、SunFlow等,Celery会成为您绕不过的选项。
Celery概述
Celery是一个简单,灵活,可靠的分布式系统,用于异步处理大量消息。它是一个任务队列,专注于实时处理。虽然对任务的执行长短不加限制,但特别适合于短平快的小任务,比如邮件发送、客户唤醒和优惠券发放等相对耗时的操作。Celery具有如下优点:
简单:Celery的配置和使用很简单,非常容易上手
高可用:Celery作为队列系统,组件具有可扩展的特性,因此组件继承了高可用的功能,比如多Worker之间可以同步消息和选举,在Worker内部,主从架构也保证了Consumer的高可用。任务可以在不同节点之间路由,同样具备了故障转移功能,任务执行成功会有ACK机制。此外,对于任务的异常处理还提供了丰富的处理机制,比如自动重试、超时Kill和失败回调等。
快速:基于Python协程和事件处理机制,以及结合RabbitMQ或Redis保证了较高的吞吐量和性能
灵活:几乎Celery的各个组件都可以被扩展及自定制
Celery架构
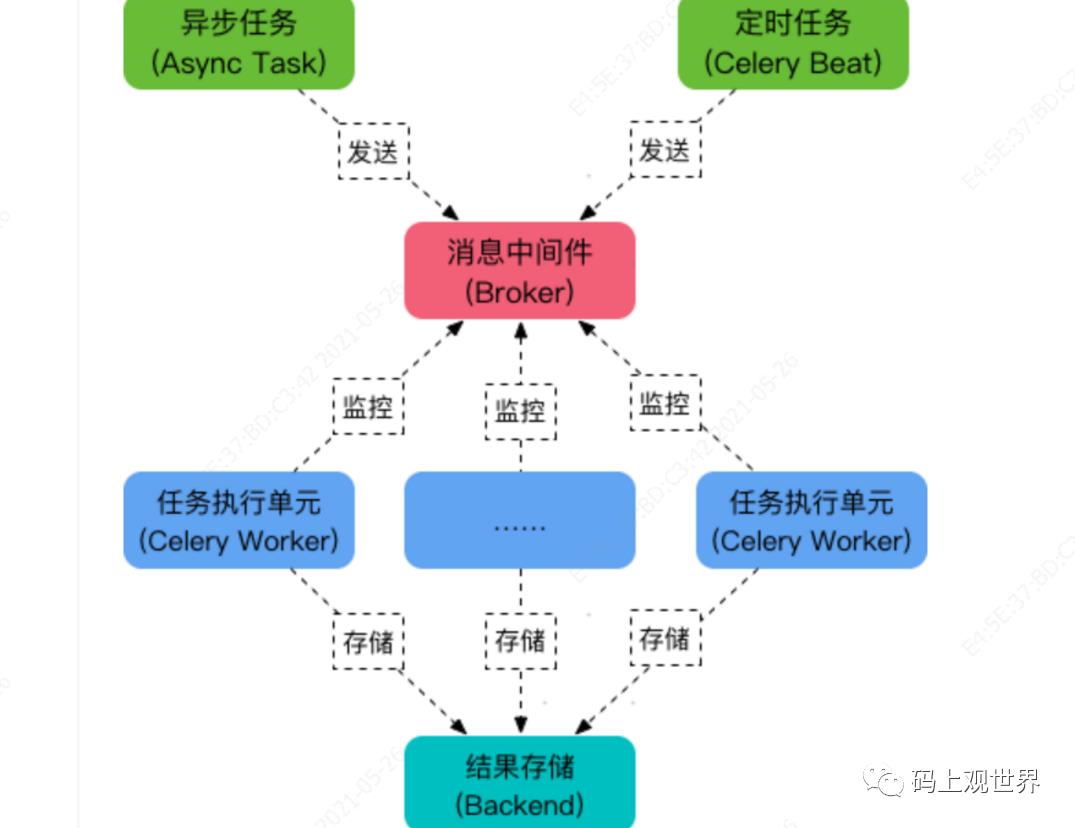
Celery 作为分布式消息系统的特殊形式,具备消息系统的基本逻辑功能,比如Producer、Consumer、Broker等,但在Celery实现中,分布式消息系统作为其组件存在,比如RabbitMQ作为Celery的Broker的可选项之一。另外,消费者成为Celery的核心之一,起着任务的获取、分发和执行等作用。Celery的主要概念如下:
Task:作为消息类型的一种,是Celery对任务的表示和封装,主要有异步任务和定时任务两种,Task通过生产者(API和Beat)投递
Broker:分布式队列服务。生产者将消息(Task)发送到Broker,消费者Worker从Broker获取消息(Task)。Celery本身不提供队列服务,推荐用RabbitMQ和Redis
Worker:Celery部署和执行单元。Worker内部有Consumer,Worker实时监控消息队列,将获取的消息分发到Consumer
Beat:定时任务调度器,根据配置定时将任务发送给Broker
Backend:用于存储任务的执行结果(可选部分),推荐Redis和mysql
Celery任务创建
任务创建首先创建一个Celery实例,即app应用,app是Celery所有功能的入口,比如创建任务,管理任务等,在使用Celery的时候,app能够被其他的模块导入。Celery第一个参数是模块名,用于自动产生的任务名称前缀, 第二参数为broker地址,第三个参数为backend地址。
#myapp.py
from celery import Celery
broker_url = 'redis://localhost:6379/0'
result_backend='redis://localhost:6379/1'
app = Celery('myapp', backend=result_backend, broker=broker_url)
任务创建通过@app.task装饰器修饰,每个任务都有唯一的名称,默认为模块名.方法名,如tasks.add。下面为创建的任务:
# tasks.py
from myapp import app
@app.task
def add(x, y):
return x + y
@app.task(name='tasks.mul')
def mul(x, y):
return x * y
@app.task
def hello(what):
print(what)
通过如下命令启动Worker实例:
celery -A tasks worker
-A指定Celery app应用名称,如myapp,但是如果app和tasks定义分离到不同文件,此时需要指定为tasks定义所在的模块名,如这里为tasks,否则任务执行报错提示任务没有定义,因为 Worker启动时从该参数指定的模块中注册定义的任务。
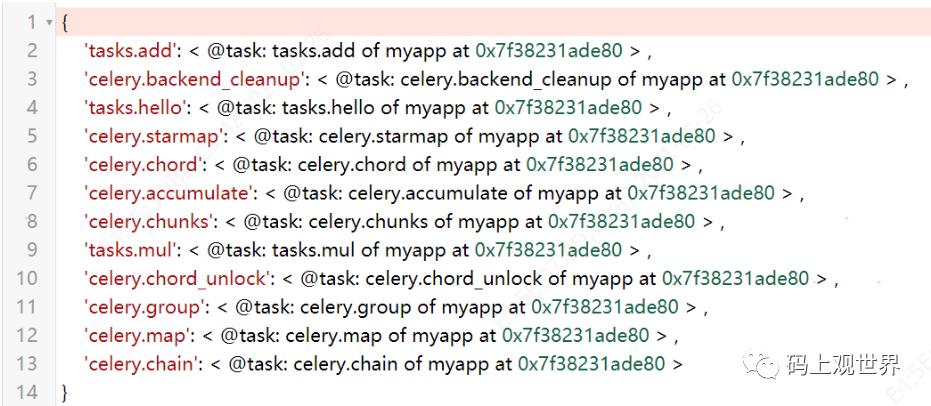
通过如下命令查看已经注册的任务:

如下图所示,以tasks为前缀的任务名属于自定义任务,以celery前缀的任务为Celery实例的内置任务:
尝试在客户端控制台中发起一个延迟任务hello,在worker实例所在控制台打印出调用信息:
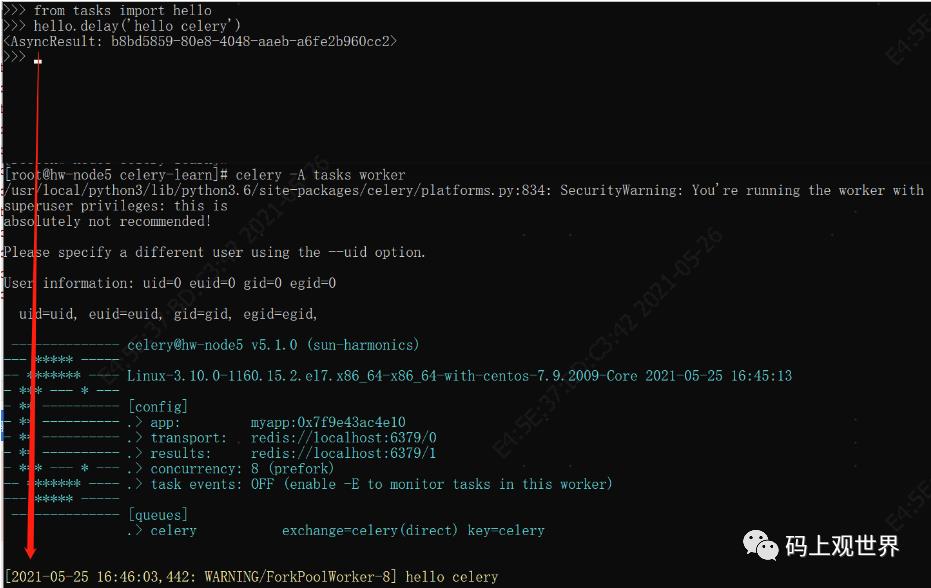
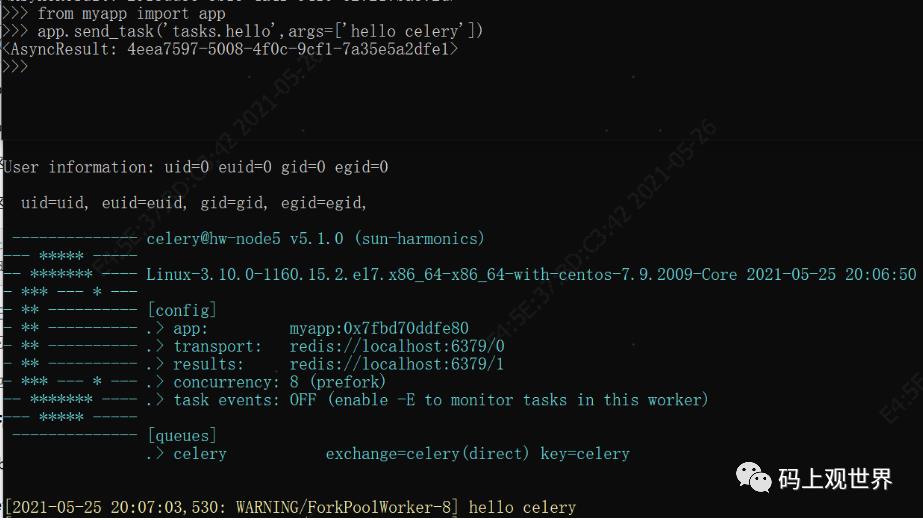
注意hello也可以同步调用,此时会在client本地调用,而不会发送到队列。除了可以通过delay、apply_async等方法异步执行任务,还可以通过send_task发送任务到队列,如下图,注意任务名称为带前缀的全称:
任务消息包含什么
任务通过生产者,比如上文中的各种异步API,以消息的方式发送到broker,为了探究消息的组成,我们停止Worker实例,然后到Redis后台看看celery key,这里存储待执行的任务列表:
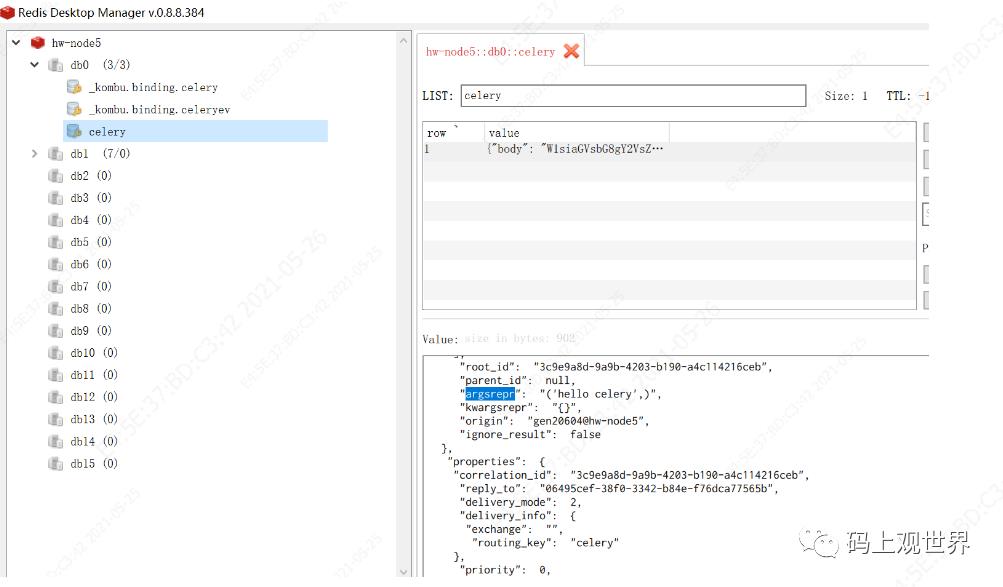
每个任务都是一个JSON格式表示的消息,具体格式和内容如下:
# celery/app/amqp.py
task_message(
headers={
'lang': 'py',
'task': name,
'id': task_id,
'shadow': shadow,
'eta': eta,
'expires': expires,
'group': group_id,
'group_index': group_index,
'retries': retries,
'timelimit': [time_limit, soft_time_limit],
'root_id': root_id,
'parent_id': parent_id,
'argsrepr': argsrepr,
'kwargsrepr': kwargsrepr,
'origin': origin or anon_nodename()
},
properties={
'correlation_id': task_id,
'reply_to': reply_to or '',
},
body=(
args, kwargs, {
'callbacks': callbacks,
'errbacks': errbacks,
'chain': chain,
'chord': chord,
},
),
sent_event={
'uuid': task_id,
'root_id': root_id,
'parent_id': parent_id,
'name': name,
'args': argsrepr,
'kwargs': kwargsrepr,
'retries': retries,
'eta': eta,
'expires': expires,
} if create_sent_event else None,
)
如果发送一个较长延时的任务,Redis又是怎么存储的呢?开启Worker实例,执行如下命令:
hello.apply_async(args=['hello celery'],countdown=30)
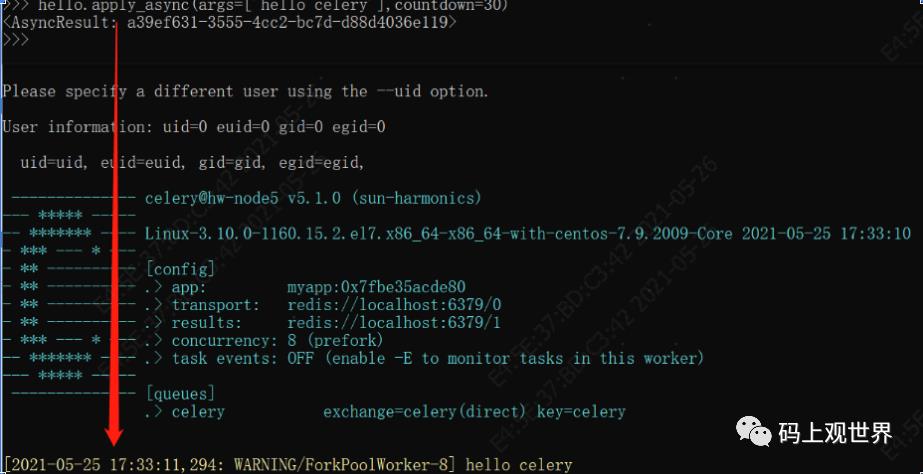
Redis多了一个unacked的key,也存储了待执行的任务列表,任务格式同上面一样,可见Celery对这两种方式投递的任务处理逻辑不一样。
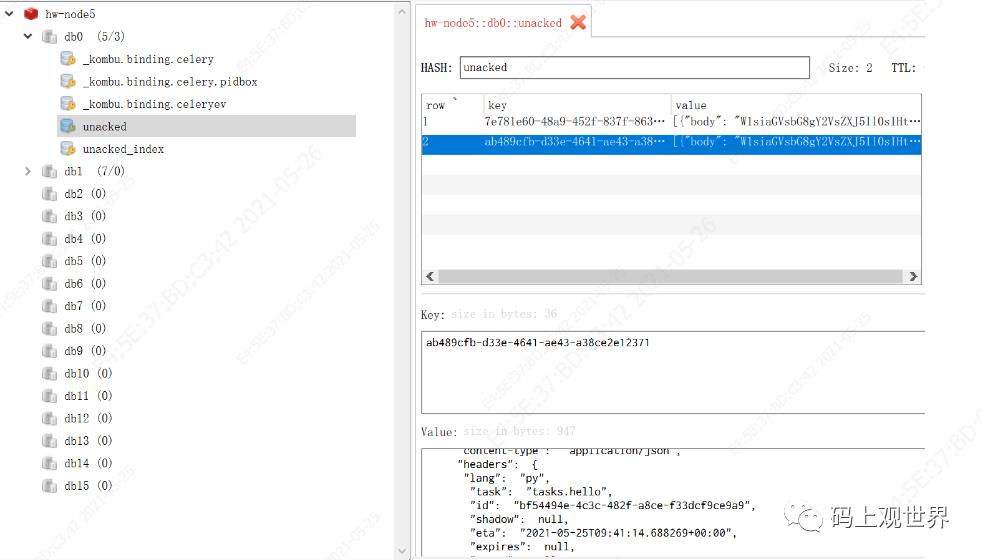
消息格式中各字段含义,列举如下,这里是官方文档介绍,不做翻译了:
id:The unique id of the executing task.
group:The unique id of the task’s group, if this task is a member.
headers:Mapping of message headers sent with this task message (may be None).
reply_to:Where to send reply to (queue name).
correlation_id:Usually the same as the task id, often used in amqp to keep track of what a reply is for.
root_id:The unique id of the first task in the workflow this task is part of (if any).
parent_id:The unique id of the task that called this task (if any).
origin:Name of host that sent this task.
retries:How many times the current task has been retried. An integer starting at 0.
eta:The original ETA of the task (if any). This is in UTC time (depending on the enable_utc setting).
expires:The original expiry time of the task (if any). This is in UTC time (depending on the enable_utc setting).
hostname:Node name of the worker instance executing the task.
delivery_info:Additional message delivery information. This is a mapping containing the exchange and routing key used to deliver this task. Used by for example app.Task.retry() to resend the task to the same destination queue. Availability of keys in this dict depends on the message broker used.
reply-to:Name of queue to send replies back to (used with RPC result backend for example).
timelimit:A tuple of the current (soft, hard) time limits active for this task (if any).
argsrepr:Positional arguments.
kwargsrepr:Keyword arguments.
周期任务
上面介绍的是通过API发送单次任务,Celery 也支持周期任务,比如下面创建一个每3秒执行一次的任务:
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# Calls say('hello') every 3 seconds.
sender.add_periodic_task(3.0, hello.s('hello celery'), name='hello every 3s')
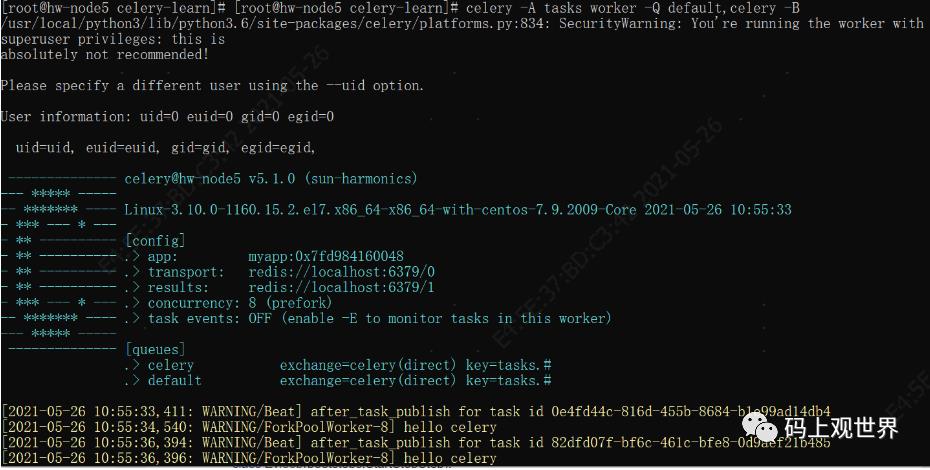
周期任务依赖beat,beat基于本地文件存储记录任务的上次调度信息来实现的定时调度。由于这种设计的问题,导致周期任务的功能不够强,Airflow就在其基础上,托管了周期调度功能,而将任务的执行交给了Celery。
消息路由方式
Celery依赖了Kombu,Kombu是一种兼容AMQP协议的消息队列抽象,提供了对AMQP协议的broker,如RabbitMQ和非AMQP协议的broker,如Redis等的统一访问,其抽象模型中的概念跟RabbitMQ 差不多,但是,不完全一样,有一些差别,主要有:
Message:生产消费的基本单位,其实就是我们所谓的一条条消息
Connection:对 MQ 连接的抽象,一个 Connection 就对应一个 MQ 的连接
Transport:真实的 MQ 连接,也是真正连接到 MQ(redis/rabbitmq) 的实例
Producers: 发送消息的抽象类
Consumers:接受消息的抽象类
Exchange:消息发送到这里之后,根据一定策略路由到队列
Queue:对应的 queue 抽象,其实就是一个字符串的封装
这些概念在Celery架构模型的地位和作用如下图所示:
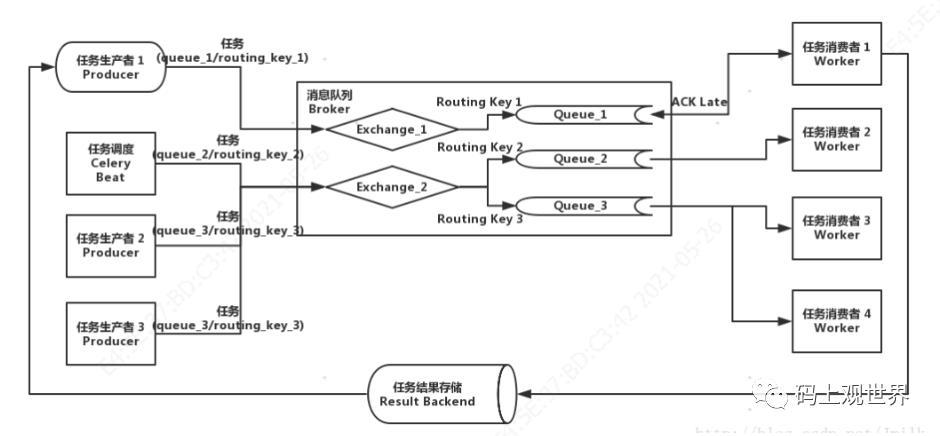
上述概念之间的关系,官方文档说得也更明白,这里也不做画蛇添足去翻译了:
Producers, consumers, and brokers
The client sending messages is typically called a publisher, or a producer, while the entity receiving messages is called a consumer.
The broker is the message server, routing messages from producers to consumers.
Exchanges, queues, and routing keys
Messages are sent to exchanges.
An exchange routes messages to one or more queues. Several exchange types exists, providing different ways to do routing, or implementing different messaging scenarios.
The message waits in the queue until someone consumes it.
The message is deleted from the queue when it has been acknowledged.
下面通过程序演示用法,在原来代码基础上修改:
#myapp.py
from celery import Celery
from kombu import Queue
# Broker settings.
broker_url = 'redis://localhost:6379/0'
result_backend='redis://localhost:6379/1'
app = Celery('tasks', backend=result_backend, broker=broker_url)
#全局设置将tasks为前缀的任务路由到队列celery
app.conf.task_routes = {'tasks.*': {'queue': 'celery'}}
#还可以通过指定routing_key更具体的路由不同队列
app.conf.task_queues = (
Queue('default', routing_key='tasks.#'),
Queue('celery',routing_key='tasks.#'),
)
#全局设置任务的默认queue
app.conf.task_default_queue = 'default'
#全局设置任务的默认routing_key
app.conf.task_default_routing_key = 'tasks.default'
#全局设置任务的默认priority
app.conf.task_default_priority = 5
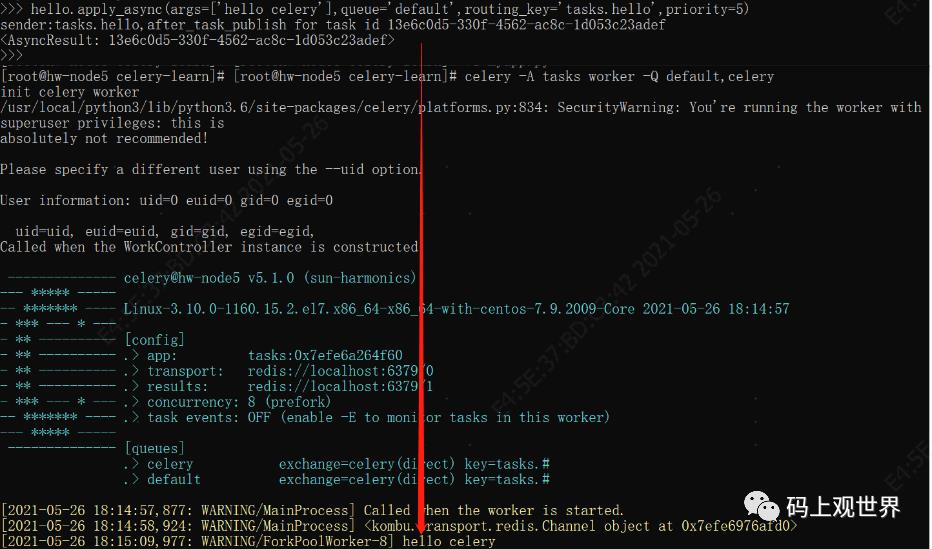
在客户端控制台发送异步任务,指定queue和routing_key:
hello.apply_async(args=['hello celery'],queue='default',routing_key='tasks.hello',priority=5)
启动Worker,并设置监听的队列,这里监控两个队列:
celery -A tasks worker -Q default,celery
Celery信号机制
作为扩展点机制之一,Celery提供了大量的信号(回调方法)供自定义开发,主要有:
Signals
Task Signals
before_task_publishafter_task_publishtask_preruntask_postruntask_retrytask_successtask_failuretask_internal_errortask_receivedtask_revokedtask_unknowntask_rejected
App Signals
import_modules
Worker Signals
celeryd_after_setupceleryd_initworker_initworker_readyheartbeat_sentworker_shutting_downworker_process_initworker_process_shutdownworker_shutdown
Beat Signals
beat_initbeat_embedded_init
Eventlet Signals
eventlet_pool_startedeventlet_pool_preshutdowneventlet_pool_postshutdowneventlet_pool_apply
Logging Signals
setup_loggingafter_setup_loggerafter_setup_task_logger
Command signals
user_preload_options
比如任务发布前、后和成功、失败,都会调用对应的回调函数,如:

Celery扩展点
自定义消息处理
#myapp.py
from celery
import Celeryfromcelery
import bootstepsfromkombuimport Consumer, Exchange, Queue
broker_url = 'redis://localhost:6379/0'
result_backend='redis://localhost:6379/1'
app = Celery('tasks', backend=result_backend, broker=broker_url)
class MyConsumerStep(bootsteps.ConsumerStep):
def get_consumers(self, channel):
return [Consumer(channel,callbacks=[self.handle_message], accept=['json'])]
def handle_message(self, body, message):
print('Received message: {0!r}'.format(body))
message.ack()
app.steps['consumer'].add(MyConsumerStep)
#client.py
#trigger msg publish using command 'python3 client.py'
from myapp import app
from kombu import Queue,Exchange
my_queue = Queue('celery', Exchange('celery'), 'tasks.hello')
def send_me_a_message(who, producer=None):
with app.producer_or_acquire(producer) as producer:
producer.publish({'tasks.hello': who},serializer='json',exchange=my_queue.exchange,declare=[my_queue],routing_key='tasks.hello',retry=True,)
if __name__ == '__main__':
send_me_a_message('hello celery!')
蓝图Blueprints
Bootsteps在Worker不同启动阶段通过添加hooks来给Worker添加自定义功能,每个bootstep都属于一个Blueprints,worker定义了两种Blueprints:Worker和Consumer。这些bootstep按照如下图的依赖关系自底向上的方向启动:
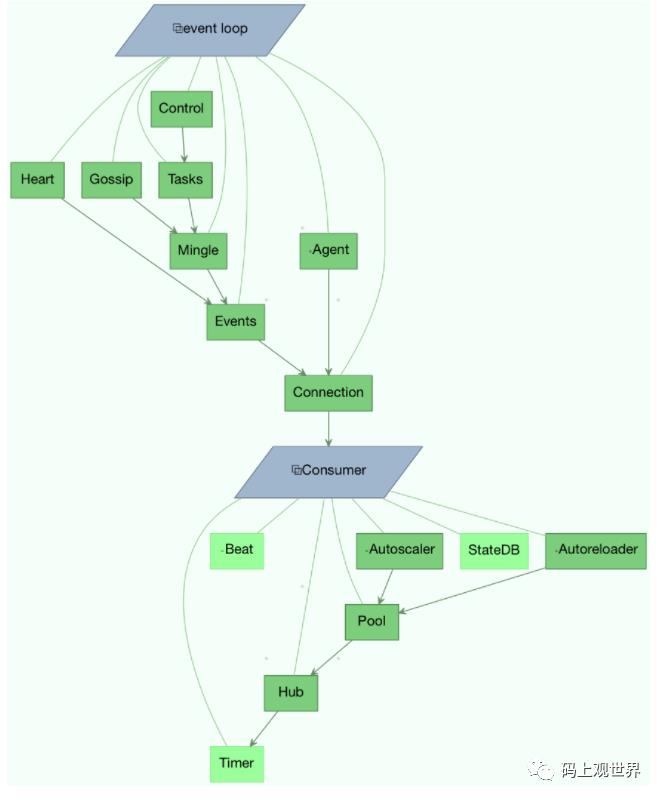
如果要扩展bootstep的功能,自定义bootstep需要依赖相应的bootstep,如扩展Pool:
from celery import bootsteps
class ExampleWorkerStep(bootsteps.StartStopStep):
requires = {'celery.worker.components:Pool'}
def__init__(self, worker, **kwargs):
print('Called when the WorkController instance is constructed')
print('Arguments to WorkController: {0!r}'.format(kwargs))
def create(self, worker):
# this method can be used to delegate the action methods
# to another object that implements ``start`` and ``stop``.
returnself
def start(self, worker):
print('Called when the worker is started.')
def stop(self, worker):
print('Called when the worker shuts down.')
def terminate(self, worker):
print('Called when the worker terminates')
app.steps['worker'].add(ExampleWorkerStep)
延时任务实现
上文提到在Redis中通过一个key记录了待执行的延迟任务列表,那Celery如何处理这种延时任务的呢?有了上面知识和技能的储备,下面通过翻代码的方式来探究下:
# celery/worker/consumer/consumer.py
#这是Worker的最后一步启动的bootstep
class Evloop(bootsteps.StartStopStep):
def start(self, c):
self.patch_all(c)
#异步循环获取消息
c.loop(*c.loop_args())
# celery/worker/consumer/consumer.py
if not hasattr(self, 'loop'):
self.loop = loops.asynloop if hub else loops.synloop
# celery/celery/worker/loops.py
......
on_task_received = obj.create_task_handler()
......
while blueprint.state == RUN and obj.connection:
state.maybe_shutdown()
# We only update QoS when there's no more messages to read.
# This groups together qos calls, and makes sure that remote
# control commands will be prioritized over task messages.
if qos.prev != qos.value:
update_qos()
try:
next(loop)
except StopIteration:
loop = hub.create_loop()
# celery/worker/consumer/consumer.py
try:
strategy = strategies[type_]
except KeyError as exc:
return on_unknown_task(None, message, exc)
else:
try:
#执行任务策略
strategy(
message, payload,
promise(call_soon, (message.ack_log_error,)),
promise(call_soon, (message.reject_log_error,)),
callbacks,
)
#celery/worker/strategy.py
if req.eta:
try:
if req.utc:
eta = to_timestamp(to_system_tz(req.eta))
else:
eta = to_timestamp(req.eta, app.timezone)
except (OverflowError, ValueError) as exc:
error("Couldn't convert ETA %r to timestamp: %r. Task: %r",
req.eta, exc, req.info(safe=True), exc_info=True)
req.reject(requeue=False)
if rate_limits_enabled:
bucket = get_bucket(task.name)
if eta and bucket:
consumer.qos.increment_eventually()
return call_at(eta, limit_post_eta, (req, bucket, 1),
priority=6)
if eta:
consumer.qos.increment_eventually()
call_at(eta, apply_eta_task, (req,), priority=6)
return task_message_handler
# kombu/asynchronous/timer.py
def call_at(self, eta, fun, args=(), kwargs=None, priority=0):
kwargs = {} if not kwargs else kwargs
return self.enter_at(self.Entry(fun, args, kwargs), eta, priority)
enter_at最终进入到kombu的timer中:
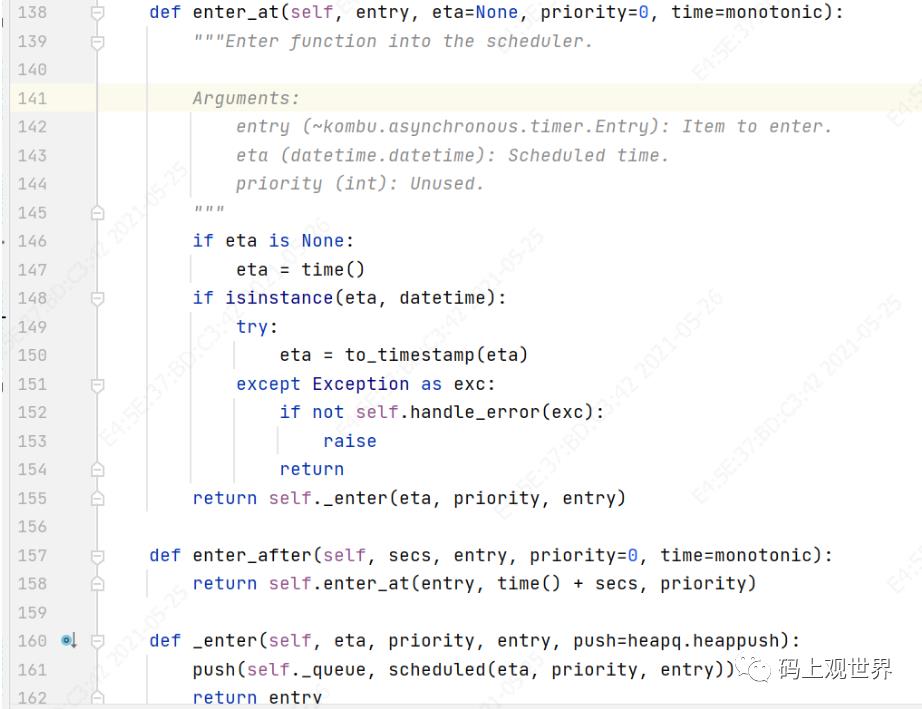
在该方法中,发现任务被添加到最小堆中,堆按照任务的启动时间排序,堆顶是最先被调度的任务,可见Celery通过kombu获取待执行任务,而任务的调度执行交给kombu代理了。
参考资料
https://docs.celeryproject.org/en/stable/userguide/extending.html
https://kombu.readthedocs.io/en/latest/userguide/failover.html#producer
以上是关于高性能分布式任务队列Celery功能探究的主要内容,如果未能解决你的问题,请参考以下文章