掌握spark 3.0中的查询计划
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了掌握spark 3.0中的查询计划相关的知识,希望对你有一定的参考价值。
本文翻译自Mastering Query Plans in Spark 3.0,能够很好的帮助学习spark sql理解spark UI的计划,决定翻译记录一下。
在Spark SQL中查询计划是理解查询执行的入口点,它携带了大量的信息,并且能够洞察查询是怎么执行的。在大的负载下或者执行的任务很长的时候,这些信息很重要的。从查询计划的信息我们可以发现哪些是低效的并且能够重写查询去提供更好的性能。
对于不熟悉查询计划的人来说,乍一看,这些信息有点难懂。它是树形结构,并且每个节点代表了一种操作,每种操作上提供了执行的基本信息。spark官方文档上涉及到查询计划的信息是比较少的。这边文章的动机就是让我们熟悉物理计划,我们接下来将会来看一下常用到的操作以及它们提供的信息以及他们是怎么执行的。
这边文章所涉及到的理论大部分是基于对源码的研究和运行优化spark查询计划的实践。
基本例子
我们考虑一个简单的例子,一个查询中涉及到filter以及aggregation,join操作的语句:
# in PySpark API:
query = (
questionsDF
.filter(col('year') == 2019)
.groupBy('user_id')
.agg(
count('*').alias('cnt')
)
.join(usersDF, 'user_id')
)
我们把例子中的usersDF是一组问问题的用户,这些问题用questionsDF来表示。这些问题用year的这一列来进行分区,代表着哪一年问的问题。在这个查询里,我们对2019年问问题的用户感兴趣,并且想知道每个人问了多少问题,而且我们想知道在输出中我们想知道一些额外信息,这就是为什么我们在聚合之后进行了usersDF的join操作。
这里有两种基本的方式去查看物理计划。第一种是在DataFrame上调用explain函数,该函数展现这个计划的文本化的展示:

这在spark 3.0有了一些优化,explain函数带有了一个新参数 mode,这个参数的值可以是:formatted,cost,codegen。使用formatted模式将会把查询计划转化为更加有组织的输出(这里之展现了一部分):
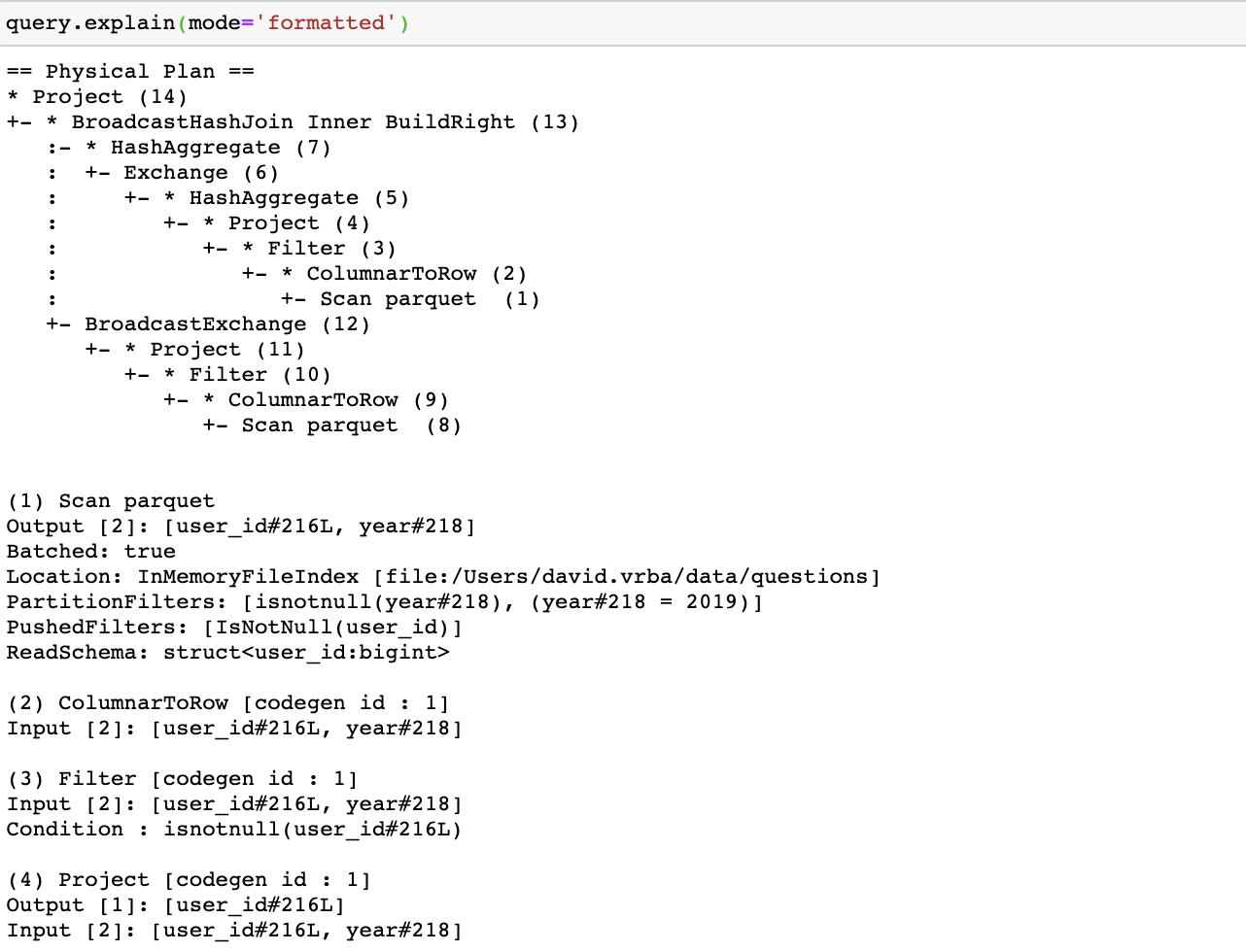
在formatted计划中,我们能看到裸树,该裸树只是展现了操作的名字并带有一个括号的数字。在数的下面,这里有一些数字对应的细节描述。cost模式将会展示除了物理计划之外的优化的逻辑计划,这些逻辑计划带有每个操作的统计信息,所以我们能看到在不同执行阶段的数据大小。最终codegen模式展现了将会执行的生成的java代码。
第二种方式是查看spark ui中的sql tab,这里有正在跑的和已经完成了的查询。通过点击你要查看的查询,我们可以看到物理计划的文本表示。在下面这个图片中,我们结合图形表示,文本表示以及它们之间的对应关系:
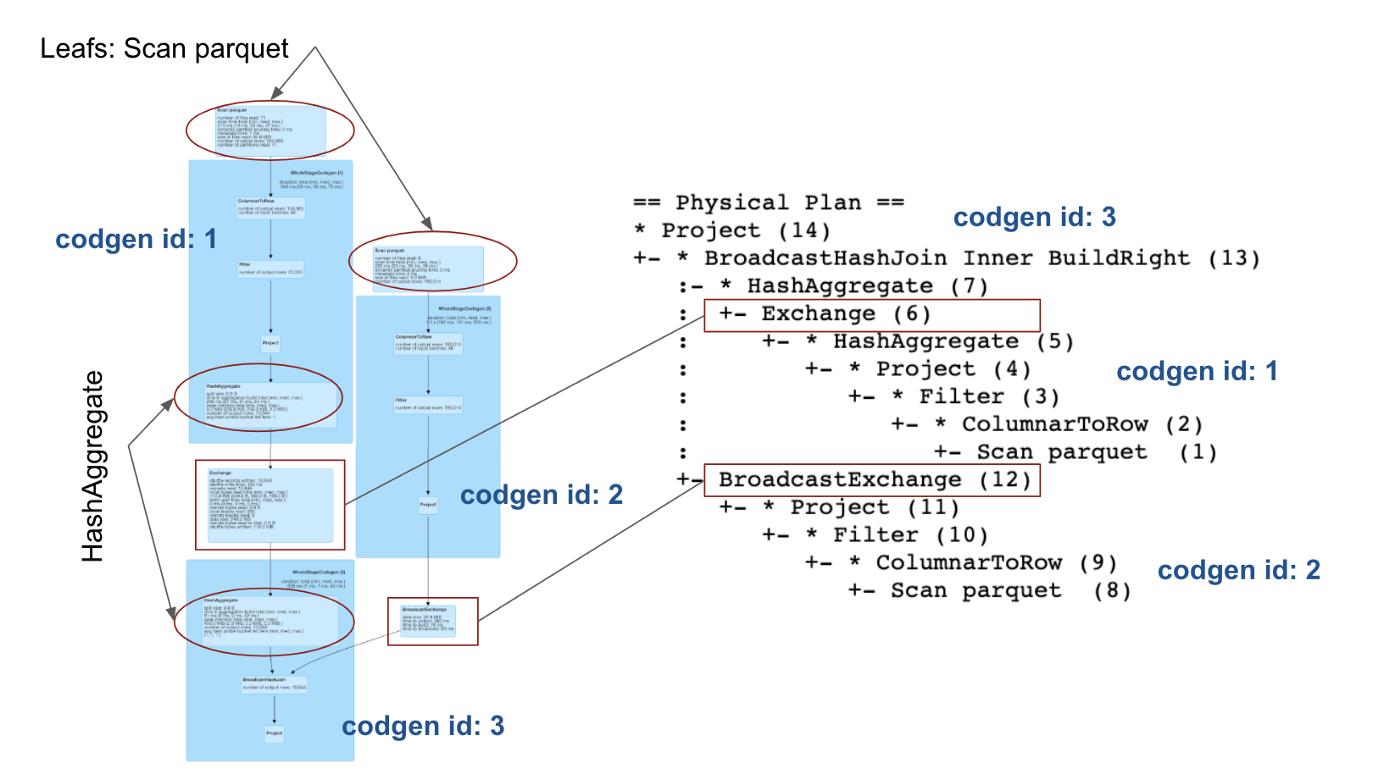
不同点是图形表示的叶子节点在上面,根节点在下面,而文本表示的是反过来的。
CollapseCodegenStages
在物理计划的图形表示中,你能看到一些操作被组织成了一大块蓝色的矩形。这些大矩形对应着codegen阶段。这是发生在物理计划的优化阶段。这个是叫做CollapseCodegenStages来负责优化的,原理是把支持代码生成的操作聚合到一起,通过消除虚拟函数的调用来加速。但是并不是所有的操作支持代码生成。所以一些操作(如exchange操作)并不是大矩形的一部分。在我们的例子中,这里有三个codegen stages,对应着三个大矩形,你能在操作的括号中看到codegen stage的id。从这个树我们也可以分辨出一个操作是够支持代码生成,因为加入支持代码生成的话,这里将会在对应的操作的括号里有个星号。
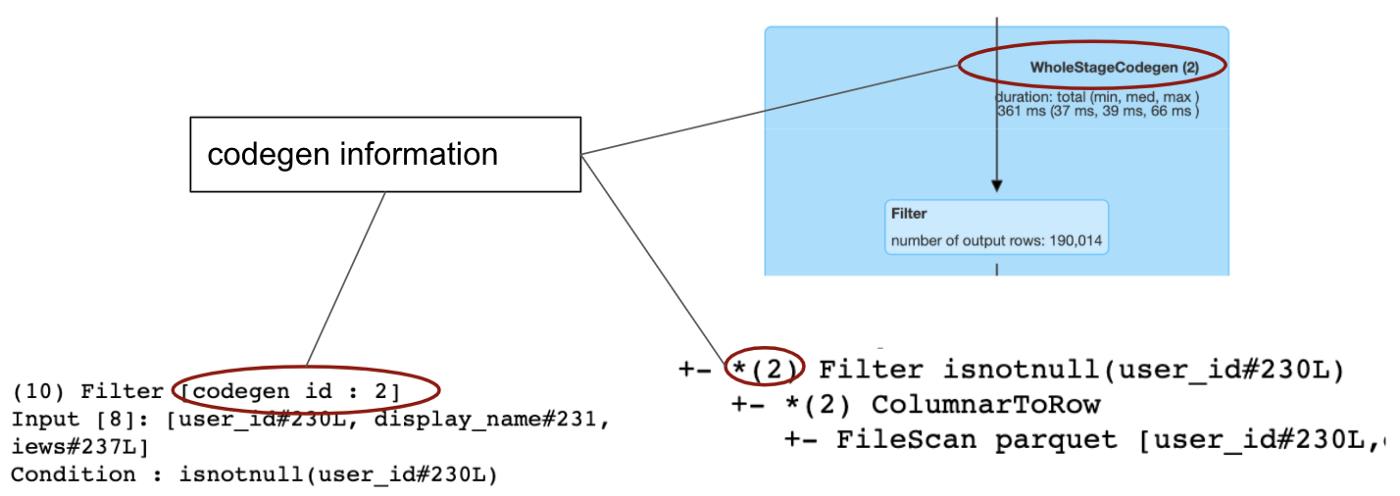
我们简单的分析一下在我们查询中的每一个操作。
Scan parquet
scan parquet操作代表着从parquet文件中读取数据。从明细信息中,我们能直接看到从这个数据源中我们选择了哪些列。虽然我们没指定具体的字段,但是这里也会应用ColumnPruning规则,这个规则会确保只有真正字段才会从这个数据源中提取出来。我们也能看到有两种filters:PartitionFilters和PushFilters。PartitionFilters应用在数据源分区的字段上。这是非常重要的因为我们能跳过我们不需要的数据。检查对应的filters是否传播到正确的位置总是没错的。这是因为我们尽可能读取少量的数据,因为IO是比较费时的。在spark 2.4,这里还有一个代表实际读取到的分区的partitionCount字段,这个字段在spark 3.0已经去掉了。
PushFilters把字段直接下推到parquet文件中去,假如parquet文件过滤的列是按照过滤字段排序的话,这个规则就很有用了,因为这种情况下,我们能利用parquet内部结构去过滤数据。parquet文件是按照行组和每个行组的元数据文件组成的。这个元数据包含了每个行组的最大最小值,基于这个信息,我们就能判断是否读取这个行组。
Filter
Filter操作佷容易理解。它仅仅是代表过滤条件。但是这个操作怎么创建的并不是很明显,因为在查询中它并不是直接对应着过滤条件。因为所有的filters首先被Catalyst optimzer处理,改规则可能修改或者重新移动她们。这里有好几个规则在她们转换为物理计划前的逻辑计划。我们列举了一下:
- PushDownPredicates-这个规则通过其他的操作把filter下推到离数据源更近的地方,但不是所有的操作都支持。比如,如果表达式不是确定性的,这就不行,假如我们使用类似first,last,collect_set,collect_list,rand等,filters操作就不能通过这些操作而进行下推,因为这些函数是不确定性的。
- CombineFilters-结合两个临近的操作合成一个(收集两个filters条件合成一个更为复杂的的条件)
- InferFiltersFromConstraints-这个规则实际上会创建新的filter操作,如从join操作(从inner join中创建一个joining key is not null)
- PruneFilters-移除多余的filters(比如一个filters总是true)
Exchange
Exchange操作代表着shuffle操作,意味着物理数据的集群范围内的移动。这个操作是很费时的,因为它会通过网络移动数据。查询计划的信息也包含了一些数据重新分区的细节。在我们的例子中,是hashPartitioning(user_id,200):

这意味着数据将会根据user_id列重新分区为200个分区,有着同样user_id的行将会属于同一个分区,将会分配到同一个executor上。为了确保只有200分区,spark将会计算user_id的hashcode并且对200取模。这个结果就是不同的user_ids就会分到同一个分区。同时有些分区可能是空的。这里也有其他类型的分区值的去留意一下:
- RoundRobinPartitioning-数据将会随机分配到n个分区中,n在函数repartition(n)中指定
- SinglePartition-所有数据将会分配到一个分区中,进而到一个executor中。
- RangePartitioning-这个用在对数据排序中,用在orderBy或者sort操作中
HashAggregate
这个代表着数据聚合,这个经常是两个操作,要么被Exchange分开或者不分开:
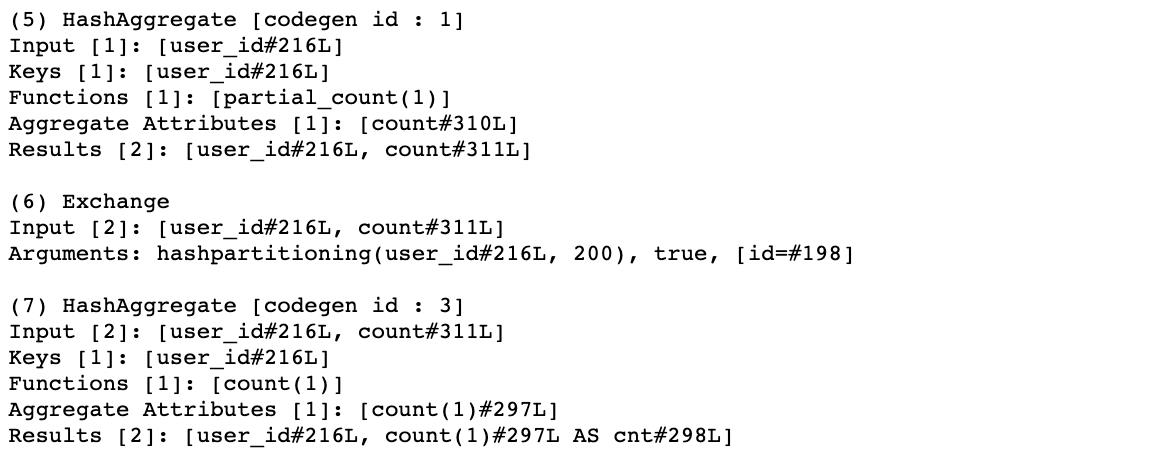
为什么这里有两个HashAggregate操作的原因是第一个是部分聚合,它在每个executor上每个分区分别进行聚合。在我们的例子中,你能看到partial_count(1)的function字段,最终的部分聚合结果就是第二个聚合。这个操作也展示了数据按照哪个分组的Keys字段。results字段展示了在聚合以后的可用的列。
BroadcastHashJoin & BroadcastExchange
BroadcastHashJoin(BHJ)代表着join算法的操作,除了这个,还有SortMergeJoin和ShuffleHashJoin。BHJ总是伴随着BroadcastExchange,这个代表着广播shuffle-数据将会收集到driver端并且会被传播到需要的executor上。
ColumnarToRow
这是在spark 3.0引入的新操作,用于列行之间的转换
总结
在spark sql中的物理计划由携带了有用信息的操作组成,正确理解每个操作能够更好的洞察执行,并且通过分析计划,我们可以分析是够是最优的,必要的时候可以进行优化。
在这篇文章里,我们描述了在物理计划中经常用到的一组操作,虽然不是全部但是我们尽量去覆盖经常使用到的操作。
以上是关于掌握spark 3.0中的查询计划的主要内容,如果未能解决你的问题,请参考以下文章
Spark 优化 | 图文理解 Spark 3.0 的动态分区裁剪优化