spark on k8s:apache YuniKorn(Incubating)的助力
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark on k8s:apache YuniKorn(Incubating)的助力相关的知识,希望对你有一定的参考价值。
背景
为什么选择spark on k8s
Apache Spark 作为一站式平台统一了批处理,实时处理,流分析,机器学习,以及交互式查询.虽然说spark 提供了多样的使用场景,但是也带来了额外的复杂性以及集群管理的成本。让我们来看一下为了赋能spark为一站式平台所需要的底层资源编排:
- spark计算要提供不同的机器学习以及etl任务的资源共享
- 支持在共享k8s集群的spark多版本,python多版本,以及版本控制的快读迭代以及生产环境的稳定
- 需要一个统一的批任务以及微服务的底层支持
- 在共享集群间的细粒度的控制
kubernetes 作为一个服务部署标准,相对于其他的资源编排,满足以上所有的需求。kubernetes提供了一个管理基础设施和应用的简单方法,能够做到负载隔离,资源限制,按需部署,按需扩容。
spark on k8s的调度挑战
kubernetes默认的调度器就在同一集群有效的部署批任务和长期运行的服务还是存在差距的。批任务大部分是需要一起调度,并且由于任务并行的需要是需要频繁的调度,让我们看一下具体的差距细节:
缺少应用是第一成员的的概念
批任务经常是需要以顺序的方式进行调度。例如,spark driver pods需要比work pod 早调度,而应用第一的概念能够保证顺序部署。而且,这种能够让管理员可视化任务的调度以便于进行debug。
缺少有效的资源配额管理能力
在多租户的场景下运行spark,kubernetes能够使用namespace资源配额的方式来管理资源。然而这在实现上有挑战的:
- spark任务在资源使用上是动态的,namespace的资源配额是固定的,并且在admission阶段就确认下来的。如果不满足namespace的配额要求,请求是会被拒绝的。这就要求spark任务实现一个重试机制去请求pod,而不是让kubernetes本身去排队请求运行。
- namespace资源配额是扁平的,并不支持继承关系的资源配额管理。
然而很多时候,当kubernetes的namespace的资源配额不能满足事先分配好的资源的时候,用户可能会在批任务的时候存在饥饿。一个弹性的继承优先级的任务管理目前是不存在的。
缺少用户间的资源公平调度
在生产环境下,我们经常会发现 kubernetes默认的调度器不能够有效的管理多种任务类型负载,不能提供公平的资源负载.这些关键的原因如下:
- 在生产环境下的批任务管理经常会有大量的用户在操作
- 在一些资源紧张的生产环境下,多种任务负载在运行,这很有可能spark driver pods会占用一个namespace的所有的资源。这种场景下给资源共享提供了一个很大的挑战
- 失败的任务很容易占用资源不释放,这会影响生产环境的负载
严格的调度的延迟的SLA要求
大部分繁忙的生产环境下,对于批任务每天会运行上千个job和task。这些任务负载需要大量的并行容器部署并且这种容器的生命周期是比较短的(从分钟到小时不等)。这就产生了对于成千上万个pod和容器部署调度的需求。使用kubernetes默认的调度器能够带来额外的延迟,这就导致了丢失了SLAs
Apache YuniKorn 怎么助力
Apache YuniKorn的总览
YuniKorn是对kubernetes 服务和批任务负载的调度增强。YuniKorn能够代替Kubernetes默认的调度器,当然也能兼容在部署场景下k8s默认的调度器。
YuniKorn 带来了一个统一的,跨平台的混合部署无状态的批任务和有转台的服务的调度经验
YuniKorn vs Kubernetes default scheduler:对比
| 特性 | 默认的调度器 | YuniKorn | 说明 |
|---|---|---|---|
| 应用的概念 | 不支持 | 支持 | 应用在YuniKorn是第一公民。YuniKorn调度应用伴随着提交顺序,优先级,资源使用等 |
| 任务顺序 | 不支持 | 支持 | YuniKorn支持FIFO/FAIR/Prioriry 任务顺序优先级 |
| 细粒度的资源管理 | 不支持 | 支持 | 以继承性的队列方式管理集群资源。队列提供了最大最小的资源保证 |
| 资源的公平性 | 不支持 | 支持 | 对所有的应用跨应用和队列的资源公平竞争 |
| 本地支持大数据的任务 | 不支持 | 支持 | 默认的调度器关注于长服务。YuniKorn设计为大数据应用的负载调度,原生支持运行spark/Flink/TensorFlow等等 |
| 扩展行和性能 | 不支持 | 支持 | YuniKorn对性能做了优化,它适合大吞吐以及大规模的环境 |
YuniKorn怎么助力spark on k8s
YuniKorn 有丰富的特性去帮助spark更好的运行在kubernetes上。具体的步骤可以参考这里
YuniKorn赋能spark on k8s更多细节参考: Cloud-Native Spark Scheduling with YuniKorn Scheduler in Spark & AI summit 2020
让我看一下使用场景,以及YuniKorn怎么助力更好的资源调度spark
多用户同时运行不同的spark任务
当更多的用户一起运行任务的时候,隔离任务和提供任务的资源公平和优先级就会变得非常困难了。YuniKorn调度通过使用资源队列提供了一种可选的解决方案。
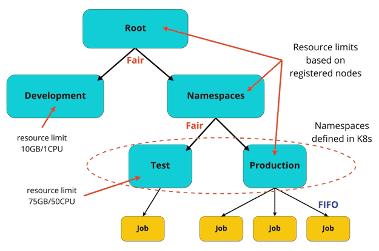
在YuniKorn以上队列的例子中,kubernetes中定义的namespaces被映射成了队列。Test和DevDevelopment队列有固定的资源限制。所有其他的队列只是被集群的大小所限制。任务在production队列以FIFO方式调度
优点:
- one YuniKorn队列会自动匹配到一个namespace下
- 队列的资源是弹性的,可以配置为最大最小值
- 资源的公平性能够避免资源饥饿
YuniKorn 能够无缝的管理kubernetes的资源配额管理,它能够替代namespace资源配额。YuniKorn的资源配额管理能够让pod的请求排队,并且能够基于可插拔的调度插件进行有限资源的共享。这些无需任何配置,如重试spark pod提交,就能实现。
建立基于组织的资源分配模型
在大的生产环境中,多个用户将会同时运行多个任务负载。而且大部分用户的资源分配都是基于组织架构限制的。这种资源分配模型的建立有利于集群资源的使用边界管理。
YuniKorn提供了一种继承的队列的资源管理。在多用户的环境下通过可继承的队列进行细粒度的资源管理是可以的。YuniKorn 队列可以静态的配置,也可以动态的通过资源管理进行管理。
在多用户的集群下提供更好的spark job的SLA
一般来说在多用户的集群下的ETL任务需要更加便捷的一中定义组织化的队列。这种策略能够帮助我们定义更加严格的SLA 任务的执行。
YuniKorn能够让管理者让任务以FIFO/FAIR的方式运行,这个StateAwarePolicy顺序任务,以一个接一个的方式运行。这在提交大量批任务的时候避免的竞争,如在同一个集群的spark任务。通过指定任务的顺序,也能提高任务调度的可预见性。
对于spark任务的调度支持各种k8s特性
YuniKorn 完全兼容k8s的主特性,用户可以无感知的替换调度器。YuniKorn 支持k8s所有调度原生的8s语义,如标签选择,pod的亲和性,pv/pvcs等,YuniKorn也兼容资源管理命令行和组件,像cordon nodes和通过kubectl获取事件等。
本文翻译自Apache Spark on Kubernetes:How Apache YuniKorn(Incubating) helps
以上是关于spark on k8s:apache YuniKorn(Incubating)的助力的主要内容,如果未能解决你的问题,请参考以下文章