K8S的资源对齐:K8S学习篇3
Posted 大魏分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S的资源对齐:K8S学习篇3相关的知识,希望对你有一定的参考价值。
计算机从负载和CPU到存储和I / O的工作负载所使用资源的物理布局,会对应用性能产生巨大影响,通常称为资源拓扑: Topology Manager
资源拓扑为何重要?
非统一内存访问(NUMA)是一种计算平台体系结构,它允许不同的CPU以不同的速度访问不同的内存区域。CPU,内存和PCI设备的相对位置就是我们所说的资源拓扑。
该体系结构具有主要优势。任何CPU内核都可以访问系统上的所有内存,但是性能存在一些潜在的缺陷。例如,在下图中,靠近CPU核心1的内存将比靠近CPU核心7的内存更快地被CPU核心1访问。
对于受I / O限制的工作负载,遥远的NUMA区域上的网络接口会减慢信息到达应用程序的速度。在这种情况下,高性能的工作负载(如运行5G网络的工作负载)将无法正常运行。
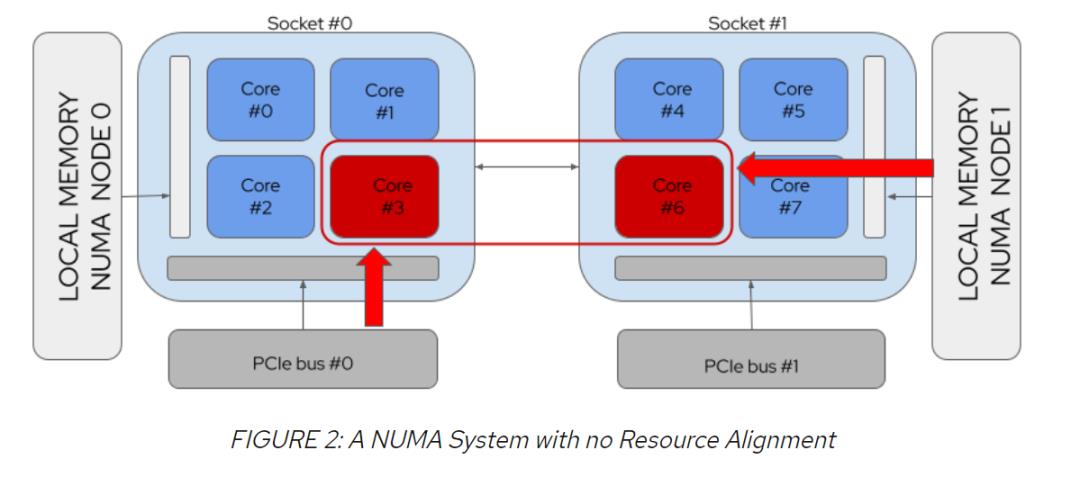
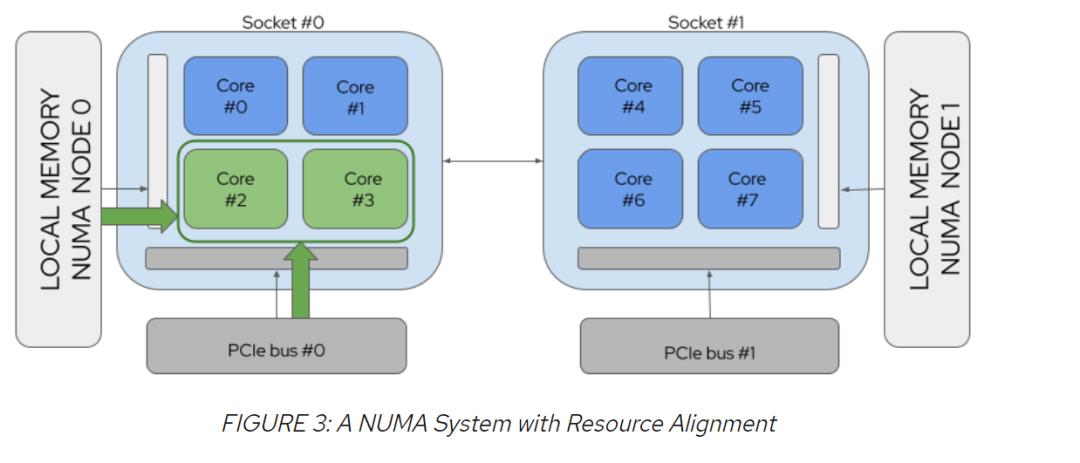
以请求2个CPU和PCI设备的Pod为例,图2显示了资源未与NUMA对齐的情况,而图3显示了资源与NUMA对齐的情况:
实现资源对齐有两种方式:
一种选择是用VM替换裸机部署,即vNuma
另一种选择是限制开发人员可用的pod配置。
将Pod分配给节点时,Kubernetes默认调度器是否考虑资源拓扑?
Kubernetes拓扑管理器允许工作负载在针对低延迟而优化的环境中运行。关键性能工作负载需要拓扑信息,才能在电信、高功率计算(HPC)和物联网(IoT)等行业中使用位于同一位置的CPU内核和设备,但是当前的本机调度程序不会根据其拓扑选择节点。发生这种情况的原因是调度程序缺乏对资源拓扑的了解,这可能导致无法预测的应用程序性能。通常,这意味着性能不足,在最坏的情况下,这意味着资源请求和kubelet策略的完全不匹配,如计划注定要失败的Pod,可能会进入失败循环。
将群集级拓扑暴露给调度程序使它能够做出智能NUMA感知的放置决策,从而优化整个群集的工作负载性能。
在Kubernetes中启用拓扑感知调度的商业案例是什么?
公司可以通过提供公共云或通过将云解决方案出售给第三方(例如,针对NFV用例的电信运营商和他人)来开展业务。对于公共云,云提供商在其最终用户协议或公开报价中只能提供具有固定数量资源的资费。在这种情况下,资源对齐问题由IAAS层面解决。
另一个案例是,一家公司出售云解决方案,而客户则需要更大的灵活性。它们的灵活性是在裸机上工作的能力以及请求任何数量和种类的资源的能力。因此,对于那些将云解决方案出售给第三方的公司来说,使kube Scheduler拓扑结构感知的解决方案很重要。
在节点级别,资源对齐由拓扑管理器(Kubelet的本机部分)处理。默认情况下,Kubelet不会尝试应用任何特定的约束,但是可以设置拓扑管理器策略以强制资源对齐。此博客的第1部分在这里。
拓扑管理器是Kubernetes资源拓扑管理系统的关键部分。它确保Pod在进入运行时时获得正确对齐的资源。但是,必须避免让Kubelet了解有关群集的所有信息。知识鸿沟可能会导致失败,从意外的低性能到完全停止应用程序。
一旦Pod运行在节点上,此系统将运行良好。Kubelet可以考虑可用资源,并确保pod获得最佳对齐。但是,Kubelet无法做到的是告诉我们集群中其他地方是否存在更好的资源组合。这是调度程序的工作。
协同工作:拓扑管理器和拓扑感知调度。
当工作负载请求与计算节点上的策略集完全不匹配时,当今资源拓扑最坏的情况就会出现。如果Kubelet尝试对资源拓扑实施“单节点”策略,则这种不匹配会导致pod失败。这在群集中呈现为拓扑亲和性错误。
承担繁重的工作量(Pod 1),要求其Pod规范中有20个专用CPU,并需要两个工作节点:节点A总共有20个核心,每个NUMA区域中有10个内核;节点B有总共40个核心,每个NUMA区域中有20个核心。节点A和节点B都在运行单数字区域策略。
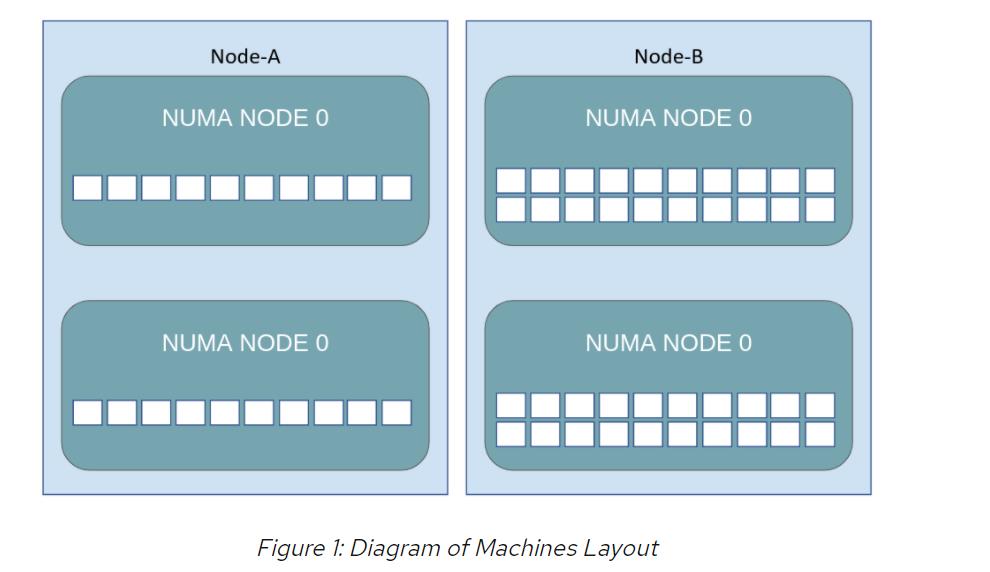
从上图可以清楚地看出,只有节点B可以满足Pod Spec 1的资源要求,但是从调度程序的角度来看,当它读取Kubernetes API时,它一点都不清晰。看到的是:
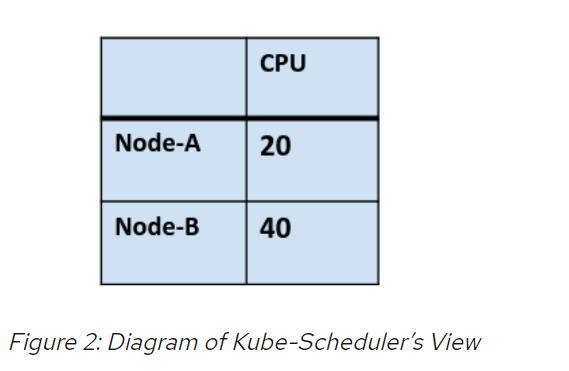
启用拓扑管理器后,调度程序将节点A和节点B视为运行Pod 1的合适平台。但是,将Pod 1部署到节点A时,我们会收到“拓扑相似性错误”。这会阻止工作负载运行,并且可能对集群产生影响。有关此问题的更多讨论,请参阅不了解拓扑的调度程序会导致吊舱创建失控。
如果启用拓扑感知调度,则调度程序将开始查看作为简化节点级资源视图基础的资源拓扑复杂性。通过在调度程序中启用拓扑意识,可以看到以下内容:
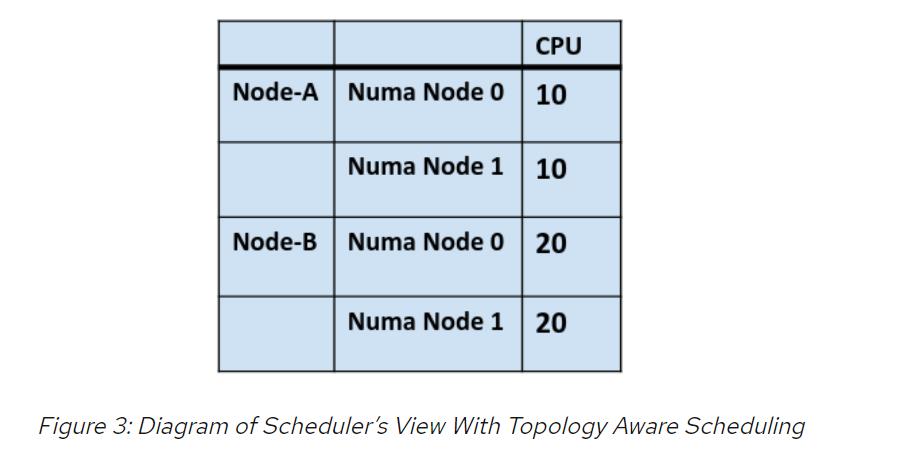
上面的视图意味着调度程序不会将Pod 1部署到节点A,从而避免了拓扑相似性错误。随着将更多不同的资源请求添加到Pod规范并将更多异构类型的计算机添加到群集,以上文章中描述的情况变得越来越可能。
有关拓扑管理器的更多信息,请参见Kubernetes拓扑管理器移至Beta-对齐!
这会给Kubernetes带来什么?
拓扑感知调度旨在支持新型工作负载以在裸机Kubernetes集群上运行。
该设计主要涉及在Kubernetes集群中提供一致且可预测的资源对齐决策。有了它,就永远不要将启用的工作负载放在无法满足其拓扑首选项要求的资源需求的平台上。
高性能和低延迟计算依赖于几乎绝对的资源保证来实现可预测的性能。对这些工作负载进行了调整,以确保可以从平台上获得绝对最大的性能,并在工作负载的整个生命周期中将干扰降到最低。
在当今的Kubernetes中,基于NUMA的服务器需要重大的变通办法才能提供这种性能。Kubernetes之外的任何事物都会实现约束(例如具有虚拟化的节点),或者会降低Node和Pod配置的灵活性。
诸如5G核心和边缘网络中的数据包处理工作负载以及机器学习工作负载,是资源拓扑调整的首要目标。但是,有很多工作负载可能会受益于系统能够提供的保证。
这一切如何运作?
在本系列的后面部分,我们将深入探讨真正推动拓扑感知调度的因素。从总体上讲,解决方案由三个部分组成:
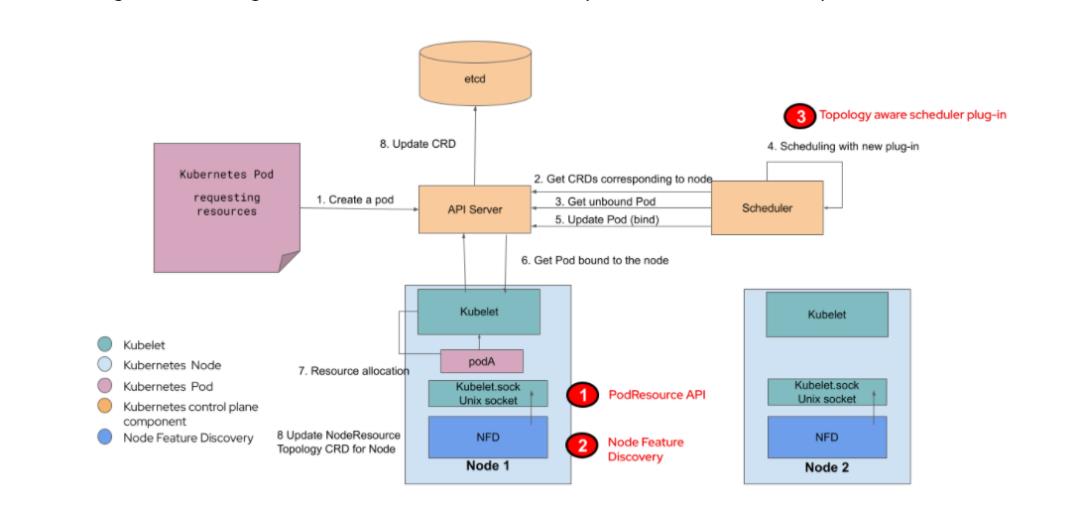
1)Kubelet负责通过PodResource API提供有关现有资源拓扑的信息。此API作为“拓扑感知调度”工作的一部分得到了增强。
2)节点功能发现将从Kubelet端点读取,并通过与群集中的节点相对应的自定义资源(CR)使资源拓扑信息可用。
3)Kubernetes Scheduler读取Node Featured Discovery导出的信息,并阻止对无法满足特定工作负载需求的节点的调度。(Node Featured Discovery在OpenShift中是个Operator)
拓扑感知调度与现有的Kubernetes组件集成在一起,包括社区项目Node Feature Discovery,从而为集群级拓扑管理提供了一个嵌入式解决方案:
这些组件通过Kubernetes API相互通信。
OpenShift从4.3版本开始就正式发布Topology Manager功能了。详细配置见:
https://docs.openshift.com/container-platform/4.6/scalability_and_performance/using-topology-manager.html
补充说明:Topology Manager和Node Featured Discovery结合使用,Node Featured Discovery在OpenShift中是个Operator
The NFD operator creates and maintains the Node Feature Discovery (NFD) on Kubernetes. It detects hardware features available on each node in a Kubernetes cluster, and advertises those features using node labels.
NSD的详细配置参见:
https://www.openshift.com/blog/part-1-how-to-enable-hardware-accelerators-on-openshift
以上是关于K8S的资源对齐:K8S学习篇3的主要内容,如果未能解决你的问题,请参考以下文章