HashMap
概述
HashMap是在JDK1.2中引入的一种K/V对形式的集合类.
在底层,HashMap通过数组和单链表组合的结构形式来存储数据,数组在这作为一个外部结构,数组中的每个节点被称做Bucket(桶),而桶是由在单链表构成,JDK1.8之后为了解决长链表下,查询和插入效率低下的情况,又引入了红黑树的作为桶的实现方式,
桶中的各节点是由HashMap定义的Node内部类生成的,是普通的链表节点类.
注意:HashMap是线程不安全的,在JDK1.8之前多线程情况下甚至可能会出现环路(后面会讲),所以多线程状态下还是要使用ConcurrentHashMap的.
光从名字上应该也能猜到,HashMap肯定是基于hash算法实现的,这种基于hash实现的map叫做散列表(hash table)。
散列表中维护了一个数组,数组的每一个元素被称为一个桶(bucket),当你传入一个key = "a"进行查询时,散列表会先把key传入散列(hash)函数中进行寻址,得到的结果就是数组的下标,然后再通过这个下标访问数组即可得到相关联的值。
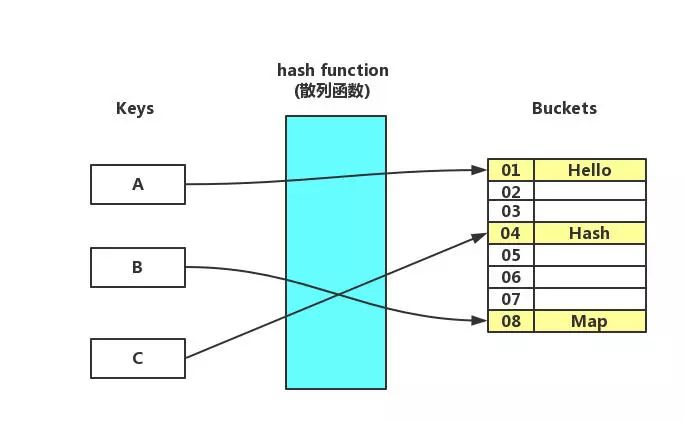
我们都知道数组中数据的组织方式是线性的,它会直接分配一串连续的内存地址序列,要找到一个元素只需要根据下标来计算地址的偏移量即可(查找一个元素的起始地址为:数组的起始地址加上下标乘以该元素类型占用的地址大小)。因此散列表在理想的情况下,各种操作的时间复杂度只有O(1),这甚至超过了二叉查找树,虽然理想的情况并不总是满足的,关于这点之后我们还会提及。
为什么是hash?
hash算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据(输入)映射到一个固定大小的序列(输出)上,这个序列被称为hash code、数据摘要或者指纹。比较出名的hash算法有MD5、SHA。
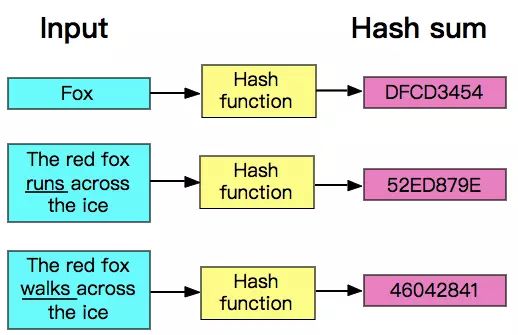
hash是具有唯一性且不可逆的,唯一性指的是相同的输入产生的hash code永远是一样的,而不可逆也比较容易理解,数据摘要算法并不是压缩算法,它只是生成了一个该数据的摘要,没有将数据进行压缩。压缩算法一般都是使用一种更节省空间的编码规则将数据重新编码,解压缩只需要按着编码规则解码就是了,试想一下,一个几百MB甚至几GB的数据生成的hash code都只是一个拥有固定长度的序列,如果再能逆向解压缩,那么其他压缩算法该情何以堪?
以上是关于深入解析HashiMap那些不为人知的事儿的主要内容,如果未能解决你的问题,请参考以下文章