清华毕业大牛,带你深入解析大数据基础编程实验和案例教程文档
Posted king哥Java架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华毕业大牛,带你深入解析大数据基础编程实验和案例教程文档相关的知识,希望对你有一定的参考价值。
前言
大数据带来了信息技术的巨大变革,并深刻影响着社会生产和人民生活的方方面面。
大数据专业人才的培养是世界各国新一轮科技较量的基础,高等院校承担着大数据人才培养的重任,需要及时建立大数据课程体系,为社会培养和输送一大批具备大数据专业素养的高级人才,满足社会对大数据人才日益旺盛的需求。
本文侧重于介绍大数据软件的安装、使用和基础编程方法,并提供大量实验和案例。
由于大数据软件都是开源软件,安装过程一般比较复杂,也很耗费时间。
为了尽量减少读者搭建大数据实验环境时的障碍,小编在本文中详细写出了各种大数据软件的详细安装过程,可以确保读者顺利完成大数据实验环境搭建。
因为内容实在是太多了,只是把部分知识点拿出来介绍了一下,每小节都有更加细化的内容。

主要内容
本文共13章,详细介绍系统和软件的安装、使用以及基础编程方法。
第1章介绍大数据的关键技术和代表性软件,帮助读者形成对大数据技术及其代表性软件的总体性认识。
大数据的时代已经到来,大数据作为继云计算、物联网之后IT行业又一颠覆性的技术,备受关注。大数据无处不在,包括金融、汽车.零售、餐饮、电信、能源、政务、医疗、体育、娱乐等在内的社会各行各业,都融入了大数据之中,大数据对人类的社会生产和生活必将产生重大而深远的影响。
本章首先介绍大数据关键技术和各类典型的大数据软件,帮助读者形成对大数据技术及其代表性软件的总体性认识;然后,给出本书的整体内容安排,帮助读者快速找到相关技术所对应的章节;最后,详细给出与本书配套的在线资源,帮助读者更好.更深入地学习理解相关大数据技术知识。

第2章介绍Linux系统的安装和使用方法,为后面其他章节的学习奠定基础。
Hadoop是目前处于主流地位的大数据软件,尽管Hadoop本身可以运行在Linux、Windows和其他一些类UNIX系统(如FreeBSD.OpenBSD、Solaris等)之.上,但是, Hadoop官方真正支持的作业平台只有Linux。这就导致其他平台在运行Hadoop时,往往需要安装很多其他的包来提供一些Linux 操作系统的功能,以配合Hadoop 的执行。例如,Windows在运行Hadoop时,需要安装Cygwin等软件。鉴于Hadoop、Spark等大数据软件大多数都是运行在Linux系统上,因此,本书采用Linux 系统安装各种常用大数据软件、开展基础编程。
首先,本章简要介绍Linux系统;然后,详细介绍Linux系统的安装方法、Linux系统及相关软件的基本使用方法,为后面章节内容的学习奠定基础;最后,给出关于教程内容的一些约定。


第3章介绍分布式计算框架Hadoop的安装和使用方法。
Hadoop是-一个开源的、可运行于大规模集群上的分布式计算平台,它主要包含分布式并行编程模型MapReduce和分布式文件系统HDFS等功能,已经在业内得到广泛的应用。
借助于Hadoop,程序员可以轻松地编写分布式并行程序,将其运行于计算机集群上,完成海量数据的存储与处理分析。
本章首先简要介绍Hadoop的发展情况;然后,阐述安装Hadoop之前的一些必要准备工作;最后,介绍安装Hadoop的具体方法,包括单机模式、伪分布式模式、分布式模式以及.使用Docker搭建Hadoop集群。

第4章介绍分布式文件系统HDFS的基础编程方法。
Hadoop分布式文件系统( Hadoop Distributed File System, HDFS)是Hadoop核心组件之一,它开源实现了谷歌分布式文件系统(Google File System,GFS)的基本思想。HDFS支持流数据读取和处理超大规模文件,并能够运行在由廉价的普通机器组成的集群上,这主要得益于HDFS在设计之初就充分考虑了实际应用环境的特点,即硬件出错在普通服务器集群中是一-种常态,而不是异常,因此,HDFS在设计上采取了多种机制保证在硬件出错的环境中实现数据的完整性。安装Hadoop以后,就已经包含了HDFS组件,不需要另外安装。
本章首先介绍HDFS操作常用的Shell命令;然后介绍利用HDFS提供的Web管理界面查看HDFS相关信息;最后,详细讲解如何编写和运行访问HDFS的Java应用程序。

第5章介绍分布式数据库HBase的安装和基础编程方法。
HBase是-一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价的计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。Hadoop 安装以后,不包含HBase组件,需要另外安装。
本章首先介绍HBase 的安装方法,并介绍HBase的两种不同模式的配置方法,包括单机模式和伪分布式模式,然后介绍一些操作HBase的常用的Shell命令,最后,介绍如何使用Eclipse开发可以操作HBase数据库的Java应用程序。

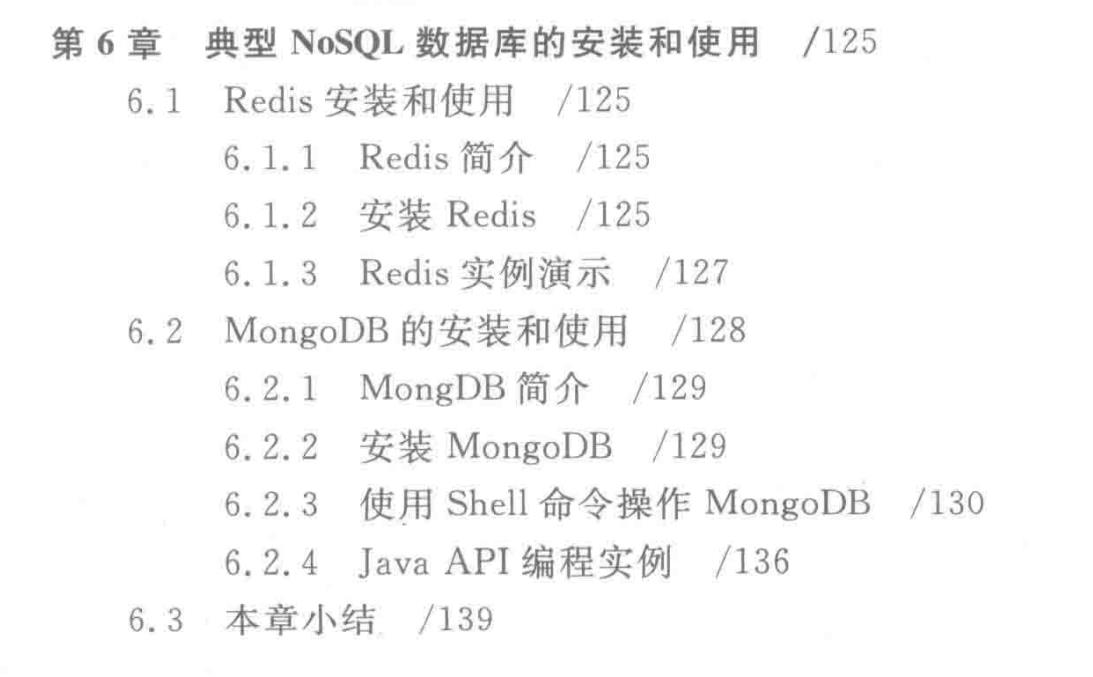
第6章介绍典型No-SQL数据库的安装和使用方法,包括键值数据库Redis和文档数据库MongoDB。
NoSQL数据库是一大类非关系型数据库的统称,较好地满足了大数据时代不同类型数据的存储需求,开始得到越来越广泛的应用。NoSQL数据库主要包括键值数据库、列族数据库、文档数据库和图数据库4种类型,不同产品都有各自的应用场合。
本章重点介绍键值数据库Redis和文档数据库MongoDB的安装和使用方法,并给出简单的编程实例。
第7章介绍如何编写基本的MapReduce程序。
MapReduce是谷歌公司的核心计算模型,Hadoop开源实现了MapReduce。
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象到了两个函数: Map和Reduce,并极大地方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自已的程序运行在分布式系统上,完成海量数据的计算。
本章以一个词频统计任务为主线,详细介绍MapReduce基础编程方法。首先,阐述词频统计的任务要求;其次,介绍MapReduce程序的具体编写方法;最后,阐述如何编译运行程序。

第8章介绍基于Hadoop的数据仓库Hive的安装和使用方法。
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。Hive 的学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语言一HiveQL,可以通过HiveQL语句快速实现简单的MapReduce统计,Hive自身可以将HiveQL语句快速转换成MapReduce任务进行运行,而不必开发专门的MapReduce应用程序,因而十分适合数据仓库的统计分析。
本章首先介绍Hive的安装方法;然后介绍Hive 的数据类型和基本操作;最后给出了一个WordCount应用实例,来展示Hive编程的优势。

第9章介绍基于内存的分布式计算框架Spark的安装和基础编程方法。
Spark最初诞生于美国加州大学伯克利分校的AMP实验室,是–个可应用于大规模数据处理的分布式计算框架,如今是Apache软件基金会下的顶级开源项目之–。Spark可以独立安装使用,也可以和Hadoop一起安装使用。本文采用和Hadoop一起安装使用,这样,就可以让Spark使用HDFS存取数据。
本章首先介绍Spark的安装方法;然后介绍如何使用SparkShell编写运行代码;最后介绍如何使用Scala语言和Java语言编写Spark独立应用程序。

第10章介绍5种典型的可视化工具的安装和使用方法,包括Easel. ly,D3、魔镜、ECharts.Tab-leau等。
数据可视化是大数据分析的最后环节,也是非常关键的一环。在大数据时代,数据容量和复杂性的不断增加,限制了普通用户从大数据中直接获取知识,可视化的需求越来越大,依靠可视化手段进行数据分析必将成为大数据分析流程的主要环节之- -。让“ 茫茫数据”以可视化的方式呈现,让枯燥的数据以简单友好的图表形式展现出来,可以让数据变得更加通俗易懂,有助于用户更加方便快捷地理解数据的深层次含义,有效参与复杂的数据分析过程,提升数据分析效率,改善数据分析效果。
本章分别介绍了5种典型的可视化工具的使用方法,包括Easel.ly、D3、Tableau、魔镜、ECharts等。

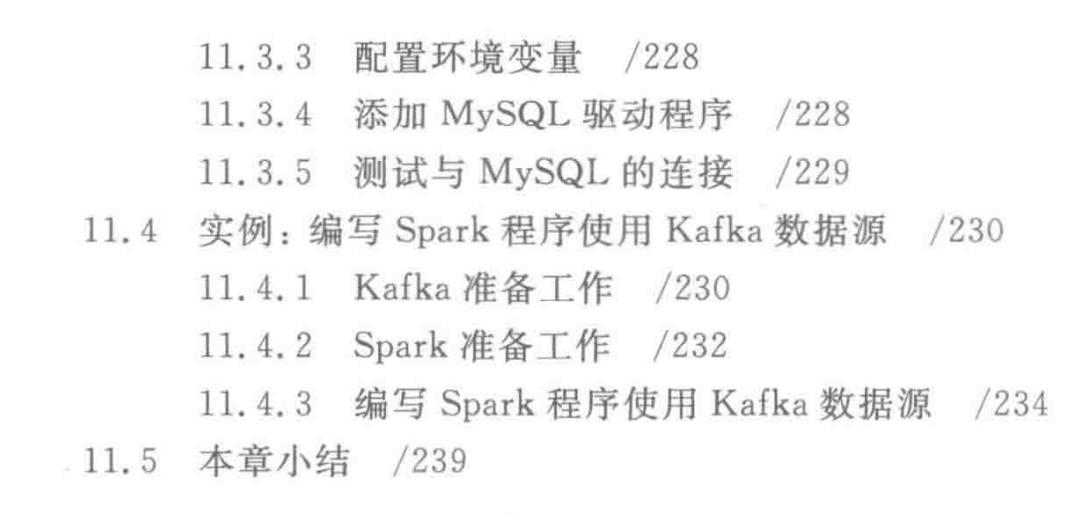
第11章介绍数据采集工具的安装和使用方法,包括Flume、Kafka和Sqoop。
数据采集是大数据分析全流程的重要环节,典型的数据采集工具包括ETL工具、日志采集工具(如Flume和Kafka) 、数据迁移工具(如Sqoop)等。
本章重点选择了具有代表性的数据采集工具进行介绍,包括日志采集工具Flume、Kafka和数据迁移工具Sqoop,详细介绍这些工具的安装和使用方法,同时给出相关实例来加深对工具作用及其使用方法的理解。

第12章介绍一个大数据课程综合实验案例,即网站用户购物行为分析。
本案例涉及数据预处理、存储、查询和可视化分析等数据处理全流程所涉及的各种典型操作,涵盖Linux、mysql、Hadoop,HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用方法。本案例适合高校大数据教学,可以作为学习大数据课程后的综合实践案例。通过本案例,有助于读者综合运用大数据课程知识和各种工具软件,实现数据全流程操作。



第13章通过5个实验让读者加深对知识的理解。
实验一:熟悉常用的Linux操作和Hadoop操作
实验二:熟悉常用的HDFS操作
实验三:熟悉常用的HBase操作
实验四:NoSQL和关系数据库的操作比较
实验五: MapReduce初级编程实践

由于篇幅限制,小编这里就不做过多的介绍了,需要【大数据基础编程、实验和案例教程】技术文档的小伙伴,可以在文末获取免费领取方式。

本文总述
步步引导,循序渐进详尽的安装指南为顺利搭建大数据实验环境铺平道路;
深入浅出,去粗取精丰富的代码实例帮助快速 掌握大数据基础编程方法;
精心设计,巧妙融合五套大数据实验题 目促进理论与编程知识的消化和吸收;
结合理论,联系实际大数据课程综合实验案例精彩 呈现大数据分析全流程。

因为这份文档包含的内容实在是太多了 ,不能够很详细地给大家展示出来全部的内容。需要完整版文档的小伙伴,可以看向下面来获取!
需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于清华毕业大牛,带你深入解析大数据基础编程实验和案例教程文档的主要内容,如果未能解决你的问题,请参考以下文章