架构解密分布式到微服务:聊聊分布式计算,适用面很广Storm
Posted king哥Java架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构解密分布式到微服务:聊聊分布式计算,适用面很广Storm相关的知识,希望对你有一定的参考价值。
适用面很广的Storm
与之前提到的Actor面向单条消息的分布式计算模型不同,Apache Storm(后简称Storm)提供的是面向连续的消息流(Stream)的一种通用的分布式计算解决框架。但两者都拥有简单、唯美的编程模型,提供的编程模型很简单也足够灵活,具备很强的适用性,可以在多个领域发挥重要作用。
Storm是一个免费、开源的分布式实时计算系统,它的前身是Twitter Storm,后来被捐献给Apache并成功孵化。大家在讨论Apache Spark(后简称Spark)与Storm之间的流数据处理能力时,往往会给出共识性的结论:Storm确实拥有更好的规模化能力与速度表现,但使用难度较大;另外,Storm逐渐被Spark 取代,因此选择更新且更热门的Spark 往往成为主流。
为了扭转颓势,Storm于 2016年4月发布了重要的1.0版本,处理速度大幅增加,延时减少60%,在实际应用中至少提升3倍以上的性能,在某些场合下甚至可以提升10倍以上的速度。另外,新版本中的大部分改动都使得Storm更易于使用,比如增加了支持流式处理的滑动窗口API的支持,这与Spark Stream类似。从 Storm 1.0版本的革新性变化,我们看到 Storm正在尝试重新打破Spark一家独大的局面,希望在实时流领域重新赢回更多的话语权。
Storm的流式编程模型简单、灵活,同时支持多种编程语言,包括科学计算中常见的Python,处理速度非常快,每节点每秒可以处理百万级的元组(Tuples),因此,Storm有很多应用场景,例如实时数据分析、机器学习、持续计算、分布式RPC、ETL等。采用了Storm的一些知名企业有百度、阿里巴巴、雅虎、爱奇艺、Twitter、Spotify、Yelp、Rubicon、OOYALA、PARC、Cerner、KLOUT等。
下图显示了Storm的流式计算模型。运行在 Storm集群上的是Topology(拓扑),Topology与Hadoop 上的 MapReduce Job之间的最大区别是后者最终会结束,而前者会永远运行,除非被手动关掉。
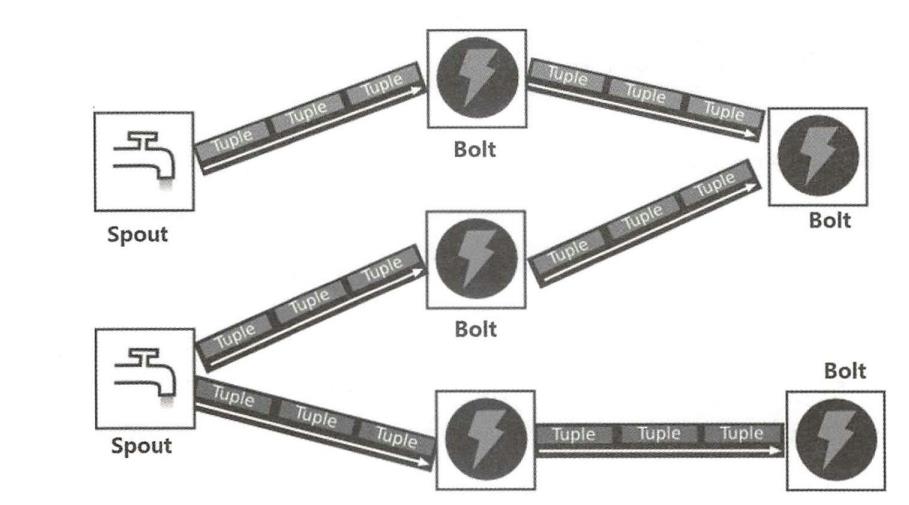
一个Topology是由多个Spout和 Bolt节点组成的有向无环图,节点之间通过StreamGrouping 进行连接,在Topology 里流动的数据是一种被称为Tuple序列的特殊数据结构——Stream。由Tuple序列构成的Stream没有边界,有始无终,源源不断地从一个或多个Spout节点发出,流向有向图里的后继Blot节点并被层层加工和转换,最终产生业务所需要的处理结果。
作为消息源的Spout节点分为两类:可靠的和不可靠的。对于一个可靠的Spout来说,如果它发出的某个Tuple没有被成功处理,则Spout可以重新发送一次;但对于不可靠的Spout,Tuple一旦发出就不能重发了。所有消息处理逻辑都被封装在Bolt里,一个 Bolt可以做很多事情,例如过滤、聚合、查询数据库等。按照软件设计中的单一职责原则,每种 Bolt都应该只承担一项职责,多种 Bolt 相互配合,从而实现复杂的消息流处理逻辑。
Topology 中的最后一个重要概念是Stream grouping,它用来定义每个Bolt接收什么样的流作为输入,比如Shuffle Grouping(随机分组〉随机派发Stream里面的Tuple,保证每个Bolt接收到的Tuple数量都大致相同;Fields Grouping (按字段分组)则可以按照Tuple里的某个属性字段的值来分组,类似于分片方式,具有同样字段值的Tuple会被分到同一个Bolt 里;DirectGrouping (直接分组)则由用户通过编程来控制如何分发Tuple。用户开发的Topology最终会被打包为一个JAR文件并通过工具上传到Storm集群中,最终触发Topology 的运行。
如下所示是Storm集群架构图。
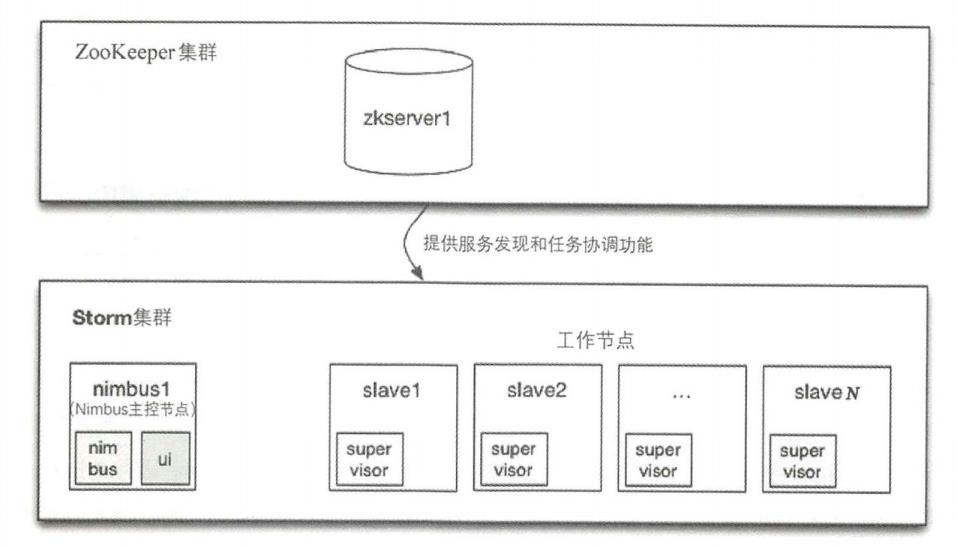
从上图可以看到,Storm集群由3部分组成,其中 ZooKeeper 主要用来实现服务发现机制及任务和系统状态数据的保存;Nimbus 则是Storm集群的 Master,它其实是一个Thrift RPC(又叫RPC)协议的服务端,处理客户端发起的RPC调用请求,例如提交一个计算拓扑作业的请求,Nimbus在启动时会连接ZooKeeper,并在ZooKeeper中创建节点以保存作业运行过程中的所有状态信息。同时,任务分配是 Nimbus通过ZooKeeper实现的,Nimbus将任务分配信息(TaskAssignment)写到ZooKeeper 中, Supervisor随后会从ZooKeeper中读取这些信息,并启动Worker来执行任务。
Supervisor是Slave节点,工作节点对于集群而言就是计算资源,属于“工人”。总体来看,Supervisor其实是一个包括多进程的复杂子系统,如下图所示给出了Supervisor 的架构细节。每个Supervisor节点都会启动多个Worker进程,具体启动几个Worker,取决于Slot配置参数列表,每个Slot 都代表一个Worker进程的监听端口号。在一个Worker进程里会运行多个Task。Task指的是执行某个具体的Spout或Bolt 实例的代码逻辑,每个Task 都会在Worker 的一个线程中被调度运行,在任务分配过程中,Nimbus根据Topology 设定的Spout、Bolt 数量进行调度,尽量把Sprout与 Bolt平均分配到每个Worker 上。
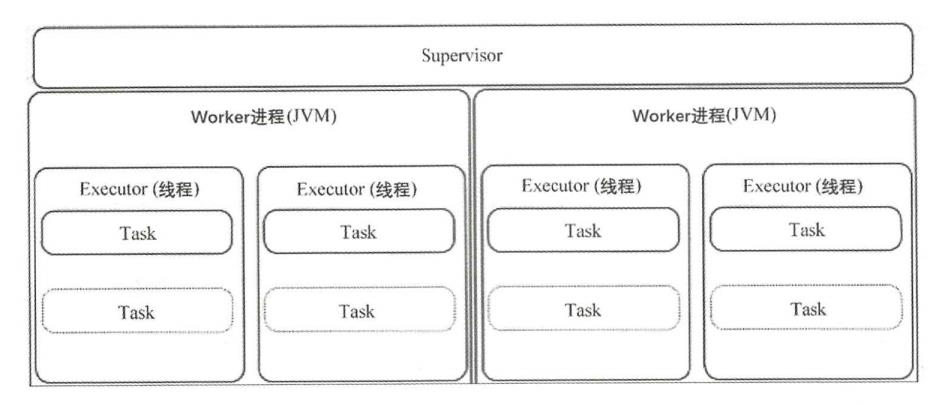
在执行任务之前,每个节点上的Supervisor都会从Nimbus下载Topology代码到本地目录,在运行期间,Supervisor与其上的Task也会定期发送心跳信息到ZooKeeper,因此Nimbus可以监控整个Storm集群的状态,从而重启一些挂掉的Task。
Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的,所有状态要么被保存在ZooKeeper中,要么被保存在本地磁盘中。这也就意味着你可以用kill-9来删除 Nimbus和Supervisor进程,然后重启它们,就好像什么都没有发生,使得Storm集群异常稳定。如果一些机器意外宕机,那么它上面的所有任务就会被转移到其他机器上,Storm 会自动重新分配失败的任务,并且保证不会有数据丢失。但如果 Nimbus进程挂掉,无法管理现有的拓扑作业,如果此刻某个Supervisor节点宕机,则已有的拓扑作业无法完成故障转移和恢复,新的拓扑作业也就无法被提交到Storm集群中了。我们知道Nimbus是有状态的,其中最重要的状态数据是Client提交的Topology的二进制代码(JAR文件),这些数据被存放在 Nimbus 所在机器的本地磁盘中,所以Nimbus 作为集群的Master,有必要保证 Nimbus 的HA。为此,Storm 实现了基于ZooKeeper的 Nimbus Master选举和切换机制。假设我们的Nimbus由3个节点组成,并且配置的拓扑副本数为2,目前在集群里运行了4个拓扑作业,以此来举例说明Nimbus 的选举切换过程。
首先,在当前的Nimbus Leader节点上保存了4个Topology 的所有状态数据,为了满足拓扑副本数为2个的要求,在 nonleader-1节点上保存了两个Topology的状态数据,在nonleader-2节点上保存了另外两个Topology的状态数据,假如某一刻Leader节点宕机(而且磁盘损坏),则nonLeader-1节点从ZooKeeper 处立即得到这个事件通知,准备竞选新一任Leader,在准备接受Leader职位之前,它需要确保所有Topology的状态数据都在本地。若在对比本地的Topology状态数据与ZooKeeper 上的记录(路径为/storm/storms/)后发现自己还缺乏其他两个Topology状态数据,就开始尝试从其他节点上获取这些数据。首先,它会获取ZooKeeper 上的分布式锁(路径为
/storm/code-distributor/topologyld),然后去对应的节点下载这些数据;与此同时,nonLeader-2节点也会尝试竞选Leader并获取它缺失的Topology状态数据,最后至少会有一个节点拥有全部的Topology 状态数据,并成功竞选为新一任Leader。
一个Topology其实指开发一系列Spout与 Bolt类,并且用合适的Stream grouping将其串联起来,组成一个有向无环图。下面是Spout的Java接口定义:
public interface ISpout extends Serializable {
void open (Map conf,TopologyContext context,Spoutoutputcollector collector) ;void close();
void nextTuple(;
void ack(Object msgId);void fail (0bject msgId);
}
其中,open方法是Spout的初始化方法,这里传入了Storm的上下文对象及用于发送Tuple的SpoutOutputCollector对象;nextTuple方法是Spout的关键方法,这个方法用来创建源源不断的Tuple数据并发送出去; ack方法是Storm成功处理Tuple时的回调方法,在通常情况下,此方法的实现从队列中移除对应的Tuple,防止消息重发;而 fail方法是处理Tuple 失败时的回调的方法,在通常情况下,此方法的实现是将该Tuple 放回消息队列中,稍后重新发送。为了方便开发,Storm提供了一个实现了ISpout 接口的BaseRichSpout,这样我们就不用实现 close、activate、 deactivate、 ack、 fail等接口方法了。
类似地,Bolt的接口 IBolt提供了以下方法。
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!
[Java架构群]
群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
- prepare方法:此方法与Spout中的open方法类似,在集群的一个worker中的 task初始化时调用,它提供了Bolt 执行的环境。
- cleanup方法:同ISpout的close方法,在关闭前调用。
- execute方法:这是 Bolt中最关键的一个方法,对Tuple的处理都可以放到此方法中进行。Execute方法接收一个Tuple进行处理,并用OutputCollector 的 ack方法(表示成功)或fail方法(表示失败)来反馈Tuple的处理结果。
Storm提供了BaseRichBolt 抽象类,其目的就是实现IBolt接口的Bolt不用在代码中提供反馈结果了,在Storm内部会自动反馈成功。为了指导Storm 上的应用开发,Storm提供了一系列的Storm starter例子,这些例子都很实用,有些例子甚至可以直接拿来应用到实际的业务场景中。Storm starter的源码在GitHub 上也可以找到。
本节最后,我们一起分析Storm starter中的经典Topology作业 WordCountTopology 的代码,看看一个Topology是如何定义和实现的,如下所示是WordCountTopology的拓扑图。

WordCountTopology的逻辑过程大致为:首先,在 spout节点 (RandomSentenceSpout)中定义了一个字符串数组来模拟一个Stream,随机选择这个字符串数组中的一句话作为一个Tuple发送出去;随后,split节点 (SplitSentence)接收到这些Tuple后再将一句话分割成多个单词,并将每个单词作为一组Tuple发送出去;最后,这些Tuple到了count节点(WordCount),count节点将接收到的每个单词的出现次数进行累加,并将<单词:出现次数>作为新Tuple发送出去。
下面,我们看看具体的代码实现,首先是spout 节点对应的代码:
public class RandomSentenceSpout extends BaseRichSpout{private static final Logger LOG =
LoggerFactory.getLogger(RandomSentenceSpout.class);
SpoutoutputCollector_collector;
Random rand;
eoverride
public void open (Map conf,TopologyContext context,SpoutoutputCollector
collector) {
collector -collector;rand - new Random;}
coverride
public void declareOutputFields (0utputFieldsDeclarer declarer)(declarer.declare(new Fields ( "word"));
Coverride
public void nextTuple() {Utils.sleep (100);
String[] sentences = new String[]{sentence ("the cow jumped cver the moon"),
sentence("an apple a day keeps the doctor away"),
sentence ("four score and seven years ago"),sentence ( "snow white and
the seven dwarfs "),sentence("i am at two with nature"));
final string sentence = sentences[_rand.nextInt(sentences.length)];LOG.debug( ""Emitting tuple: {]",sentence);
collector.emit (new values(sentence));
}
protected String sentence (string input) {
return input;
}
}
RandomSentenceSpout的declareOutputFields方法表明这里的Tuple会输出一个名称为word的字段:
declarer.declare(new Eields ( "word"));
nextTuple方法实际上随机选择了下面某句话对应的字符串作为Tuple发送出去:
- “the cow jumped over the moon”
- “an apple a day keeps the doctor away”
- “four score and seven years ago”
- “snow white and the seven dwarfs”
- “i am at two with nature”
接下来,我们看看split节点对应的代码:
public static class SplitSentence extends ShellBolt implements IRichBolt (
public SplitSentence() {
super("python","splitsentence.py");}
@override
public void declareoutputFields (outputFieldsDeclarer declarer){
declarer.declare(new Fields ( "word"));
}
}
在SplitSentence 的代码中调用了一个 Python脚本来实现将字符串 Tuple 分割为单词Tuple的目标,splitsentence.py的代码如下:
import storm
class SplitsentenceBolt(storm.BasicBolt):
def process(self, tup):
words =tup .values[0].split("")for word in words:
storm.emit([word])
SplitSentenceBolt( .run ()
接下来,我们看看count节点对应的代码:
public static class WordCount extends BaseBasicBolt(
Map<String, Integer> counts = new HashMap<String, Integer>();@override
public void execute (Tuple tuple,Basicoutputcollector collector){String word - tuple.getString(0);
Integer count -counts.get(word);if(count ==null)
count =0;
count++;
counts.put(word, count) ;
collector .emit (new values(word, count));)
coverride
public void declareOutputFields (OutputFieldsDeclarer declarer){declarer.declare(new Fields ( "word", "count"));
}
}
我们看到,在 WordCount 内部保存了一个HashMap <String, Integer>,在收到一个单词后,就用这个HashMap去完成count分组统计功能,随后作为<String, Integer>的Tuple 发送出去。
最后,我们看看如何组装上述Spout和 Bolt,使之成为一个完整的Topology作业。这段代码被存放在
org.apache.storm.starter.WordCountTopology类中,下面是它的主要代码片段:
public class wordCountTopology extends ConfigurableTopologypublic static void main (String[] args) throws Exception {
ConfigurableTopology .start(new WordCountTopology(),args);
}
protected int run (String[]args){
TopologyBuilder builder = new TopologyBuilder( ;
builder.setSpout("spout", new RandomSentenceSpout(),5);
builder.setBolt ("split",new Splitsentence(),8) .shuffleGrouping ("spout");builder.setBolt ("count",new WordCount(),12).fieldsGrouping ("split",new
Fields( "word"));
conf.setDebug(true);
String topologyName ="word-count";
if(isLocaly {
conf.setMaxTaskParallelism(3);ttl =10;
lelse {
conf.setNumworkers(3);}
if (args !=- null & & args.length >0){topologyName = args[O];
}
return submit(topologyName,conf,builder) ;
}
}
首先,WordCountTopology 继承了ConfigurableTopology,后者通过命令行参数来决定此Topology是在本地运行(为了方便测试)还是被提交到Storm集群中运行,如果在本地运行,就会启动一个LocalCluster Storm环境来提交拓扑作业。
其次,位于run方法中的如下代码是Topology定义的关键:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout ("spout",new RandomSentenceSpout(),5);
builder.setBolt ("split",new SplitSentence(),8) .shuffleGrouping ("spout");builder.setBolt ("count", new Wordcount (),12).fieldsGrouping ("split",new
Eields( "word"));
上述代码首先定义了一个名为spout 的 Spout,对应的类是RandomSentenceSpout。在运行过程中,Storm会启动5个对应的 Task 来并发执行它,spout产生的Tuple会被随机派发( shuffleGrouping)到名为split的 Bolt上进行处理。在处理完成后产生的新的Tuple(单词)又会被按照字段word分组并派发(分片路由)到名为count的 Bolt上汇聚。
在后面的章节中,我们会继续学习Storm,用Kubernetes部署一个 Storm集群,提交上述拓扑作业并观察运行情况。
写在最后
最近我整理了整套《JAVA核心知识点总结》,说实话,作为一 名 Java 程序员,不论你需不需要面试都应该好好看下这份资料。拿到手总是不亏的~我的不少粉丝也因此拿到腾讯字节快手offer,点击下面图片↓直达领取

好了,以上就是本文的全部内容了,如果觉得有收获,记得三连,我们下期再见。
以上是关于架构解密分布式到微服务:聊聊分布式计算,适用面很广Storm的主要内容,如果未能解决你的问题,请参考以下文章