分析Spring容器管理Bean的生命周期以及依赖关系的方式
Posted king哥Java架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析Spring容器管理Bean的生命周期以及依赖关系的方式相关的知识,希望对你有一定的参考价值。
Spring容器是如何创建bean并管理bean的生命周期的呢?
Spring容器的职责:
1. 业务对象的构建管理: 即业务对象无需关心所依赖的对象如何构建如何取得,而这部分工作则转移到Spring容器中,容器需要将业务对象所依赖对象的构建逻辑从业务对象中剥离出来,以免这部分逻辑污染业务对象的实现;
2. 业务对象间的依赖绑定: Spring容器通过结合之前构建和管理的所有业务对象,以及各个对象间可以识别的依赖关系,将这些对象所依赖的对象注入绑定,从而保证每个业务对象在使用的时候,处于就绪状态。
Spring容器是如何完成这个职责的:
职责1-业务对象的构建管理
对于容器的职责1,很显然我们可以用简单工厂或工厂模式使得业务对象的使用与构建所需对象逻辑隔离开;
如下代码为使得PizzaController类从自己创建Pizza到使用简单工厂依赖PizzaSimpleFactory创建具体的Pizza类型的过程(其中Pizza为抽象接口,具体的披萨实现有MetaPizza、RedPizza等):
public class PizzaController {
public static void orderPizza(int type) throws Exception{
// 1. 根据传入的Pizza类型获取对应的Pizza实例(PizzaController自己创建)
Pizza pizza = getPizzaByType(type);
// 2. 通过特定的Pizza实例进行Pizza的烹饪
pizza.prepare();
pizza.cut();
pizza.take();
}
// 此方法容易产生变动,比如增加或删除了一种类型的Pizza
// 按照设计原则-类应该对扩展开放,对修改关闭的原则,我们应该将这块逻辑移出去
private static Pizza getPizzaByType(int type) throws Exception{
if (type == PizzaEnum.META.getType()) {
return new MetaPizza();
}
if (type == PizzaEnum.CHEESE.getType()) {
return new CheesePizza();
}
if (type == PizzaEnum.RED.getType()) {
return new RedPizza();
}
throw new Exception("current type is not support");
}
public static void main(String[] args) throws Exception{
orderPizza(2);
}
}
上述代码即为需要改变的代码,依旧由对象手动new被依赖的对象,我们首先使用简单工厂来进行对象间依赖关系的解耦。
/* 简单工厂实现 ,其实就是将getPizzaByType()方法移到了简单工厂类中*/
public class PizzaSimpleFactory {
public Pizza getPizzaByType(int type) throws Exception{
if (type == PizzaEnum.META.getType()) {
return new MetaPizza();
}
if (type == PizzaEnum.CHEESE.getType()) {
return new CheesePizza();
}
if (type == PizzaEnum.RED.getType()) {
return new RedPizza();
}
throw new Exception("current type is not support");
}
}
public class PizzaController {
PizzaSimpleFactory pizzaSimpleFactory;
// 通过构造器传入所依赖的PizzaSimpleFactory对象
public PizzaController(PizzaSimpleFactory pizzaSimpleFactory) {
this.pizzaSimpleFactory = pizzaSimpleFactory
}
public static void orderPizza(int type) throws Exception{
// 1. 根据传入的Pizza类型获取对应的Pizza实例(PizzaController依赖PizzaSimpleFactory进行创建)
Pizza pizza = pizzaSimpleFactory.getPizzaByType(type);
// 2. 通过特定的Pizza实例进行Pizza的烹饪
pizza.prepare();
pizza.cut();
pizza.take();
}
public static void main(String[] args) throws Exception{
orderPizza(2);
}
}
可以看到通过运用简单工厂,我们将对象的实例化与对象的使用解耦,摆脱了上层组件需要手动new()对象的问题。
但是上述代码还是存在一定的资源浪费问题-每次通过PizzaSimpleFactory获取对应的实例时,我们都会重新new对象,因此我们可以通过数据结构存储对象的引用从而提高资源的利用率:
public class PizzaSimpleFactory {
// 该map做为该简单工厂存储对象的容器
static Map<Integer, Pizza> pizzaMap = new HashMap<>(4);
static {
pizzaMap.put(PizzaEnum.META.getType(), new MetaPizza());
pizzaMap.put(PizzaEnum.CHEESE.getType(), new CheesePizza());
pizzaMap.put(PizzaEnum.RED.getType(), new RedPizza());
}
public Pizza getPizzaByType(int type) throws Exception{
return pizzaMap.get(type);
}
}
Spring亦是按照简单工厂的方式实现容器,在Spring中,我们亦可以通过如下代码:
// ClassPathXmlApplicationContext目前可以简单理解为存储着所有Bean的简单工厂
// 我们可以通过我们想要获取的类名去获取到对应接口实现类的引用,形式上与我们上面介绍的无异。
public void getBean() {
BeanFactory beanFactory = new ClassPathXmlApplicationContext("spring-config.xml");
UserService userService = beanFactory.getBean("userService", UserService.class);
}
在Spring容器中则通过BeanFactory充当简单工厂的角色,通过getBean()对外暴露获取相应对象的方法。(在此处先分析大体方向,后面再描述具体的细节)
职责2-业务对象间的依赖绑定
现实中的类大多并不像Pizza的子类一样,可以直接通过new()就可以初始化完成;
比如UserDao.class可能会依赖UserMapper.class等其他类,因此在初始化UserDao.class时容器需要根据依赖关系通过getBean()请求容器获取到UserMapper.class对象的引用; (PS:引入BeanFactory后,不会再在用户对象中手动new依赖对象,而都是通过getBean根据依赖关系去获取)
因此我们必须提供一种机制使得容器可以读取依赖关系,并要解决如下两个问题:容器应该从何处获取到对象间的依赖信息;容器如何解析依赖信息完成对象的初始化。
如何声明对象的依赖关系
存储对象依赖关系比较常见的方式是通过xml文件或者@AutoWired, @Resource这类描述对象依赖关系的注解,也可以通过Java配置类的方式描述对象的依赖关系;
一个用xml配置的例子如下:
<beans>
<bean id = "pizzaController" class="..PizzaController" lazy-init="true"> //该bean为懒加载(详见下)
<constructor-args ref="pizzaSimpleFactory">
</bean>
<bean id = "pizzaSimpleFactory" class="..PizzaSimpleFactory"/ scope="prototype">
</beans>
该配置文件说明PizzaController这个类依赖于PizzaSimpleFactory这两个类,并需要通过构造器传入被依赖对象的引用;
而通过注解则更为直接:
public class PizzaController {
// 通过注解声明PizzaController类依赖于PizzaSimpleFactory类
@AutoWired
private PizzaSimpleFactory pizzaSimpleFactory;
}
如何读取、管理依赖关系
当以文件、代码或注解的方式定义bean的时候,这些依赖关系信息就存储在对应的位置,所以容器需要提供一个读取机制用于读取每一个容器需要管理的对象的依赖关系,并存储在与该对象唯一对应的一个数据对象中去(即BeanDefinition);
该读取机制由BeanDefinitionReader接口定义,并且对于不同的bean定义方式,Spring提供了不同的具体实现,对应xml方式的类为XmlBeanDefinitionReader;
容器通过BeanDefinitionReader读取到依赖信息后,还需要对读取到的BeanDefition进行保存管理,因而Spring抽象出BeanDefinitionRegistry()接口对依赖关系进行管理。
了解了上述两个步骤后,下面以读取xml为例,我们借用Spring源码中的单元测试类来讲述
class ComponentBeanDefinitionParserTests {
// DefaultListableBeanFactory类为BeanDefinitionRegistry的一个实现类
private final DefaultListableBeanFactory bf = new DefaultListableBeanFactory();
@BeforeAll
void setUp() throws Exception {
// 调用XmlBeanDefinitionReader类加载`component-config.xml`文件中的bean定义
// 并将该定义信息保存到beanfactory(bf)中
new XmlBeanDefinitionReader(bf).loadBeanDefinitions(new ClassPathResource(
"component-config.xml", ComponentBeanDefinitionParserTests.class));
}
}
上述步骤与我们上述分析的流程无异,这里不对Reader如何读取xml信息做解释,因为本文的重点在于通过分析Spring加载的过程,从而利用Spring框架提供给使用者的可扩展性。
然后看BeanDefition的定义,其本质是存储在xml或注解中定义的Bean信息:
public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement {
String SCOPE_SINGLETON = "singleton";
String SCOPE_PROTOTYPE = "prototype";
//省略部分代码...
void setParentName(@Nullable String var1); // 设置父类,如果有可以复用父类的定义
void setBeanClassName(@Nullable String var1);// xml中的class属性,提供信息给反射newInstance()
void setScope(@Nullable String var1);// xml中的定义的scope属性,默认为singleton
// xml中定义的是否懒加载
// 是否懒加载,懒加载即该Bean在容器初始化时不加载,而是在该对象需要被注入时再创建
void setLazyInit(boolean var1);
// 注意!这里便是我们在xml中定义的该bean所要依赖的对象的数组
void setDependsOn(@Nullable String... var1);
@Nullable
String[] getDependsOn();
// xml中自定义的<init-method>,初始化方法
void setInitMethodName(@Nullable String var1);
// xml中自定义的销毁方法
void setDestroyMethodName(@Nullable String var1);
}
至此我们知道了Spring容器加载并存储BeanDefinition的过程;
使用BeanDefition进行类的加载
上文我们通过Spring容器的两个职责简单分析了一下大概的实现方向,而Spring容器的状态也按照这两个职责分成了两个阶段:初始化BeanDefition阶段、实例化Bean阶段。
在Spring容器中,我们可以通过xml文件或注解+JavaConfig的方式向容器中注册相应的Bean,本文分析常见的后者在Spring IOC中的实现方式;
并在分析实现的过程中穿插解决下面几个问题:
Spring Bean生命周期与BeanFactoryPostProcessor、BeanPostProcessor这些处理器之间的关系 ;Spring默认的后置处理器是在什么时候通过什么方式注册到容器中的;Spring是如何解决缓存依赖问题的?- 我们了解了这个机制后我们可以做些什么?
初始化BeanDefition阶段
与通过直接xml文件获取BeanDefinition的方式不同,通过注解方式获取BeanDefinition要曲折一些。
首先我们需要将被@Configuration修饰的配置类放入AnnotationConfigApplicationContext中,然后Spring容器会将配置类的BeanDefinition通过register()方法注册到容器中,同时也会将Spring中自带的后置处理器的BeanDefinition注册到容器中,比较重要的有:
ConfigurationClassPostProcessor(implements BeanDefinitionRegistryPostProcessor)、AutowiredAnnotationBeanPostProcessor(implements SmartInstantiationAwareBeanPostProcessor)、CommonAnnotationBeanPostProcessor(implements InstantiationAwareBeanPostProcessor)…
看上去接口名眼花缭乱,但是其本质上是由两个接口-BeanFactoryPostProcessor、BeanPostProcessor发展而来的;
注意BeanFactoryPostProcessor与BeanPostProcessor区分开,前者是容器初始化层面,后者是Bean初始化层面。
如BeanFactoryPostProcessor 延展出(extends)两个接口-BeanDefinitionRegistryPostProcessor、 BeanFactoryPostProcessor,并且借助instanceof的特性赋予了子接口更高的优先级从而将Spring初始化BeanDefinition划分成两个阶段。
public interface BeanDefinitionRegistryPostProcessor extends BeanFactoryPostProcessor {
void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException;
}
public static void invokeBeanFactoryPostProcessors() {
// 遍历容器中所有的`BeanFactoryPostProcessor`接口实现类:
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
// 通过instanceof保证只有BeanDefinitionRegistryPostProcessor接口实现类优先执行
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor = (BeanDefinitionRegistryPostProcessor) postProcessor;
// 调用接口方法
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
} else {
regularPostProcessors.add(postProcessor);
}
}
// 省略部分代码
// 接着获取所有的BeanFactoryPostProcessor接口实现类并调用接口方法
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
...
}
}
由此可见Spring通过父子类接口的关系定义了接口的执行顺序从而实现了容器流程的阶段化;
同理,通过扩展BeanPostProcessor的子接口,如InstantiationAwareBeanPostProcessor(参与容器Bean实例化阶段)、BeanPostProcessor(参与容器Bean初始化阶段)等等接口从而实现了容器流程的阶段化。
通过BeanFactoryPostProcessor动态修改BeanDefition:
在初始化BeanDefition阶段,我们可以通过实现BeanFactoryPostProcessor接口达到动态修饰BeanDefition
@FunctionalInterface
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)
throws BeansException;
}
在平时编程中,比较常见的场景是我们配置诸如数据库相关Bean的属性时:
<!-- 数据源定义,使用Apache DBCP 连接池 -->
<bean id="dataSourceConfig"
class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="locations">
<list>
<value>classpath:config/jdbc.properties</value>
<value>file:${config.home}/jdbc.properties</value>
</list>
</property>
<property name="ignoreResourceNotFound" value="true"/>
</bean>
经常会出现${xxx}这类需要从jdbc.properties中获取的动态配置信息,而我们通过BeanDefitionReader类读取${xxx}的这个字符串并存储到BeanDefition中显然是无意义的,因此我们需要通过一个特定的BeanFactoryPostProcessor接口实现类用于读取jdbc.properties并遍历修改每个BeanDefition中的${}占位符。
代码如下:
通过抽象类PropertyResourceConfigurer实现BeanFactoryPostProcessor接口方法postProcessBeanFactory,在方法内部通过模板模式定义了处理properties的算法流程:
public abstract class PropertyResourceConfigurer extends PropertiesLoaderSupport
implements BeanFactoryPostProcessor, PriorityOrdered {
// @Param beanFactory,即需要修改BeanDefinition的当前容器实例
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
try {
Properties mergedProps = mergeProperties();
// Convert the merged properties, if necessary.
convertProperties(mergedProps);
// Let the subclass process the properties.
// 具体的处理占位符的方法由子类具体定义,主要定义了对于占位符的替换方法
processProperties(beanFactory, mergedProps);
}
catch (IOException ex) {
throw new BeanInitializationException("Could not load properties", ex);
}
}
}
通过动态修改容器层面的BeanDefition,我们可以实现Bean属性的动态替换,提高了代码的可扩展性、降低了耦合度。
构造Bean阶段
不管是FactoryBean还是ApplicationContext都是通过调用getBean()来实现对象的获取的,并且在第一次获取时getBean()会调用createBean()方法;不同的是前者是等对象创建再去get对象,而后者则是在容器初始化时便自动get对象了。
下文按照Bean的生命周期的发展,讲述整个Bean的实例化阶段:
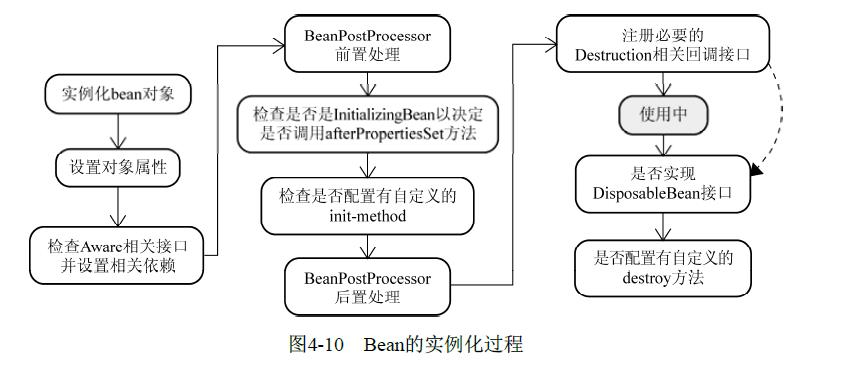 图片来自: 《Spring揭秘》
图片来自: 《Spring揭秘》
在这里只探讨非Web的Bean,即只有两个scope:singleton, prototype:
singleton:容器都只会创建一个对象(与单例模式不同,单例模式只能保证在同一个类加载器下加载一个实例对象),并且容器会持有该对象的引用,负责它的生命周期,一般情况下只有在容器销毁时才会注销;
prototype:容器可以创建多个对象,并且容器在创建完对象后便不再负责,而是由具体的调用者持有对象的引用并维护生命周期(值得注意的一点是,每个调用者在拿到一个对象引用后便一直在复用之前的引用,而不是每次都新生成一个);
实例化阶段
通过Spring容器依次在实例化Bean的过程中调用InstantiationAwareBeanPostProcessor接口的四个方法postProcessBeforeInstantiation()、postProcessAfterInstantiation()、postProcessProperties() / postProcessPropertyValues(),将Bean的实例化分成了四个阶段-开始实例化前、通过策略模式选择对应的构造器通过反射去实例化对象、完成实例化后、依赖对象注入;
我们通过分析Spring容器实现@AutoWired这种Field注入的方式来感受Bean的实例化过程,并一起分析一下Spring容器是如何解决属性循环依赖的问题;
PS:对象之间产生依赖的方式包括:构造器注入、属性注入,而Spring只可以解决属性注入的问题。
首先我们构造两个互相属性依赖的Service类,并通过配置类配置包扫描路径:
@Service
public class OrderService {
@Autowired
private UserService userService;
}
@Service
public class UserService {
@Autowired
private OrderService orderService;
}
@Configuration
@ComponentScan("study.service")
public class AppConfig {
}
public class MainApplication {
public static void main(String[] args) {
// 使用AnnotationConfigApplicationContext,并注入配置类
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
}
}
可以看到OrderService与UserService形成了一个ABA循环依赖问题,下面开始分析解决方法:
在AnnotationConfigApplicationContext容器启动时,容器会自动注册内部使用的一些BeanPostProcessor,其中就包括AutowiredAnnotationBeanPostProcessor,该后置处理器主要用于处理@AutoWired注解,当我们的对象已经完成实例化后,并且已经被postProcessAfterInstantiation()方法处理后,该对象进入实例化的最后阶段-属性注入,此处为Field Inject;
为了区分不同时间段的对象,Spring容器通过不同的Map对不同时期的对象进行存储:
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
网上经常将其称为三级缓存,是因为这三个map的注释都是以Cache of开头,但其本质还是为了区分不同时期的对象-对象通过构造器构造完成(singletonFactories)、对象属性注入完成(earlySingletonObjects)、对象初始化完成(singletonObjects),我们可以通过getSingleton()方法按照对象时期的优先级依次获取对象:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 1. 首先尝试获取已经初始化完成的对象
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 2. 未获取到时,则尝试获取已经属性注入完成的对象
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 3. 未获取到时,则尝试获取已经构造完成的对象
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
因而当Spring容器首先通过构造器构造了OrderService实例后,会将当前实例放入singletonFactories Map中, 接着进入到属性注入阶段时,Spring容器会调用AutowiredAnnotationBeanPostProcessor的postProcessProperties()方法进行依赖解析,运行过程中发现其对于UserService存在Field属性依赖,因此通过getBean()方法尝试获取该依赖对象,getBean()首先会调用getSingleton()方法,此时三个Map中自然是没有UserService对象的引用,因此需要通过调用getBean()方法进行UserService对象的生成;
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!
[Java架构群]
群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
UserService的生成同理,进入属性注入阶段时,Spring容器会通过AutowiredAnnotationBeanPostProcessor的postProcessProperties()方法进行依赖解析,发现其有属性依赖OrderService,因此亦会通过getBean() -> getSingleton()方法获取该依赖对象,因为此时singletonFactories Map中已经存在实例化后的OrderService引用,因而会直接进行返回并使得UserService的构建可以接着走下去而不被循环依赖所阻塞。
初始化阶段(对Bean进行修饰)
初始化阶段通过BeanPostProcessor接口的postProcessBeforeInitialization()、postProcessAfterInitialization()方法将Bean的初始化阶段拆分为初始化前、初始化中、初始化后三个阶段。
public interface BeanPostProcessor {
// BeanPostProcessor前置处理方法,初始化前调用
@Nullable
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
// BeanPostProcessor后置处理方法,初始化后调用
@Nullable
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
如在初始化前阶段:容器依次调用所有BeanPostProcessor接口实现类的postProcessBeforeInitialization()方法,如ApplicationContextAwareProcessor implements BeanPostProcessor类,当容器调用该实现类的postProcessBeforeInitialization()方法时,会查看该Bean是否有实现Aware接口,如果有则对Aware接口所对应的对象进行注入,如:该bean实现了ApplicationContextAware接口,则将当前容器实例的引用注入该Bean中;
我们日常编程中比较常用于介入Bean修饰阶段的方法有:
@PostConstruct:容器实例化Bean时会调用注册到容器中的、所有实现BeanPostProcessor接口的对象的postProcessBeforeInitialization做为对象实例化的前置处理方法;而在实例化存在被该注解修饰的Bean时,会调用CommonAnnotation-BeanPostProcessor中的前置处理方法,即我们在代码中自定义的被@PostConstrct修饰的方法;
InitializingBean:
public interface InitializingBean {
void afterPropertiesSet() throws Exception;
}
我们自己的业务类通过实现InitializingBean的接口方法,那么在容器设置完Bean的所有属性后,如果该Bean实现了InitializingBean接口,便会调用其afterPropertiesSet方法;
因此afterPropertiesSet方法是在postProcessBeforeInitialization之后调用的,而这也是Spring Bean的实例化过程的体现。
PS:特别的,在所有的非懒加载的Bean加载完成后,会调用所有实现SmartInitializingSingleton接口的Bean的afterSingletonsInstantiated()方法;
我们通过如下代码进行测试顺序:
@Component
public class InitMethodsList implements InitializingBean, SmartInitializingSingleton {
public void afterPropertiesSet() throws Exception {
System.out.println("initializingBean");
}
public void afterSingletonsInstantiated() {
System.out.println("smartInitializingSingleton");
}
@PostConstruct
public void postConstructMethod() {
System.out.println("CommonAnnotationBeanPostProcessor");
}
}
结果如下:
CommonAnnotationBeanPostProcessor -- Before Init 初始化前
afterPropertiesSet -- 初始化中,After Init之后
afterSingletonInstantiated -- 完成所有Bean的初始化之后
可以看到结果和上述初始化过程是相同的,在日常开发中使用这几种方式参与容器Bean的初始化时,需要注意执行的先后顺序,也可以利用其先后顺序进行有依赖的相关数据的初始化。
总结:
本文描述了Spring容器的两个主要职责,简要说明了实现方式;通过对容器的启动(初始化BeanDefinition)、Bean的初始化(通过BeanDefition进行Bean的实例化)这两个阶段的介绍,引入了如何利用Spring IOC框架提供的可自定义的空间。
最后
秃头哥给大家分享一篇一线开发大牛整理的java高并发核心编程神仙文档,里面主要包含的知识点有:多线程、线程池、内置锁、JMM、CAS、JUC、高并发设计
以上是关于分析Spring容器管理Bean的生命周期以及依赖关系的方式的主要内容,如果未能解决你的问题,请参考以下文章