应用层编解码调优思路——HTTP1.1和HTTP2以及编解码工具Protobuf
Posted 才浅的每日python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应用层编解码调优思路——HTTP1.1和HTTP2以及编解码工具Protobuf相关的知识,希望对你有一定的参考价值。
阿巩
她带着HTTP走来了!
现在带着你的答案看下去吧。日拱一卒,让我们开始吧!
为了大家更好的整理思路,今天分享的HTTP优化相关内容将围绕在HTTP诞生之初,对于其在应用层的5个精准定位展开,这也正是 REST 架构能够成功的关键。
基于TCP连接
采用请求-响应模式
低门槛的ASCII编码
无状态
信息安全交由TLS解决
首先是基于TCP连接,这意味着应用层无需关注如何可靠传输变长的消息,交由TCP处理即可;请求-响应模式使得客户端(client)及服务端(server)的开发变得简单;无状态的特性使得服务端更容易实现高可用;TLS协议相关的优化我们在上篇文章中已经阐述过了。
但随着网速提升,需求场景发生了很大变化。1 条消息的大小从最初几 K 增长为几兆,每个页面从小于 10 个资源到现在几百个资源,对页面内容的实时性要求也变得越来越高。
HTTP1.1最为人诟病的设计是笨重的头部,传输头部需要占用大量的带宽,再加之用ASCII编码的特性使得头部可达到几KB,而且滥用的 Cookie 头部进一步增大了体积,REST 架构无状态的特性还导致每次连接需要重传HTTP头部。
那对于HTTP1.1我们有什么优化思路呢?具体归纳为以下三点:
引入缓存
减少HTTP请求次数
减小资源体积
先来看缓存,缓存与网络效率密切相关,提到性能调优第一个想到的就是引入缓存,用好缓存是提升 HTTP 性能最重要的手段。具体方法是将第一次请求及其响应保存在客户端的本地磁盘上,用键值对的方式保存(URL: 响应),过程如图:
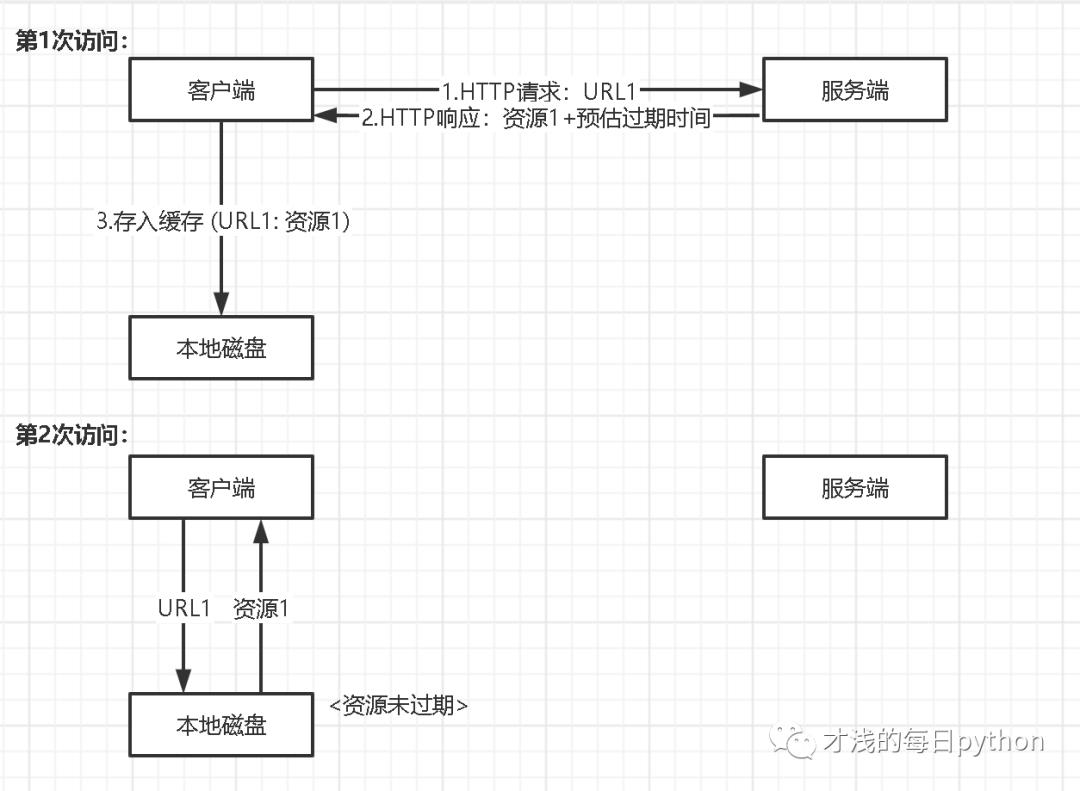
假如缓存过期了,过期后的缓存还能起到作用吗?
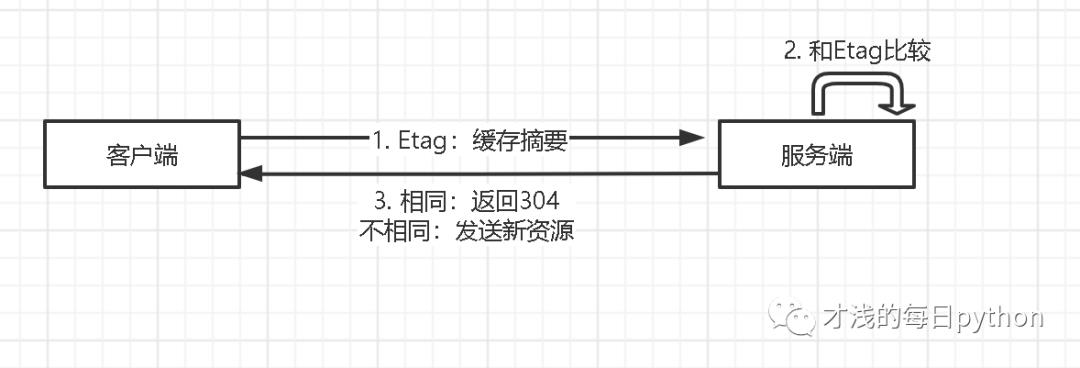
也会,如下图所示,当客户端发现缓存过期后,会取出缓存的摘要(摘要是从第 1 次请求的响应中拿到的),把它放在请求的 Etag 头部中再发给服务器,服务器将本地资源的摘要与请求中的 Etag 相比较,如果相同,返回304状态码告知客户端缓存仍有效;如果不同,重新发送最新资源即可。
(Etag文件摘要是一段字符串,比如在nginx中它是文件大小+修改时间形成的字符串。)
浏览器上的缓存称为私有缓存,当缓存放在代理服务器上被更多人使用就变为了共享缓存,它既可以放在正向代理也可以放在反向代理服务器上。
减少HTTP请求次数可以从三个角度入手:减少重定向次数、合并请求以及延迟发送请求。
首先减少重定向次数,可以将重定向工作交给代理服务器来做,而且我们可以缓存重定向到响应结果;合并请求主要是为了减少建立TCP连接和慢启动的代价,它将多个小文件合并为一个大文件;延迟发送请求可以使用懒加载技术。
减小资源体积包括使用无损和有损压缩两种形式,对于文本、二进制文件我们常用无损压损,而对于图片、音视频则使用有损压缩记录关键帧即可。
以上是对于HTTP1.1的优化思路,顺着这个思路我们来看看HTTP/2做了哪些优化,它对于H3又有什么可优化的点呢?
继续围绕文章开头提出的5个定位总结下HTTP/2优化的侧重点:
由于TCP不关注消息边界,应用层需要自己封装每条消息再传输;
请求-响应模式对TCP连接上消息的传输利用率极低,无法充分利用TCP全双工双向传输的特性,而且及时启用keep-Alive也需要等待对方响应(HTTP1.1后默认开启);
ASCII编码和传输效率较低;
无状态特性使得每次重发头部,空间利用率大大降低。
小延伸:这里的keep-Alive指应用层(用户态)的HTTP长连接,它与TCP(内核态)的KAlive保活机制不同。前者也就是本文中的keep-Alive指使用同一个HTTP连接发送和接收多个HTTP请求/应答,避免建立和释放连接的开销;后者用来回收空闲的TCP连接,释放服务器资源提升服务器性能,它是由Linux内核控制的。
HTTP/2采用静态表+动态表(合称HPACK)来降低HTTP头部体积。
首先基于二进制编码,不需要加入空格、冒号、\r\n作为分隔符,用表示长度的1个字节即可。HTTP/2用静态表描述Host头部,将高频头分别对应一个数字写死到HTTP/2框架代码中。这里用到了一个信息论的概念“高频出现的信息用较短编码表示后可压缩体积”。

客户端与服务器双方对于首次出现的HTTP头部,用相同的规则构建动态表,传输时只传数字即可。
对于HTTP/2支持并发传输请求,不同于HTTP1.1的拉模式,HTTP/2采用主动推送的推模式。这里先介绍下HTTP/2中出现的几个名词,为方便理解,以脑图方式呈现:
Frame是HTTP/2的最小实体,HTTP消息可以由多个Frame构成,一个Frame可以由多个TCP报文构成。
在 HTTP/2 连接上,理论上可以同时运行无数个 Stream,这就是 HTTP/2 的多路复用能力,它通过 Stream 实现了请求的并发传输。即“建立1次连接,实现100个并发Stream”,他按照资源渲染的优先级为并发Stream设置权重,再按权重划分内存和流量等资源。
HTTP/2最大问题来自于它下层的 TCP 协议,在前 1 字符未到达时,后接收到的字符只能存放在内核的缓冲区里,即使它们是并发的 Stream,应用层的 HTTP/2 协议也无法收到失序的报文,这就叫做队头阻塞问题。
解决方案是放弃 TCP 协议,转而使用 UDP 协议作为传输层协议,这就是 HTTP/3 协议的由来。
使用Protobuf编解码工具速度很快,消耗的 CPU 计算力也不多,而且编码后的字符流体积远远小于 JSON 等格式,能够大量节约昂贵的带宽,因此 gRPC 也把 Protobuf 作为底层的编解码协议。使用Protobuf 的编解码简言之就是把HTTP/2框架实现的字段名映射关系交由应用系统自行完成。对比来看json简化了XML,而Protobuf 优化了json的key部分。
参考:陶辉《系统性能调优必知必会》、《Web协议详解与抓包实战》
以上是关于应用层编解码调优思路——HTTP1.1和HTTP2以及编解码工具Protobuf的主要内容,如果未能解决你的问题,请参考以下文章