离开小厂进大厂的第一周,kafka连接数过多
Posted 努力编程进阶中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了离开小厂进大厂的第一周,kafka连接数过多相关的知识,希望对你有一定的参考价值。
Kafka 如何做到支持百万级 TPS ?
先用一张思维导图直接告诉你答案:
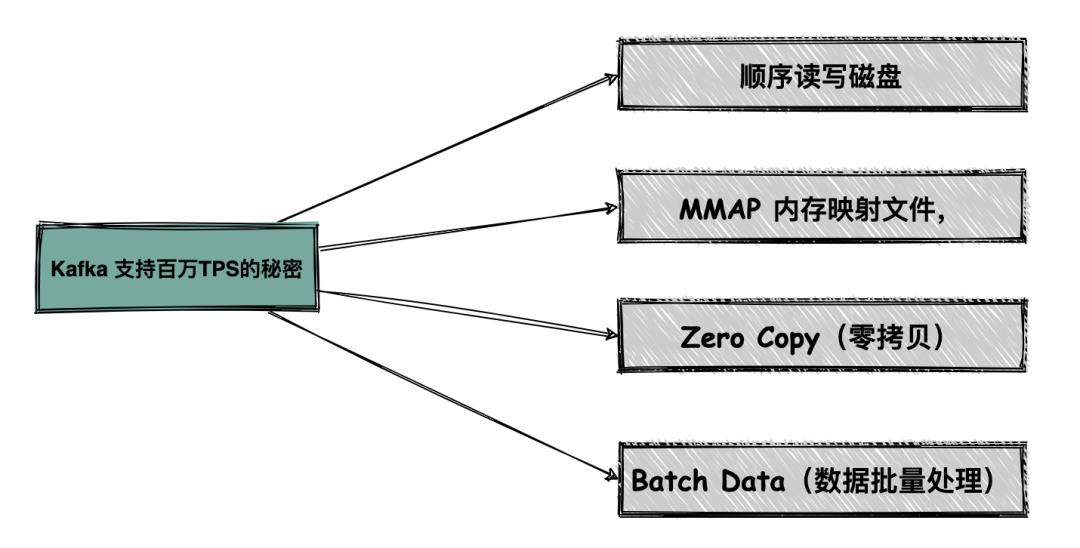
顺序读写磁盘
生产者写入数据和消费者读取数据都是顺序读写的,先来一张图直观感受一下顺序读写和随机读写的速度:
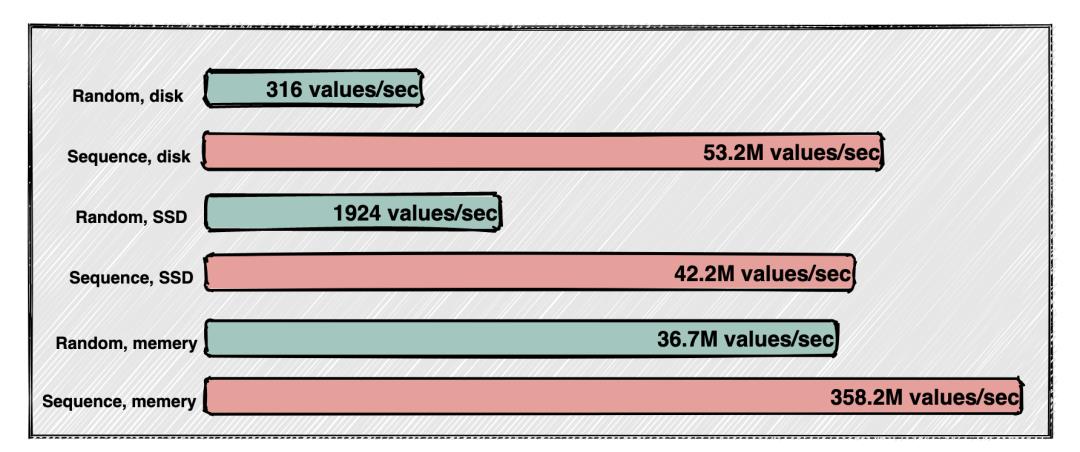
从图中可以看出传统硬盘或者SSD的顺序读写甚至超过了内存的随机读写,当然与内存的顺序读写对比差距还是很大。
所以Kafka选择顺序读写磁盘也不足为奇了。
下面以传统机械磁盘为例详细介绍一下什么是顺序读写和随机读写。
盘片和盘面:一块硬盘一般有多块盘片,盘片分为上下两面,其中有效面称为盘面,一般上下都有效,也就是说:盘面数 = 盘片数 * 2。
磁头:磁头切换磁道读写数据时是通过机械设备实现的,一般速度较慢;而磁头切换盘面读写数据是通过电子设备实现的,一般速度较快,因此磁头一般是先读写完柱面后才开始寻道的(不用切换磁道),这样磁盘读写效率更快。
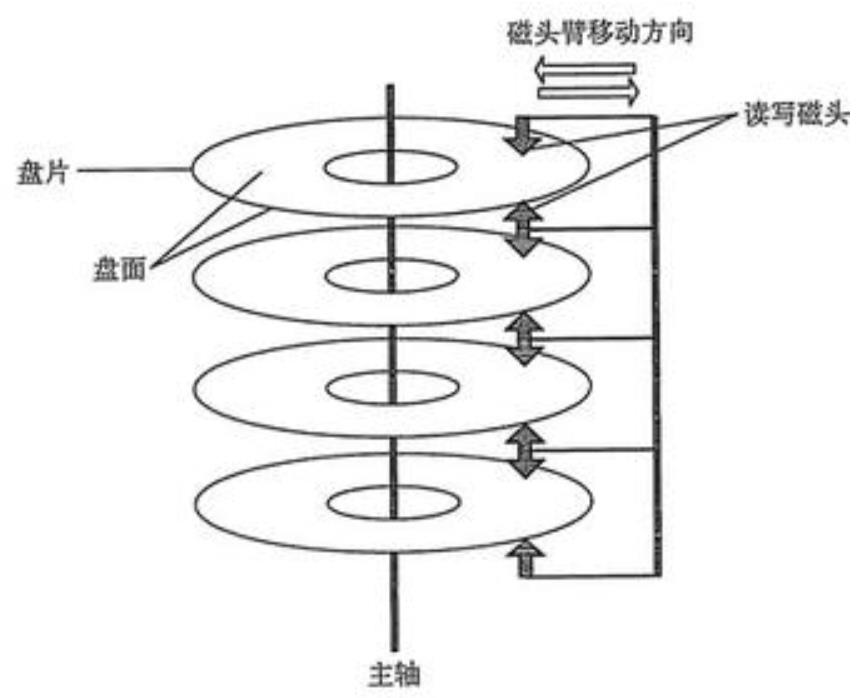
磁道:磁道就是以中间轴为圆心的圆环,一个盘面有多个磁道,磁道之间有间隙,磁道也就是磁盘存储数据的介质。磁道上布有一层磁介质,通过磁头可以使磁介质的极性转换为数据信号,即磁盘的读,磁盘写刚好与之相反。
柱面:磁盘中不同盘面中半径相同的磁道组成的,也就是说柱面总数 = 某个盘面的磁道数。
扇区:单个磁道就是多个弧形扇区组成的,盘面上的每个磁道拥有的扇区数量是相等。扇区是最小存储单元,一般扇区大小为512bytes。
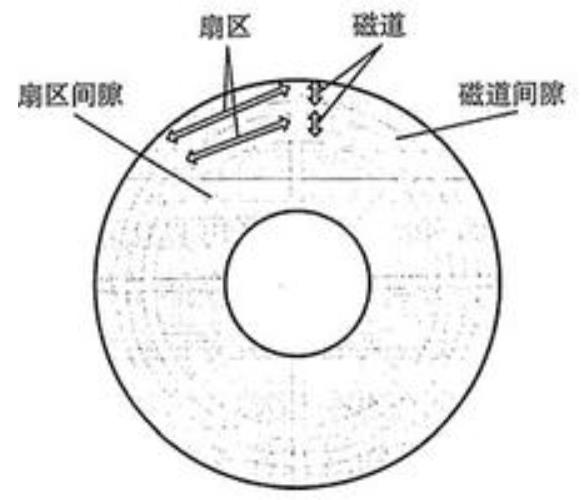
如果系统每次只读取一个扇区,那恐怕效率太低了,所以出现了block(块)的概念。文件读取的最小单位是block,根据不同操作系统一个block一般由多个扇区组成。
有了磁盘的背景知识我们就可以很容易理解顺序读写和随机读写了。
插播维基百科定义:顺序读写:是一种按记录的逻辑顺序进行读、写操作的存取方法 ,即按照信息在存储器中的实际位置所决定的顺序使用信息。 随机读写:指的是当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。
当读取第一个block时,要经历寻道、旋转延迟、传输三个步骤才能读取完这个block的数据。而对于下一个block,如果它在磁盘的其他任意位置,访问它会同样经历寻道、旋转、延时、传输才能读取完这个block的数据,我们把这种方式叫做随机读写。但是如果这个block的起始扇区刚好在刚才访问的block的后面,磁头就能立刻遇到,不需等待直接传输,这种就叫顺序读写。
好,我们再回到 Kafka,详细介绍Kafka如何实现顺序读写入数据。
Kafka 写入数据是顺序的,下面每一个Partition 都可以当做一个文件,每次接收到新数据后Kafka会把数据插入到文件末尾,虚框部分代表文件尾。
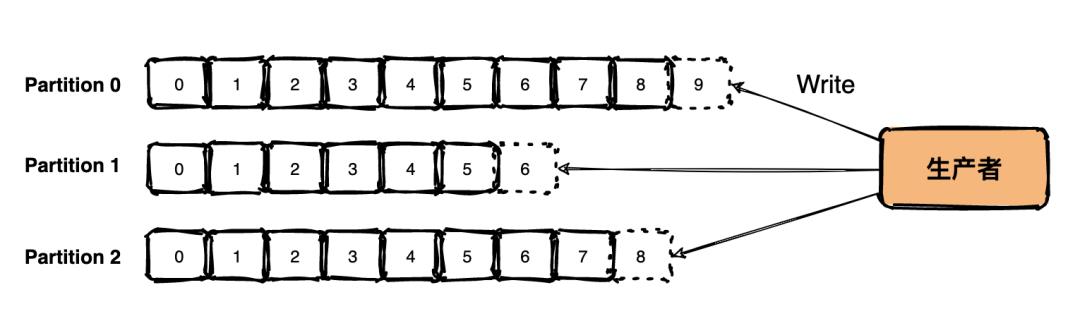
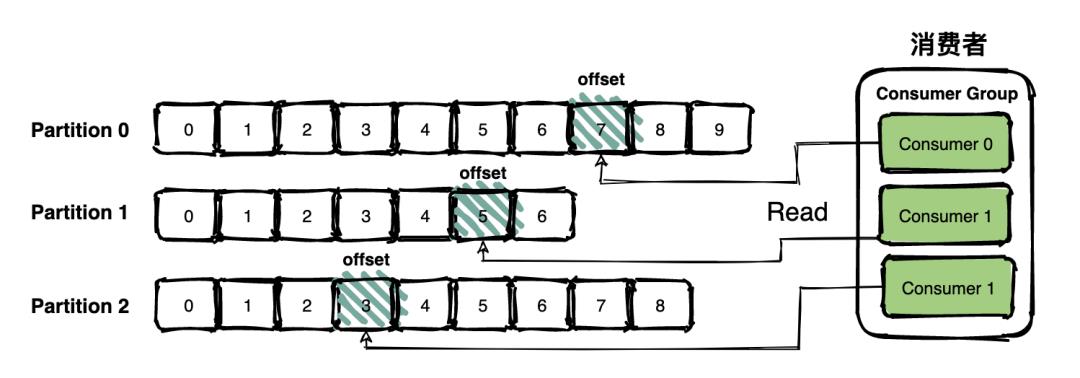
这种方法有一个问题就是删除数据不方便,所以 Kafka 一般会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个 offset 用来记录读取进度或者叫坐标。
Memory Mapped Files(MMAP)
在文章开头我们看到硬盘的顺序读写基本能与内存随机读写速度媲美,但是与内存顺序读写相比还是太慢了,那 Kafka 如果有追求想进一步提升效率怎么办?可以使用现代操作系统分页存储来充分利用内存提高I/O效率,这也是下面要介绍的 MMAP 技术。
MMAP也就是内存映射文件,在64位操作系统中一般可以表示 20G 的数据文件,它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射之后对物理内存的操作会被同步到硬盘上。
通过MMAP技术进程可以像读写硬盘一样读写内存(逻辑内存),不必关心内存的大小,因为有虚拟内存兜底。这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
也有一个很明显的缺陷,写到MMAP中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。
Kafka提供了一个参数:producer.type 来控制是不是主动 flush,如果Kafka写入到MMAP之后就立即flush然后再返回Producer叫同步(sync);写入MMAP之后立即返回Producer不调用flush叫异步(async)。
Zero Copy(零拷贝)
Kafka 另外一个黑技术就是使用了零拷贝,要想深刻理解零拷贝必须得知道什么是DMA。
什么是DMA?
众所周知 CPU 的速度与磁盘 IO 的速度比起来相差几个数量级,可以用乌龟和火箭做比喻。
一般来说 IO 操作都是由 CPU 发出指令,然后等待 IO 设备完成操作后返回,那CPU会有大量的时间都在等待IO操作。
但是CPU 的等待在很多时候并没有太多的实际意义,我们对于 I/O 设备的大量操作其实都只是把内存里面的数据传输到 I/O 设备而已。比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
基于此就有了DMA技术,翻译过来也就是直接内存访问(Direct Memory Access),有了这个可以减少 CPU 的等待时间。
Kafka 零拷贝原理
如果不使用零拷贝技术,消费者(consumer)从Kafka消费数据,Kafka从磁盘读数据然后发送到网络上去,数据一共发生了四次传输的过程。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。
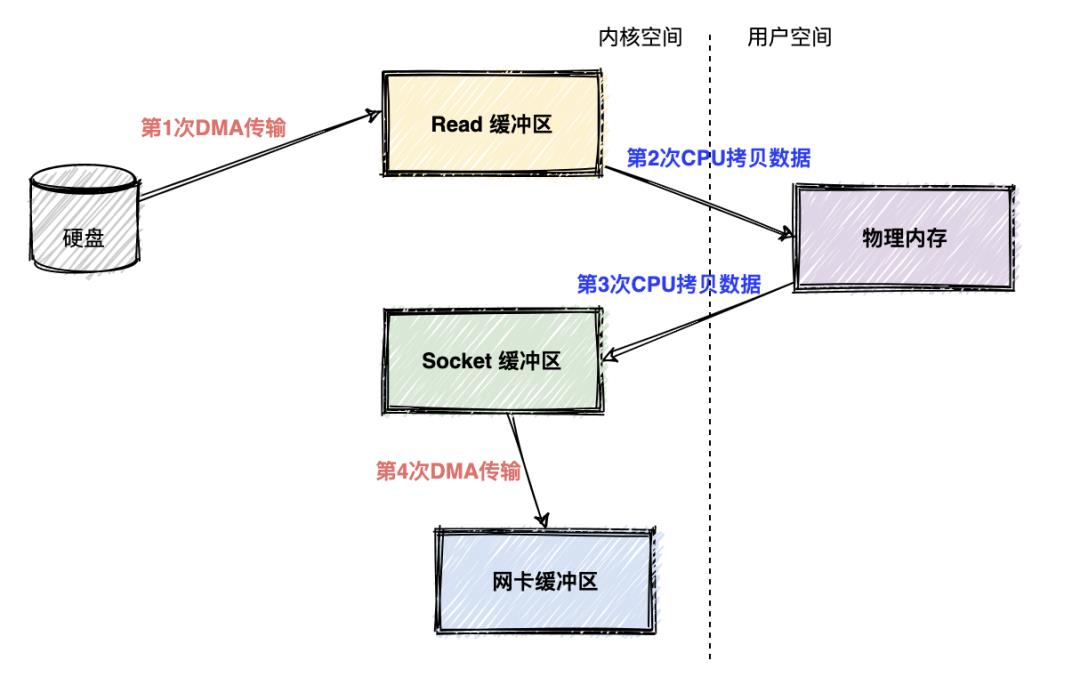
第一次传输:从硬盘上将数据读到操作系统内核的缓冲区里,这个传输是通过 DMA 搬运的。
第二次传输:从内核缓冲区里面的数据复制到分配的内存里面,这个传输是通过 CPU 搬运的。
第三次传输:从分配的内存里面再写到操作系统的 Socket 的缓冲区里面去,这个传输是由 CPU 搬运的。
第四次传输:从 Socket 的缓冲区里面写到网卡的缓冲区里面去,这个传输是通过 DMA 搬运的。
实际上在kafka中只进行了两次数据传输,如下图:
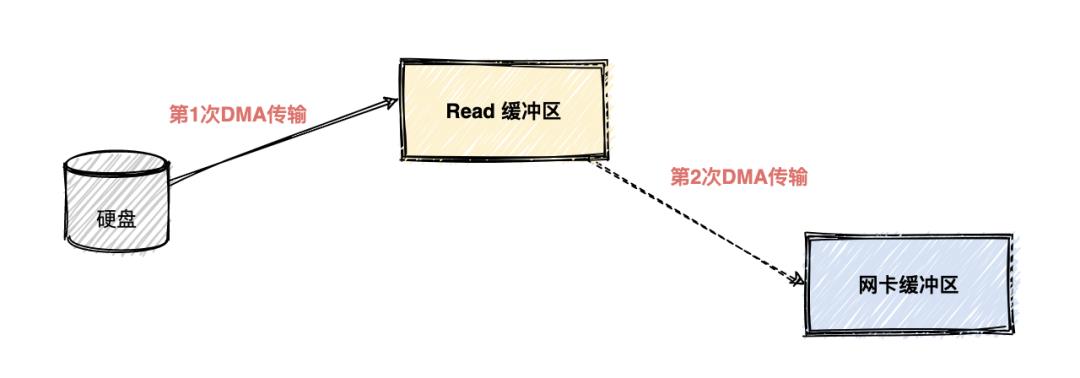
第一次传输:通过 DMA从硬盘直接读到操作系统内核的读缓冲区里面。
第二次传输:根据 Socket 的描述符信息直接从读缓冲区里面写入到网卡的缓冲区里面。
我们可以看到同一份数据的传输次数从四次变成了两次,并且没有通过 CPU 来进行数据搬运,所有的数据都是通过 DMA 来进行传输的。没有在内存层面去复制(Copy)数据,这个方法称之为零拷贝(Zero-Copy)。
无论传输数据量的大小,传输同样的数据使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量,这也是Kafka能够支持百万TPS的一个重要原因。
Batch Data(数据批量处理)
当消费者(consumer)需要消费数据时,首先想到的是消费者需要一条,kafka发送一条,消费者再要一条kafka再发送一条。但实际上 Kafka 不是这样做的,Kafka 耍小聪明了。
Kafka 把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候 Kafka 直接把文件发送给消费者。比如说100万条消息放在一个文件中可能是10M的数据量,如果消费者和Kafka之间网络良好,10MB大概1秒就能发送完,既100万TPS,Kafka每秒处理了10万条消息。
看到这里你可以有疑问了,消费者只需要一条消息啊,kafka把整个文件都发送过来了,文件里面剩余的消息怎么办?不要忘了消费者可以通过offset记录消费进度。
发送文件还有一个好处就是可以对文件进行批量压缩,减少网络IO损耗。
最后
这份文档从构建一个键值数据库的关键架构入手,不仅带你建立起全局观,还帮你迅速抓住核心主线。除此之外,还会具体讲解数据结构、线程模型、网络框架、持久化、主从同步和切片集群等,帮你搞懂底层原理。相信这对于所有层次的Redis使用者都是一份非常完美的教程了。

快速入手通道:(戳这里,免费下载)诚意满满!!!
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!
载](https://docs.qq.com/doc/DSmxTbFJ1cmN1R2dB))诚意满满!!!**
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!
以上是关于离开小厂进大厂的第一周,kafka连接数过多的主要内容,如果未能解决你的问题,请参考以下文章