真是恍然大悟啊!dockermacos实现及原理
Posted 专业教学分布式
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了真是恍然大悟啊!dockermacos实现及原理相关的知识,希望对你有一定的参考价值。
一、面试官考点之索引是什么?
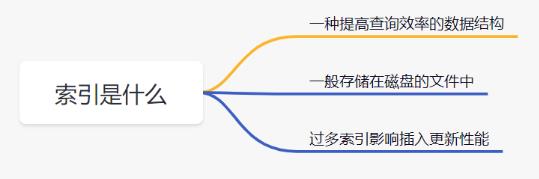
- 索引是一种能提高数据库查询效率的数据结构。它可以比作一本字典的目录,可以帮你快速找到对应的记录。
- 索引一般存储在磁盘的文件中,它是占用物理空间的。
- 正所谓水能载舟,也能覆舟。适当的索引能提高查询效率,过多的索引会影响数据库表的插入和更新功能。
二、索引有哪些类型类型
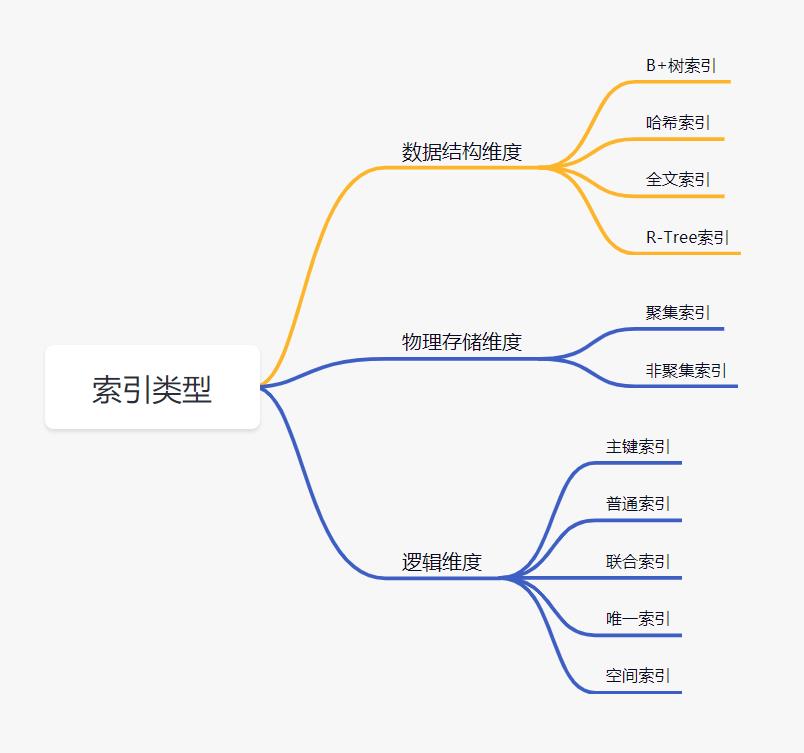
数据结构维度
- B+树索引:所有数据存储在叶子节点,复杂度为O(logn),适合范围查询。
- 哈希索引: 适合等值查询,检索效率高,一次到位。
- 全文索引:MyISAM和InnoDB中都支持使用全文索引,一般在文本类型char,text,varchar类型上创建。
- R-Tree索引: 用来对GIS数据类型创建SPATIAL索引
物理存储维度
- 聚集索引:聚集索引就是以主键创建的索引,在叶子节点存储的是表中的数据。
- 非聚集索引:非聚集索引就是以非主键创建的索引,在叶子节点存储的是主键和索引列。
逻辑维度
- 主键索引:一种特殊的唯一索引,不允许有空值。
- 普通索引:mysql中基本索引类型,允许空值和重复值。
- 联合索引:多个字段创建的索引,使用时遵循最左前缀原则。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值。
- 空间索引:MySQL5.7之后支持空间索引,在空间索引这方面遵循OpenGIS几何数据模型规则。
三、面试官考点之为什么选择B+树作为索引结构
可以从这几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数等等。为什么不是哈希结构?为什么不是二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是B+树呢?
我们写业务SQL查询时,大多数情况下,都是范围查询的,如下SQL
select * from employee where age between 18 and 28;
为什么不使用哈希结构?
我们知道哈希结构,类似k-v结构,也就是,key和value是一对一关系。它用于等值查询还可以,但是范围查询它是无能为力的哦。
为什么不使用二叉树呢?
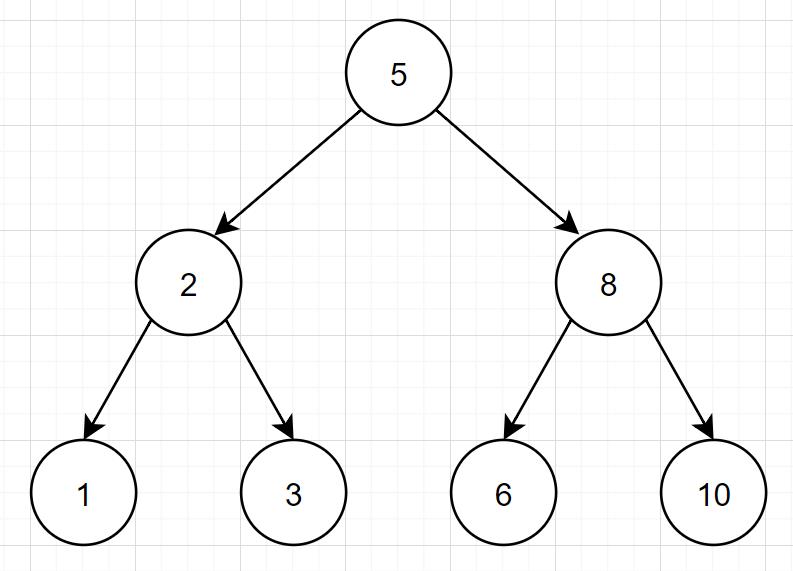
先回忆下二叉树相关知识啦~ 所谓二叉树,特点如下:
- 每个结点最多两个子树,分别称为左子树和右子树。
- 左子节点的值小于当前节点的值,当前节点值小于右子节点值
- 顶端的节点称为根节点,没有子节点的节点值称为叶子节点。
我们脑海中,很容易就浮现出这种二叉树结构图:
但是呢,有些特殊二叉树,它可能这样的哦:
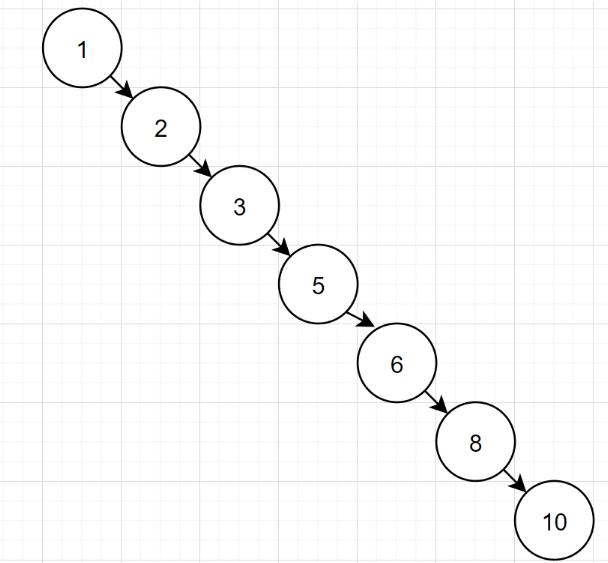
如果二叉树特殊化为一个链表,相当于全表扫描。那么还要索引干嘛呀?因此,一般二叉树不适合作为索引结构。
为什么不使用平衡二叉树呢?
平衡二叉树特点:它也是一颗二叉查找树,任何节点的两个子树高度最大差为1。所以就不会出现特殊化一个链表的情况啦。
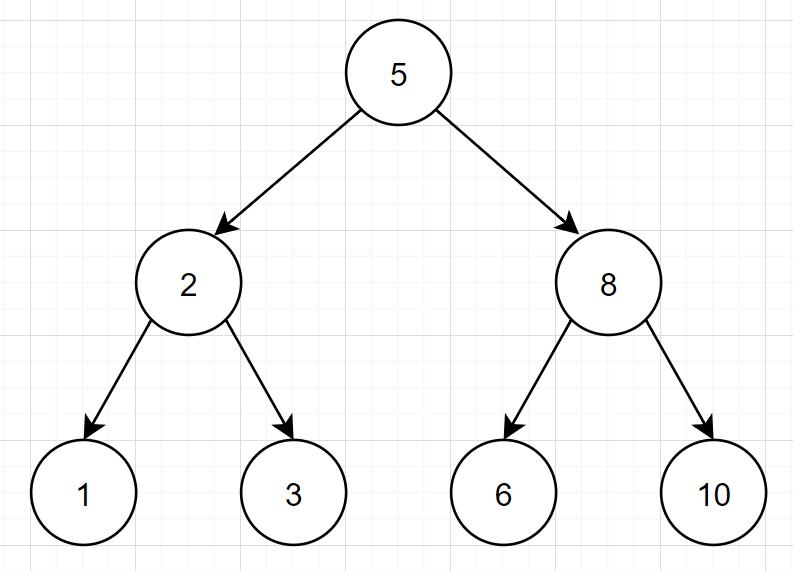
但是呢:
- 平衡二叉树插入或者更新是,需要左旋右旋维持平衡,维护代价大
- 如果数量多的话,树的高度会很高。因为数据是存在磁盘的,以它作为索引结构,每次从磁盘读取一个节点,操作IO的次数就多啦。
为什么不使用B树呢?
数据量大的话,平衡二叉树的高度会很高,会增加IO嘛。那为什么不选择同样数据量,高度更矮的B树呢?
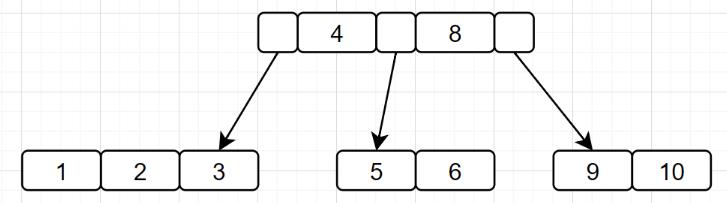
B树相对于平衡二叉树,就可以存储更多的数据,高度更低。但是最后为甚选择B+树呢?因为B+树是B树的升级版:
- B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
- B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
最后
金三银四到了,送上一个小福利!
147354464)]
[外链图片转存中…(img-RZzIPGQO-1625147354465)]
[外链图片转存中…(img-4E8MJJL6-1625147354466)]
以上是关于真是恍然大悟啊!dockermacos实现及原理的主要内容,如果未能解决你的问题,请参考以下文章